
[특강] 기업리뷰 분석 1
기업리뷰 수집
Dr.Kevin 10/25/2018
여러분은 취업에 대한 관심이 상당히 많을 것이라 생각합니다. 저는 여러 대기업 금융회사에서만 16년 넘게 근무했습니다. 여러분 입장에서는 대기업 금융회사가 겉으로 보기에는 아주 좋은 직장일 것이라 생각할 것 같습니다. 저도 대학원을 졸업하고 취업을 준비하던 시기에 삼성 금융계열사에서 돈을 많이 준다는 말에 솔깃했으니까요.
그런데 제가 직장생활을 해보니 좋은 회사, 나쁜 회사로 구분하는 것보다는 나와 맞는 회사와 맞지 않는 회사로 구분하는 편이 낫겠다는 생각을 가지게 되었습니다. 크게 3가지로 구분하자면, 회사의 조직문화와 담당하게 될 직무, 그리고 함께 일하게 될 동료(라고 쓰여 있지만 직장상사로 바꿔 읽으면 됩니다).
취업을 할 때 담당할 직무가 결정되어 있을 수도 있지만 그렇지 않은 경우도 많을 것입니다. 하지만 함께 일할 동료는 여러분이 전혀 알 수가 없겠죠? 어렵사리 취업을 했는데 막상 회사를 다녀봐야 자신과 맞는지 안맞는지 그 때 가서야 알 수 있을 겁니다. 주변의 사람들, 그러니까 학교 선배나 어른들 말씀을 들어보면 제각각일 가능성이 높습니다. 그 이유는 각자가 경험한 내용이 제각각이기 때문입니다. 제가 여러분께 드리는 이 말씀도 마찬가지구요.
결국 여러분은 제한된 정보만을 가지고 취업 시장에 문을 두드려야 할 것입니다. 그나마 회사만 겨우 선택할 수 있을지도 모릅니다. 왜냐하면 회사에 입사한 이후에 담당하게 될 직무가 결정될 수 있고 함께 일할 사수는 물론, 과장님, 차장님, 부장님 등 선배 동료들이 어떤 분들일지는 그야말로 며느리도 모르는 상황이 될 것이기 때문입니다.
그래서 자신이 관심있는 회사가 있다면, 그 회사를 미리 경험했던 인생 선배들의 주관적인 기업리뷰를 수집해서 분석해보는 건 어떨까요? 조금이나마 도움이 되지 않을까요? 아무튼 오늘 제가 여러분께 드릴 수 있는 것은 특정 회사에 대한 리뷰를 어떻게 분석하면 좋을지에 대하여 제 나름의 방법을 제시하는 것입니다. 제가 소개하는 방법은 절대로 정답이 아니니 여러분께서 원하는 내용을 추가하시면 더욱 훌륭한 분석 결과가 될 겁니다. 그럼 시작해볼까요?
데이터 수집
데이터 분석에서 가장 중요한 것은 데이터입니다. 양질의 데이터면 좋겠죠? 일단 품질을 알 수 없으니 그 점은 차치하고 온라인 상에서 수집할 수 있는 기업리뷰를 찾아보도록 합시다. 다행하게도 잡플래닛이라는 스타트업이 기업리뷰를 공유하고 있습니다. 사실 이 데이터의 품질에 문제를 제기하는 사람들이 좀 있습니다. 예를 들어, 기업리뷰를 남기는 회원이 그 회사에서 근무한 경험이 있는지 확인하는 절차를 거치지 않는다는 것이 있구요. 또 다른 하나는 인사팀 직원이 긍정적인 리뷰를 남기는 리스크도 있다는 것입니다. 하지만 대수의 법칙을 믿어봅시다. 비록 주관적이지만 여러 회원이 작성한 기업리뷰에는 공통점이 있을테니까요.
우리는 잡플래닛의 기업리뷰 데이터를 수집할 것입니다. 그런데 한 가지 문제가 더 있습니다. 잡플래닛은 어떤 회사에 대한 기업리뷰를 작성한 회원에게만 다른 회사의 기업리뷰를 조회할 수 있도록 한다는 것입니다. 그러므로 기업리뷰를 조회하려면 로그인을 한 상태여야 합니다. 로그인을 한 상태로 웹 크롤링하는 방법은 크게 2가지가 있는데 하나는 쿠키를 이용하는 것이고, 또 다른 하나는 RSelenium을 이용하는 것입니다. 이번 프로젝트에서는 쿠키를 이용하는 방법을 사용할 것입니다. 저의 아이디와 비밀번호로 쿠키를 얻을 것인데요. 당연하게도 저의 로그인 정보는 공개하지 않을 것이므로 만약 여러분게서 이 포스팅을 스스로 따라해보려고 한다면 잡플래닛에 회원가입을 하시고, 기업리뷰를 작성한 후에 하시기 바랍니다.
크롬 개발자도구를 활용하여 HTTP 요청 정보 확인하기
잡플래닛에 접속하면 다음과 같이 메인 화면이 열립니다.
