
[특강] 기업리뷰 분석 3
텍스트 마이닝을 활용한 기업리뷰 분석
Dr.Kevin 10/31/2018
기업리뷰 분석 마지막 포스팅입니다. 이번 포스팅에서는 기업리뷰 중 장점, 단점 및 경영진에 바라는 점 등 텍스트 데이터를 이용하여 기업리뷰에 담긴 공통된 생각을 추출하는 작업을 해보겠습니다. 텍스트 마이닝에 대해서 익숙하지 않은 분들이 많을 것 같습니다. 간단하게 전체 과정을 소개하면 다음과 같습니다.
텍스트 마이닝 과정
-
가장 처음 해야 할 일은 자연어를 분석할 수 있는 데이터 형태로 변환하는 것입니다. 따라서 형태소 분석을 실시합니다. 형태소 분석을 할 때 사전이 필요한 데, 텍스트 데이터는 도메인에 영향을 많이 받으므로 형태소 분석을 할 때마다 사전을 만들어야 하는 경우가 일반적입니다. 사전을 만들 때는 N-gram을 사용하는 방법이 있지만 최근에는 딥러닝 기법을 활용한다고도 합니다. (저는 딥알못이라 지금은 모르지만 곧 공부하고 싶습니다.)
-
형태소 분석이 끝나면 말뭉치를 전처리하여 문서단어행렬(Document-Term Matrix, 이하 DTM) 또는 이를 전치한 단어문서행렬(Term-Document Matrix, 이하 TDM)를 생성합니다. DTM의 원소는 단어 빈도수(Term Frequency, 이하 TF) 또는 단어 빈도수와 역문서 빈도수(Term Frequency - Inverse Document Frequency, 이하 TF-IDF)가 사용됩니다. TF는 단어의 빈도수가 많을수록 중요하다고 간주하지만, TF-IDF는 여러 문서에서 두루 출현하는 단어에 벌점을 부여함으로써 특정 문서에 집중해서 많이 출현하는 단어를 중요하다고 간주합니다.
-
DTM이 생성되면 컬럼의 합계(단어별 빈도수) 데이터로 다양한 시각화를 실행할 수 있습니다. 단어별 빈도수를 내림차순으로 정렬한 다음 상위 단어들로 막대그래프를 그리거나 아니면 워드클라우드 또는 트리맵 등을 그릴 수 있습니다.
-
특정 단어에 대해 함께 출현하는 연관성이 높은 단어들을 추출해보는 작업을 수행하면 문서에 대한 이해를 높일 수 있습니다. 주로 3가지 방법을 사용하는데 하나는 DTM의 상관행렬을 구하는 것이고, 다른 하나는 R의 tm 패키지에서 제공되는 함수를 사용하는 것이며, 마지막으로 word2vec 알고리즘을 사용하는 것입니다. 이번 포스팅에서는 처음 2가지를 소개합니다.
-
마지막으로 상관관계가 높은 단어들을 연결한 네트워크 맵을 그려봄으로써 전체 문서에서 공통적으로 언급된 단어들의 흐름을 파악할 수 있습니다. 중개중심성이 높은 단어들을 중심으로 흐름을 파악하면 됩니다. 생각보다 쉽지 않습니다.
이 외에도 토픽 클러스터링과 감성분석 등이 있지만 이번 포스팅에서는 다루지 않겠습니다. 사실 둘 다 해봤는데요. 데이터가 좀 이상해서 그런지 결과가 별로더라구요. 다음에 기회가 닿으면 소개하도록 하겠습니다.
형태소 분석
기업리뷰 데이터 컬럼 중 텍스트 데이터만 추출하고, 자연어를 분석할 수 있는 데이터로 변환하기 위해 형태소 분석을 실시합니다. 먼저 RDS 데이터를 불러와서 간단한 전처리를 실행합니다.
# 필요한 패키지를 불러옵니다.
library(tidyverse)
library(stringr)
library(stringi)
library(magrittr)
# 분석 대상 회사이름을 지정합니다.
compNm <- '삼성화재'
# RDS 파일을 읽어옵니다.
dt <- readRDS(file = '../data/Company_Review_Data_삼성화재해상보험.RDS')
# 별점을 1~5점으로 환산합니다.
dt[, 8:13] <- sapply(X = dt[, 8:13], FUN = function(x) x / 20)
# 추천여부 컬럼을 '추천'과 '비추'로 변환합니다.
dt$추천여부 <- str_extract(string = dt$추천여부, pattern = '추천(?= )')
dt$추천여부[is.na(x = dt$추천여부) == TRUE] <- '비추'
# 필요한 컬럼만 선택합니다.
cols <- c('기업장점', '기업단점', '바라는점', '재직상태', '별점평가', '추천여부')
texts <- dt[, cols]
# NA가 포함된 행을 제거합니다.
texts <- texts[complete.cases(texts), ]
nrow(x = texts)
## [1] 279
# 중복 행을 제거합니다.
texts <- unique(x = texts)
nrow(x = texts)
## [1] 279
데이터 원본과 나중에 생성할 DTM을 서로 결합할 때 기준변수로 사용할 id 컬럼을 생성합니다.