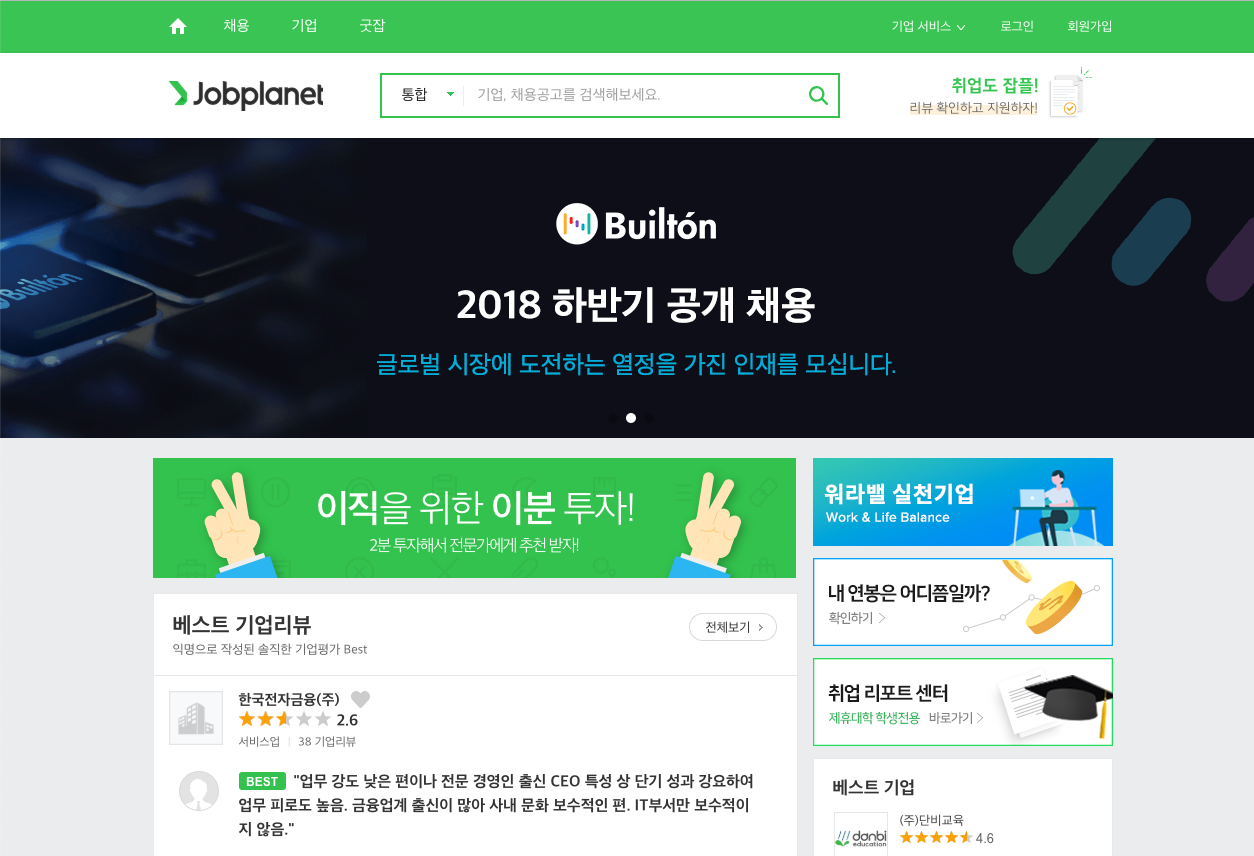
아직 로그인하기 전이므로 오른쪽 상단에 로그인이라는 메뉴가 보입니다. 로그인 메뉴를 클릭해서 로그인 화면이 열리면 크롬 개발자도구를 엽니다. 화면 아무 곳에서나 마우스 오른쪽 버튼을 누르면 메뉴 팝업이 뜨는데 그 중 하단의 검사(Inspect)를 클릭하면 크롬 개발자도구가 열립니다. Network 탭으로 이동한 다음 Preserve log 앞에 있는 라디오버튼을 체크하면 로그인할 준비가 끝났습니다. 이 작업을 하는 이유는, 로그인이 진행될 때 어떤 과정을 거치는지 확인하기 위함입니다. 이제 아이디와 비밀번호를 입력해서 로그인합니다. 그러면 크롬 개발자도구에서 아래와 같은 내용이 보일 것입니다.
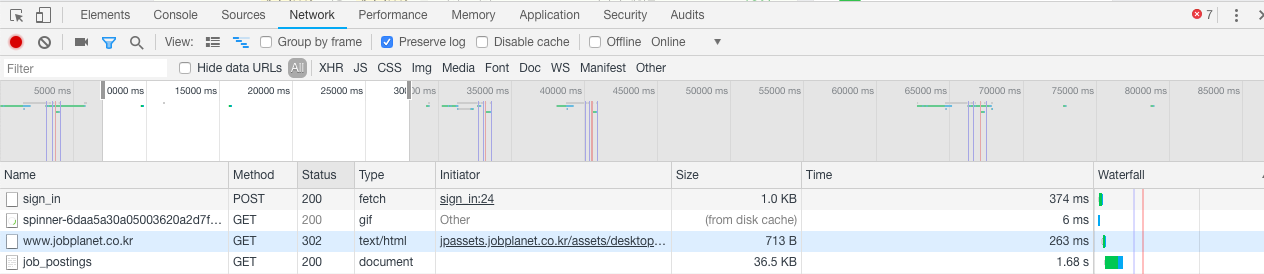
화면 하단에서 Name의 첫 번째 항목이 Sign_in이며, POST 방식으로 HTTP 요청을 하였습니다. 주의하셔야 할 점은 로그인하기 전에 Preserve log 버튼을 체크하지 않으면 이 내용이 보이지 않습니다. 이제 Sign_in 항목을 클릭하여 상세내용을 확인해볼까요?

Headers탭에는 크게 4가지가 보이는데요. 가장 처음 항목인 General은 HTTP 요청과 응답에서 공통으로 사용되는 내용이 보입니다. 우리는 여기에서 Request URL만 복사할 것입니다. 그리고 마우스로 화면을 맨 마지막으로 이동시킵니다. Request Payload에서 우리가 로그인할 때 사용한 아이디와 비밀번호가 보입니다. 즉, HTTP 요청을 할 때 email과 password의 인자로 아이디와 비밀번호를 지정해주는 것입니다.
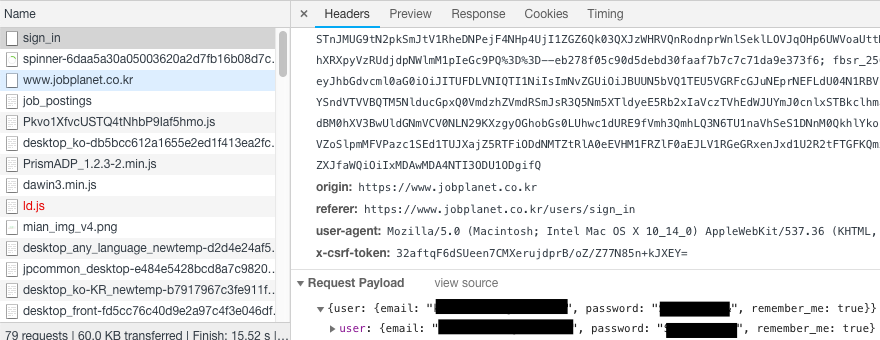
여기까지 잘 따라왔나요? 이제 HTTP 요청을 할 때 로그인 정보를 함께 보낸 후 쿠키를 얻을 준비 과정이 끝났습니다. 이 쿠키를 이용하면 로그인 상태로 웹 페이지 이동이 가능하므로 기업리뷰 데이터를 수집할 수 있게 됩니다. 그런데 만약 여러분이 웹 크롤링 경험이 없거나 익숙하지 않다면 지금까지의 설명을 전혀 이해하지 못할 수 있습니다. 웹 크롤링은 관련 내용에 대한 공부도 필요하지만 경험도 필요하기 때문입니다. 이번 기회로 웹 크롤링에 관심이 생겼다면 공부해보시기 바랍니다.
이제 R코드를 이용하여 웹 데이터를 수집해보겠습니다.
# 필요한 라이브러리를 불러옵니다.
library(httr)
library(rvest)
library(tidyverse)
# 로그인 화면의 URI를 복사하여 URI 객체에 지정합니다.
URI <- 'https://www.jobplanet.co.kr/users/sign_in'
# 로그인 정보를 이용하여 HTTP 요청을 합니다.
resp <- POST(url = URI,
body = list('user[email]' = '본인의 아이디를 입력합니다',
'user[password]' = '본인의 비밀번호를 입력합니다'))
# 응답 상태코드를 확인합니다. 200이면 정상입니다.
status_code(x = resp)
## [1] 200
# 쿠키만 수집하여 myCookies 객체에 할당합니다.
# 앞으로 HTTP 요청할 때 myCookies를 활용하면 로그인 상태로 HTML을 받을 수 있습니다.
myCookies <- set_cookies(.cookies = unlist(x = cookies(x = resp)))
참고로 myCookies는 결과가 출력되지 않도록 설정했습니다. 실습을 하면서 직접 확인하시기 바랍니다.
특정 회사의 기업리뷰 수집하기
여러분은 어떤 회사에 대해 관심이 많은가요? 이번 예제에서는 저의 첫 번째 직장인 삼성화재로 정했습니다. 잡플래닛 메인 페이지에서 탐색창에 삼성화재를 조회해보면 다음과 같은 화면이 열립니다.