# 객체에 id를 추가하는 함수를 생성합니다.
generateIDs <- function(obj, index = 'id') {
# 객체의 종류에 따라 길이를 계산합니다.
if (obj %>% class() == 'data.frame') {
n <- nrow(x = obj)
} else {
n <- length(x = obj)
}
# id를 생성합니다.
id <- str_c(
index,
str_pad(
string = 1:n,
width = ceiling(x = log10(x = n)),
side = 'left',
pad = '0') )
# 결과를 반환합니다.
return(id)
}
# texts 객체에 id 컬럼을 추가합니다.
texts$id <- generateIDs(obj = texts, index = 'doc')
텍스트 데이터 컬럼인 장점, 단점 및 바라는점을 붙여서 하나의 컬럼으로 만듭니다. 그리고 공백을 모두 없앱니다. 그 이유는 다음과 같습니다. 기업리뷰 데이터는 한 명이 작성한 것이 아니므로 회원마다 말버릇이 다릅니다. 같은 단어의 경우 띄어쓰기도 제각각일 수 있습니다. 실제로 이 데이터에서는 ‘자기계발’과 ‘자기계발기회’가 혼재되어 있었습니다. 나중에 사전을 만들어서 형태소 분석할 때 사용한다고 하더라도 100% 같은 방식으로 처리되지 못하므로 아예 처음부터 공백을 없애는 것입니다. 다행인 점은 우리가 앞으로 사용할 형태소 분석기가 띄어쓰기를 처리할 수 있다는 것입니다.
# '장점', '단점' 및 '바라는점' 등 텍스트 데이터를 붙여서
# 텍스트 마이닝을 위한 content 컬럼을 만듭니다.
texts$content <- apply(
X = texts[, c('기업장점', '기업단점', '바라는점')],
MARGIN = 1,
FUN = str_c, collapse = ' ')
# 텍스트의 공백을 모두 제거합니다. 형태소 분석기가 띄어쓰기를 구분합니다.
texts$content <- texts$content %>% str_remove_all(pattern = '\\s+')
# 필요한 컬럼만 남깁니다.
texts <- texts[ , c('id', 'content', '재직상태', '추천여부')]
# 중복을 제거합니다.
texts <- unique(x = texts)
# 건수를 확인합니다.
nrow(x = texts)
## [1] 279
회원마다 리뷰를 길게 남기는 사람이 있는가하면 아주 간단하게 쓰는 사람도 있습니다. 텍스트 마이닝에서는 단어 하나 하나가 모두 정보가 되므로 글이 길수록 정보가 많다고 할 수 있습니다. 따라서 글자의 길이가 작은 문서는 과감하게 제외하는 것이 좋습니다. 이번 예제에서는 글자수가 40 미만인 9개의 문서를 제외하였습니다.
# content 컬럼의 글자수를 확인합니다.
textRange <- texts$content %>% nchar() %>% range()
print(x = textRange)
## [1] 9 554
# 글자수 구간을 15개로 나눌 때 간격(by)을 계산합니다.
by <- ((textRange[2] - textRange[1]) / 15) %>% round(digits = -1L)
print(x = by)
## [1] 40
# 도수분포표를 생성합니다. 이때, 최소값과 최대값을 포함하도록 합니다.
# Hmisc::cut2() 함수의 minmax 인자로 최소값 또는 최대값을 포함할지 여부를 지정합니다.
cuts <- Hmisc::cut2(
x = texts$content %>% nchar(),
cuts = seq(from = 0, to = textRange[2], by = by),
minmax = TRUE)
# 빈도수를 구합니다.
freq <- table(cuts)
print(freq)
## cuts
## [ 0, 40) [ 40, 80) [ 80,120) [120,160) [160,200) [200,240) [240,280)
## 9 43 101 57 39 16 3
## [280,320) [320,360) [360,400) [400,440) 440 480 [520,554]
## 6 2 1 1 0 0 1
# 첫 번째 구간에 포함된 40 글자 미만인 글을 확인합니다.
texts$content[nchar(x = texts$content) < by]