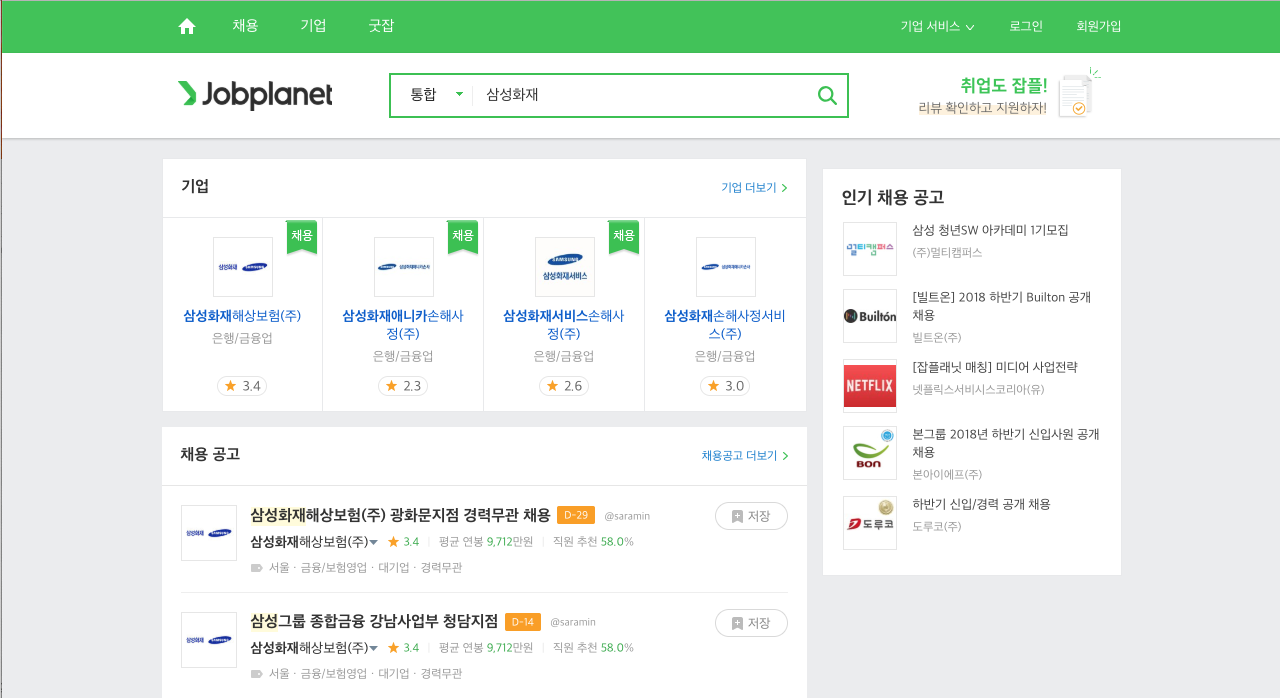
화면 상단에 회사 아이콘이 4개 보입니다. 그 중에서 첫 번째 아이콘을 클릭하면 새로운 화면이 열리면서 아래 그림과 같이 삼성화재의 기업리뷰 평균 점수를 조회할 수 있습니다.
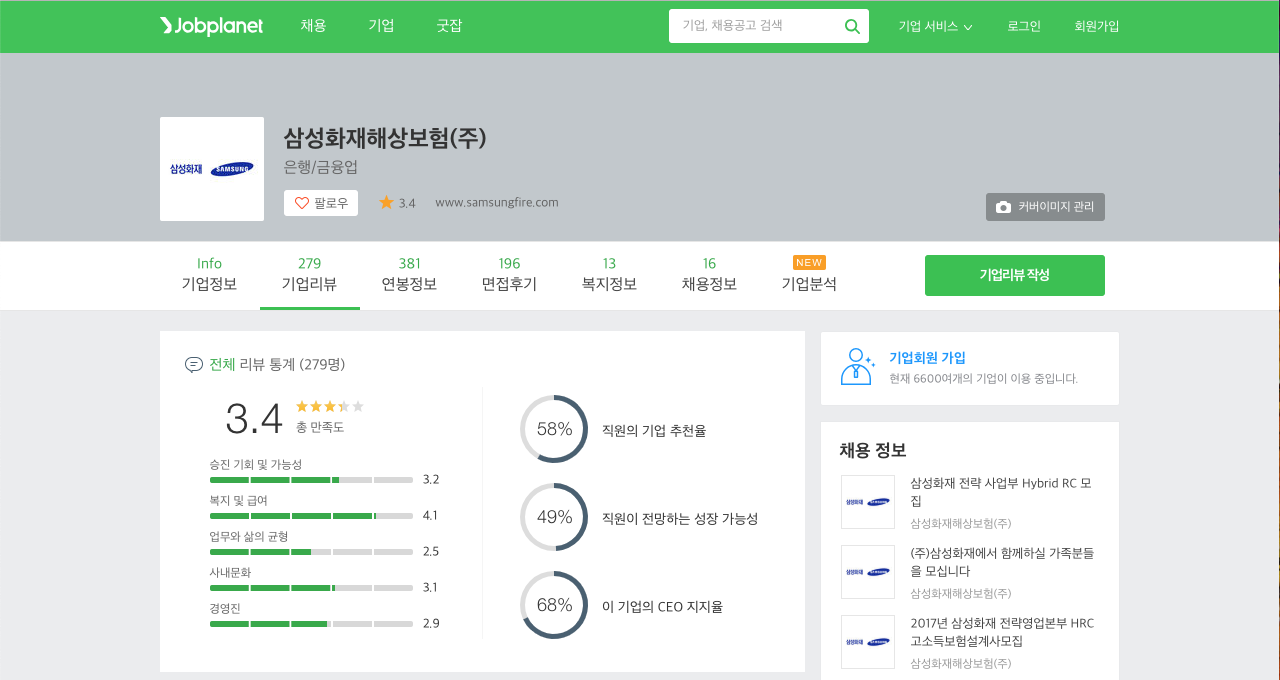
마우스를 조금 내리면 개별 기업리뷰를 확인할 수 있습니다. 지금 보이는 이미지는 로그인하기 전의 웹 페이지이지만 만약 기업리뷰를 작성했다면 로그인했을 때 기업리뷰 텍스트 데이터가 화면에 표시됩니다.