## [1] "높은보수낮은기본급직원기본급보장"
## [2] "높은인지도와체계적인시스템성과급의부재질좋은프로모션많이해주셨으면"
## [3] "업무의자율성낮은보수임금인상"
## [4] "교육이좋음업무강도강함"
## [5] "자율성영업복리후생"
## [6] "업무의자율성이용이함성과에따른보수차보너스많이줬으면..."
## [7] "좋은시설퇴직금안주려초단시간근로를시킨다초단시간알바에게도복지혜택은주기바란다"
## [8] "신뢰와효율,가치를실현하는것과중된업무로인한피로좀더가족적인이미지가필요하다"
## [9] "복지혜택좋다급여대비업무과다인력관리에힘좀쓰세요"
# 첫 번째 구간에 해당하는 건을 삭제합니다.
texts <- texts[nchar(x = texts$content) >= by, ]
# 건수를 확인합니다.
nrow(x = texts)
## [1] 270
지금까지 형태소 분석을 하기 위한 전처리 과정을 거쳤고 이제부터 형태소 분석에 들어갑니다. 저는 형태소 분석기로 NLP4kec 패키지의 함수를 사용합니다. CRAN에 등록되어 있지 않으므로 Github 링크로 설치하면 됩니다. 문제는 이 패키지가 rJava 패키지에 의존한다는 것입니다. 그러므로 Java를 설치해야 하고 Java Home을 설정한 다음 rJava 패키지를 불러올 수 있어야 합니다.
# 패키지를 설치합니다.
# install.packages('~/Documents/TextMining/NLP4kec_1.2.0.tgz', repos = NULL)
# 필요한 패키지를 불러옵니다.
library(NLP4kec)
지금 다루고 있는 데이터에 사용할 수 있는 사전이 없으므로 일단 사전 없이 형태소 분석을 수행합니다. 아래 과정을 거치면서 사전을 만들 예정이고, 사전이 완성되면 이번 과정을 한 번 더 반복합니다. 물론 그 때는 사전을 가지고 형태소 분석을 한다는 점에서 차이가 있습니다.
# 형태소를 분석하여 parsed 객체에 할당합니다. 이 때 띄어쓰기가 구분됩니다.
parsed <- r_parser_r(contentVector = texts$content, language = 'ko')
# 길이를 확인합니다.
length(x = parsed)
## [1] 270
# 형태소 분석 결과 중 일부를 육안으로 확인합니다.
parsed[1:10]
## [1] "그룹 인센티브 포함 많다 급여 네임 밸류 단기 목표 지향 문화 선진 외국 기업 겉 따르다 하다 문화 임원 계약 기간 때문 장기 목표 가져가다 수 없다 현실 이해 이 보완 수 있다 체계 마련 발전 "
## [2] "연봉 주다 연봉 순위 자기 생활 주 오오 않다 사람 최고 회사 영업 쪽 자기 인생 1도 없다 야근 없다 날 드물다 실적 스트레스 상당 한편 지점 실적 줄이다 업무 강도 낮추다 주다 하다 "
## [3] "무엇 연봉 복지 등 장점 이외 것 모르다 승진 나 힘들다 잦다 야근 조직 문화 딱딱하다 조직 문화 유연하다 만들다 좋다 생각 "
## [4] "본사 위치 좋다 교통 편하다 직원 충성 높다 일 사람 일 맛 나다 구내식당 줄 길다 밥 먹다 때기 다리다 먹다 하다 단점 있다 업무 분담 확실하다 일 더디다 진행 부분 있다 직원 대화 나누다 시간 직원 가족 만남 가지다 기업 개개인 전체 직원 되다 마음 되다 수 있다 "
## [5] "보험 기업 선두 주자 복지 급여 만족 보수 분위기 비율 하락 시장 경쟁력 확보 필요 시급하다 1위 기업 유지 위하다 많다 노력 시장 조사 필요 "
## [6] "시간 자유 서원 만큼 일 하다 수 있다 양복 입다 근무 것 장점 수 있다 실적 제다 보다 월급 일정 않다 영업 인하다 실적 압박 시달리다 수당 수수료 챙기다 주다 설계사 힘들다 "
## [7] "기업 자부심 느끼다 수 있다 졸다 취업 결정 학교 생활 마치다 뒤 취업 나가다 좋다 높다 연봉 높다 업무 강도 퇴사 사람 많다 업무 강도 낮추다 주다 좋다 일한 받다 것 생각 "
## [8] "연봉 연봉 연봉 보람 없다 보수 못하다 일 하다 않다 만년 병장 느낌 수석 많다 좋다 것 좋다 것 가족 분위기 맡다 능력 근거 평가 필요 "
## [9] "급여 같다 연차 회사 직원 비하다 높다 복지 있다 업무 스트레스 직무 순환 되다 않다 어디 갈다 존재 어르신 현장 목소리 듣다 수 있다 기회 만들다 주다 "
## [10] "높다 연봉 성과급 근무 환경 따르다 연차 쓰다 수 있다 인력 부족 경우 가능 수 있다 삼성 자부심 퇴근 시간 일정 않다 하다 눈치 봄 군대식 문화 나 레비 실적 줄 세우다 직군 은근하다 차별 존재 출퇴근 시간 지키다 직원 스트레스 관리 앞장서다 "
# NA가 포함되어 있는지 확인합니다.
parsed[is.na(x = parsed) == TRUE]
## character(0)
# 글자수를 확인합니다.
parsed %>% nchar() %>% table()