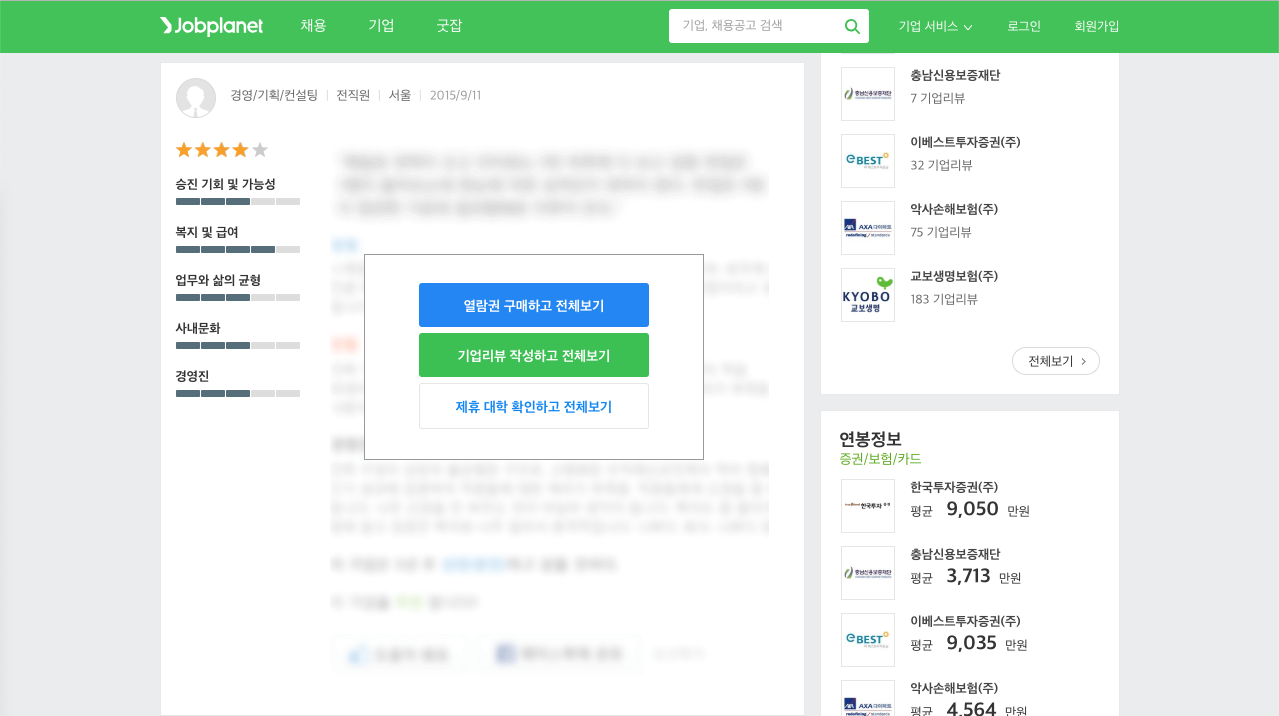
우리는 쿠키를 가지고 있으므로 따로 로그인하지 않아도 텍스트 데이터를 수집할 수 있습니다. 이제 개별 기업리뷰 데이터를 수집에 앞서 기업리뷰 수를 가져오겠습니다.
# 수집할 기업명을 지정합니다.
compNm <- '삼성화재해상보험'
# 잡플래닛 웹 페이지에서 삼성화재 기업리뷰를 확인할 수 있는 URI을 복사하여 붙입니다.
# 분명 웹 브라우저에서는 '삼성화재해상보험'이라고 한글로 보였을 것입니다.
# 그런데 RStudio로 붙여넣기 하면 이상한 코드로 바뀝니다. 이것은 'URL인코딩'입니다.
# 한글은 사람이 읽을 수 있지만 컴퓨터는 읽지 못하므로 컴퓨터가 읽을 수 있도록 변환해준 것입니다.
URI <- 'https://www.jobplanet.co.kr/companies/30056/reviews/%EC%82%BC%EC%84%B1%ED%99%94%EC%9E%AC%ED%95%B4%EC%83%81%EB%B3%B4%ED%97%98'
# 쿠키를 이용하여 로그인 상태 가장하여 HTTP 요청을 합니다.
resp <- GET(url = URI, config = list(cookies = myCookies))
# 응답 상태코드를 확인합니다.
status_code(x = resp)
## [1] 200
# 기업리뷰 수를 추출합니다. (2018년 10월 25일 기준 : 279건)
# 아래 코드에서 CSS Selector를 확인하려면 크롬 개발자도구를 이용해야 합니다.
# 이 과정을 설명하려면 내용이 길어지므로 이번 포스팅에서는 생략합니다.
reviewCnt <- resp %>%
read_html() %>%
html_nodes(css = 'li.viewReviews > a > span.num.notranslate') %>%
html_text() %>%
as.numeric()
# 결과를 출력합니다.
print(x = reviewCnt)
## [1] 279
현재 웹 브라우저에는 5개의 개별 기업리뷰가 표시되어 있을 것입니다. 이 내용을 모두 수집해보겠습니다. CSS Selector를 확인하는 방법은 생략합니다. 양해 바랍니다.
# 잡플래닛에 저장된 회사이름을 추출합니다.
resp %>% read_html() %>% html_node(css = 'h2.tit') %>% html_text()
## [1] "삼성화재해상보험(주)"
# 기업리뷰가 포함된 가장 상위의 HTML 요소를 지정합니다. (5개만 추출됨)
items <- resp %>% read_html() %>% html_nodes(css = 'section.content_ty4')
length(x = items)
## [1] 5
# 회사코드와 리뷰코드를 추출합니다. (잡플래닛에서 부여)
items %>% html_attr(name = 'data-company_id')
## [1] "30056" "30056" "30056" "30056" "30056"
items %>% html_attr(name = 'data-content_id')
## [1] "849559" "847215" "847067" "846461" "840800"
# 개별 기업리뷰 상단에 있는 직종구분, 재직상태, 근무지역, 등록일자를 추출합니다.
items %>% html_nodes(css = 'div.content_top_ty2 span:nth-child(2)') %>% html_text()
## [1] "금융/재무" "영업/제휴" "금융/재무" "인사/총무" "IT/인터넷"
items %>% html_nodes(css = 'div.content_top_ty2 span:nth-child(4)') %>% html_text()
## [1] "현직원" "전직원" "전직원" "전직원" "현직원"
items %>% html_nodes(css = 'div.content_top_ty2 span:nth-child(6)') %>% html_text()
## [1] "서울" "서울" "서울" "서울" "서울"
items %>% html_nodes(css = 'div.content_top_ty2 span.txt2') %>% html_text()
## [1] "2018/10/16" "2018/10/14" "2018/10/14" "2018/10/14" "2018/10/9"
# 개별 기업리뷰 왼쪽에 있는 별점(총점, 승진기회, 복지급여, 워라밸, 사내문화, 경영진)을 추출합니다.
# 꺽쇠 사이에 텍스트로 존재하는 대신 HTML 요소의 속성값으로 존재하고 있으며,
# 'width:100%'와 같은 형태이므로 나중에 정규식을 활용하여 숫자만 추출해야 합니다.
items %>% html_nodes(css = 'div.star_score') %>% html_attr(name = 'style')
## [1] "width:80%;" "width:20%;" "width:60%;" "width:100%;" "width:80%;"
items %>% html_nodes(css = 'dl dd:nth-child(3) div div') %>% html_attr(name = 'style')
## [1] "width:80%;" "width:60%;" "width:40%;" "width:80%;" "width:80%;"
items %>% html_nodes(css = 'dl dd:nth-child(5) div div') %>% html_attr(name = 'style')
## [1] "width:100%;" "width:100%;" "width:80%;" "width:100%;" "width:100%;"
items %>% html_nodes(css = 'dl dd:nth-child(7) div div') %>% html_attr(name = 'style')
## [1] "width:60%;" "width:20%;" "width:40%;" "width:80%;" "width:80%;"
items %>% html_nodes(css = 'dl dd:nth-child(9) div div') %>% html_attr(name = 'style')
## [1] "width:80%;" "width:20%;" "width:60%;" "width:100%;" "width:80%;"
items %>% html_nodes(css = 'dl dd:nth-child(11) div div') %>% html_attr(name = 'style')
## [1] "width:80%;" "width:20%;" "width:60%;" "width:100%;" "width:80%;"
# 개별 기업리뷰 오른쪽에 있는 내용(장점, 단점, 바라는점, 성장예상, 추천여부)을 추출합니다.
items %>% html_nodes(css = 'dl dd:nth-child(2) span') %>% html_text()
## [1] "그룹 인센티브(흔히 PS) 포함하면 꽤 많은 급여. 네임밸류"
## [2] "연봉은 정말 많이 준다... 연봉이 1순위이며 자기생활은 주오오하지 않은 사람에게 최고의 회사"
## [3] "무엇보다 연봉과 복지등이 장점 이외의 것은 모르겠다..."
## [4] "본사의 위치가 좋아서 교통이 편하고직원들의 충성도가 높아서 같이 일하는 사람으로서 일할 맛이 났었습니다."
## [5] "보험기업 선두주자이며 복지와 급여가 상당히 만족스럽습니다."
items %>% html_nodes(css = 'dl dd:nth-child(4) span') %>% html_text()
## [1] "단기 목표 지향적인 문화. 선진 외국 기업의 겉만 따라하려는 문화."
## [2] "영업쪽은 정말 자기 인생이 1도 없다. 야근이 없는 날이 드물며 실적 스트레스도 상당한편"
## [3] "승진은 역시나 힘들고 매우 잦은 야근과 조직문화가 딱딱함"
## [4] "구내식당 줄이 너무 길어서 밥을 먹을 때 기다렸다가 먹어야 하는 단점이 있습니다.업무 분담이 너무 확실해서 일이 조금 더디게 진행되는 부분이 있습니다."
## [5] "보수적인 분위기, MS 비율 하락되어 시장 경쟁력 확보 필요가 시급합니다."
items %>% html_nodes(css = 'dl dd:nth-child(6) span') %>% html_text()
## [1] "임원분들의 계약기간때문에 장기적인 목표를 가져갈 수 없다는 현실은 이해하지만, 이를 보완할수있는 체계가 마련되어 더 발전했으면"
## [2] "지점 실적을 줄이거나, 업무강도를 낮춰줘야한다"
## [3] "조직문화를 좀 더 유연하게 만들었으면 좋겠다고 생각함."
## [4] "직원들과 대화 나누는 시간이나 직원 가족과 만남을 가져서 대기업이지만 개개인이 아닌 전체 직원이 하나된 마음이 될 수 있었습니다."
## [5] "1위 기업 유지하기 위해 많은 노력과 시장조사가 필요합니다."
items %>% html_nodes(css = 'p.etc_box strong') %>% html_text()
## [1] "비슷" "비슷" "성장" "성장" "비슷"
items %>% html_nodes(css = 'p.txt.recommend.etc_box') %>% html_text()
## [1] "이 기업을 추천 합니다!" "이 기업을 추천하지 않습니다."
## [3] "이 기업을 추천 합니다!" "이 기업을 추천 합니다!"
## [5] "이 기업을 추천 합니다!"
이렇게 하면 한 페이지당 5개씩 보이는 기업리뷰를 빠짐없이 수집할 수 있습니다. 그런데 현재 등록된 기업리뷰는 모두 279건이므로 모든 기업리뷰를 수집하려면 페이지 네비게이션을 활용해야 합니다. 마우스를 이용하여 화면을 가장 아래로 내리면 1부터 5까지 숫자가 적힌 메뉴가 보일 것입니다. 그 중에서 2를 클릭해보면 URI가 바뀌어 있을 것입니다. 3도 누르고 4도 눌러보세요. 어떤 패턴이 보이죠? 아마 R 코드를 작성해 본 경험이 많은 분이라면 for() 함수를 이용하여 반복문을 만들어야 된다는 것을 짐작했을 것입니다. 그리고 HTTP 요청 과정에서 URI를 조금씩 바꿔주면 됩니다.
사용자 정의 함수 만들기
반복문을 사용하기 전에 데이터 수집 과정에서 반복되는 부분을 좀 더 간단하게 처리할 수 있도록 사용자 정의 함수를 3개 생성하겠습니다. 별로 어렵지 않습니다.
# CSS Selector로 텍스트만 수집하는 함수를 생성합니다.
getHtmlText <- function(x, css) {
result <- x %>%
html_node(css = css) %>%
html_text()
return(result)
}
# CSS Selector로 별점을 수집하는 함수를 생성합니다.
getHtmlRate <- function(x, css, name) {
result <- x %>%
html_node(css = css) %>%
html_attr(name = name) %>%
str_remove_all(pattern = '(width:)|(%;)') %>%
as.numeric()
return(result)
}
# 개별 기업리뷰를 수집하고 데이터 프레임으로 반환하는 함수를 생성합니다.
getData <- function(x) {
# 기업리뷰를 포함하는 HTML 요소를 추출하여 items 객체에 할당합니다.
items <- x %>% read_html() %>% html_nodes(css = 'section.content_ty4')
# 웹 데이터를 수집하여 df 객체에 할당합니다.
df <-
data.frame(
회사이름 = x %>% read_html() %>% html_node(css = 'h2.tit') %>% html_text(),
회사코드 = items %>% html_attr(name = 'data-company_id'),
리뷰코드 = items %>% html_attr(name = 'data-content_id'),
직종구분 = getHtmlText(x = items, css = 'div.content_top_ty2 span:nth-child(2)'),
재직상태 = getHtmlText(x = items, css = 'div.content_top_ty2 span:nth-child(4)'),
근무지역 = getHtmlText(x = items, css = 'div.content_top_ty2 span:nth-child(6)'),
등록일자 = getHtmlText(x = items, css = 'div.content_top_ty2 span.txt2'),
별점평가 = getHtmlRate(x = items, css = 'div.star_score', name = 'style'),
승진기회 = getHtmlRate(x = items, css = 'dl dd:nth-child(3) div div', name = 'style'),
복지급여 = getHtmlRate(x = items, css = 'dl dd:nth-child(5) div div', name = 'style'),
워라밸 = getHtmlRate(x = items, css = 'dl dd:nth-child(7) div div', name = 'style'),
사내문화 = getHtmlRate(x = items, css = 'dl dd:nth-child(9) div div', name = 'style'),
경영진 = getHtmlRate(x = items, css = 'dl dd:nth-child(11) div div', name = 'style'),
기업장점 = getHtmlText(x = items, css = 'dl dd:nth-child(2) span'),
기업단점 = getHtmlText(x = items, css = 'dl dd:nth-child(4) span'),
바라는점 = getHtmlText(x = items, css = 'dl dd:nth-child(6) span'),
성장예상 = getHtmlText(x = items, css = 'p.etc_box strong'),
추천여부 = getHtmlText(x = items, css = 'p.txt.recommend.etc_box')
)
return(df)
}
첫 번째 사용자 정의 함수는 CSS Selector 기준으로 HTML 요소를 찾고 여는 태그와 닫는 태그 사이에 있는 텍스트만 수집하는 기능을 합니다. 두 번째 사용자 정의 함수는 별점을 수집하기 위해 만든 것인데 HTML 요소의 속성명을 기준으로 속성값을 반환하는 함수입니다. 마지막 사용자 정의 함수는 개별 기업리뷰를 수집하여 데이터 프레임으로 반환하는 함수입니다. 3개의 사용자 정의 함수를 만들지 않고도 반복문을 만들 수 있지만 가독성이 떨어질 수 있습니다. 반면 사용자 정의 함수를 사용하면 반복문이 깔끔해집니다.
반복문으로 전체 데이터 수집하기
# 총 페이지 수 계산하고 그 결과를 출력합니다.
pages <- ceiling(x = reviewCnt / 5)
print(x = pages)
## [1] 56
모두 56 페이지를 수집하면 될 것입니다. 반복문 실행에 앞서 첫 번째 페이지의 5개를 저장하여 최종 데이터 객체를 생성합니다.
# 결과를 저장할 객체 생성
result <- getData(x = resp)
# result 객체를 출력합니다.
print(x = result)
## 회사이름 회사코드 리뷰코드 직종구분 재직상태 근무지역
## 1 삼성화재해상보험(주) 30056 849559 금융/재무 현직원 서울
## 2 삼성화재해상보험(주) 30056 847215 영업/제휴 전직원 서울
## 3 삼성화재해상보험(주) 30056 847067 금융/재무 전직원 서울
## 4 삼성화재해상보험(주) 30056 846461 인사/총무 전직원 서울
## 5 삼성화재해상보험(주) 30056 840800 IT/인터넷 현직원 서울
## 등록일자 별점평가 승진기회 복지급여 워라밸 사내문화 경영진
## 1 2018/10/16 80 80 100 60 80 80
## 2 2018/10/14 20 60 100 20 20 20
## 3 2018/10/14 60 40 80 40 60 60
## 4 2018/10/14 100 80 100 80 100 100
## 5 2018/10/9 80 80 100 80 80 80
## 기업장점
## 1 그룹 인센티브(흔히 PS) 포함하면 꽤 많은 급여. 네임밸류
## 2 연봉은 정말 많이 준다... 연봉이 1순위이며 자기생활은 주오오하지 않은 사람에게 최고의 회사
## 3 무엇보다 연봉과 복지등이 장점 이외의 것은 모르겠다...
## 4 본사의 위치가 좋아서 교통이 편하고직원들의 충성도가 높아서 같이 일하는 사람으로서 일할 맛이 났었습니다.
## 5 보험기업 선두주자이며 복지와 급여가 상당히 만족스럽습니다.
## 기업단점
## 1 단기 목표 지향적인 문화. 선진 외국 기업의 겉만 따라하려는 문화.
## 2 영업쪽은 정말 자기 인생이 1도 없다. 야근이 없는 날이 드물며 실적 스트레스도 상당한편
## 3 승진은 역시나 힘들고 매우 잦은 야근과 조직문화가 딱딱함
## 4 구내식당 줄이 너무 길어서 밥을 먹을 때 기다렸다가 먹어야 하는 단점이 있습니다.업무 분담이 너무 확실해서 일이 조금 더디게 진행되는 부분이 있습니다.
## 5 보수적인 분위기, MS 비율 하락되어 시장 경쟁력 확보 필요가 시급합니다.
## 바라는점
## 1 임원분들의 계약기간때문에 장기적인 목표를 가져갈 수 없다는 현실은 이해하지만, 이를 보완할수있는 체계가 마련되어 더 발전했으면
## 2 지점 실적을 줄이거나, 업무강도를 낮춰줘야한다
## 3 조직문화를 좀 더 유연하게 만들었으면 좋겠다고 생각함.
## 4 직원들과 대화 나누는 시간이나 직원 가족과 만남을 가져서 대기업이지만 개개인이 아닌 전체 직원이 하나된 마음이 될 수 있었습니다.
## 5 1위 기업 유지하기 위해 많은 노력과 시장조사가 필요합니다.
## 성장예상 추천여부
## 1 비슷 이 기업을 추천 합니다!
## 2 비슷 이 기업을 추천하지 않습니다.
## 3 성장 이 기업을 추천 합니다!
## 4 성장 이 기업을 추천 합니다!
## 5 비슷 이 기업을 추천 합니다!
이제 데이터 수집의 마지막 여정인 반복문을 만들어 실행하겠습니다. 현재 얼마나 진행되고 있는지 확인할 수 있으면 기다리는 시간이 지루하지 않겠죠? 실제로 이 포스팅에서는 진행경과가 출력되지 않습니다. 직접 실행해보세요.
# 반복문을 실행합니다.
for (page in 2:pages) {
# 작업 시작시각을 저장합니다.
startTime <- Sys.time()
# 현재 진행사항을 출력합니다.
cat('[', page, '/', pages, '] 현재 진행 중! ')
# 웹 페이지 URI를 조립합니다.
cURI <- str_c(URI, '?page=', page)
# HTTP 요청을 합니다.
resp <- GET(url = cURI, config = list(cookies = myCookies))
# 해당 페이지의 기업리뷰를 추출하여 df 객체에 할당합니다.
df <- getData(x = resp)
# result 객체에 df 객체를 추가합니다.
result <- rbind(result, df)
# 작업 종료시각를 저장합니다.
endTime <- Sys.time()
# 작업에 소요된 시간을 출력합니다.
(endTime - startTime) %>% print()
# 불필요한 객체를 삭제합니다.
rm(resp, df)
}
개별 리뷰코드로 중복여부를 확인해볼까요?
# 리뷰코드로 중복여부를 확인합니다.
duplicated(x = result$리뷰코드) %>% sum()
## [1] 0
다행하게도 중복이 없습니다. 이제 데이터를 RDS로 저장합니다.
# 최종 데이터를 RDS로 저장합니다.
fileNm <- str_c('../data/Company_Review_Data_', compNm, '.RDS')
saveRDS(object = result, file = fileNm)