## .
## 46 49 51 52 53 55 56 57 61 62 66 68 69 70 72 73 74 75
## 1 1 1 2 1 1 1 1 1 1 1 1 2 3 1 3 7 1
## 76 77 78 79 80 81 82 83 84 85 86 87 88 89 91 93 94 95
## 4 3 2 3 3 4 2 1 3 1 5 3 2 1 2 3 4 3
## 96 97 98 99 100 101 102 104 105 107 108 109 110 111 112 113 114 115
## 3 2 5 7 3 2 2 3 3 4 3 3 2 2 1 1 4 2
## 116 118 119 121 122 124 125 127 128 129 130 131 132 133 134 136 137 138
## 3 4 3 2 3 1 5 1 3 3 1 2 3 2 1 1 3 1
## 139 140 141 142 143 144 145 146 147 148 150 151 152 153 155 156 157 158
## 2 3 2 1 5 1 1 1 1 1 3 1 1 1 4 2 1 1
## 160 162 163 164 165 166 167 168 169 171 172 173 174 175 178 180 181 184
## 1 1 1 1 1 1 1 1 1 1 2 1 1 1 1 3 2 1
## 185 189 190 191 192 193 194 196 197 199 202 205 209 210 214 216 217 219
## 1 2 1 1 1 1 1 3 1 1 1 1 2 1 1 2 1 2
## 223 226 229 245 250 254 263 264 271 272 304 315 327 341 343 345 366 554
## 1 1 1 2 1 1 1 1 1 1 1 1 1 1 1 1 1 1
# 중복 건수를 확인합니다.
duplicated(x = parsed) %>% sum()
## [1] 0
형태소 분석을 마치면 말뭉치(corpus)를 생성합니다. 말뭉치를 생성하기 전에 텍스트를 벡터 소스로 변경합니다. 벡터 소스는 벡터의 개별 원소를 각각의 문서로 인식합니다. tm 패키지를 불러온 다음 아래 라인을 실행하시면 됩니다.
# 필요한 패키지를 불러옵니다.
library(tm)
# 말뭉치를 생성합니다.
corpus <- parsed %>% VectorSource() %>% VCorpus()
print(corpus)
## <<VCorpus>>
## Metadata: corpus specific: 0, document level (indexed): 0
## Content: documents: 270
결과 객체인 corpus는 content와 meta를 원소로 갖는 리스트입니다. content에는 한글 텍스트가, meta에는 데이터 속성이 할당되어 있습니다.
# 첫 번째 결과를 출력하여 확인합니다.
str(object = corpus[[1]])
## List of 2
## $ content: chr "그룹 인센티브 포함 많다 급여 네임 밸류 단기 목표 지향 문화 선진 외국 기업 겉 따르다 하다 문화 임원 계약 기간 때"| __truncated__
## $ meta :List of 7
## ..$ author : chr(0)
## ..$ datetimestamp: POSIXlt[1:1], format: "2018-10-31 02:18:46"
## ..$ description : chr(0)
## ..$ heading : chr(0)
## ..$ id : chr "1"
## ..$ language : chr "en"
## ..$ origin : chr(0)
## ..- attr(*, "class")= chr "TextDocumentMeta"
## - attr(*, "class")= chr [1:2] "PlainTextDocument" "TextDocument"
이제 사전을 만들기 위해 N-gram을 사용합니다. 사전을 만드는 과정은 다음과 같습니다. 말뭉치에서 인접한 2 단어씩 묶은 bigram을 생성하고 빈도수 기준으로 내림차순 정렬합니다. 명사 위주로 띄어쓰기를 없앨 필요가 있는지 확인합니다. 만약 ‘업무 량’ 같이 하나의 단어로 처리해야 한다고 판단되면 이와 같은 bigram만 따로 모아 spacing.txt에 저장합니다. 나중에 공백을 없앤 단어들만 dictionary.txt에 추가하면 됩니다.
# 필요한 패키지를 불러옵니다.
library(RWeka)
# 인접한 2개의 단어를 결합한 bigram을 생성합니다.
# min과 max에 할당할 숫자를 바꾸면 원하는 N-gram을 만들 수 있습니다.
bigram <- function(x) {
NGramTokenizer(x = x, control = Weka_control(min = 2, max = 2))
}
# 단어문서행렬(Term-Document matrix)을 생성합니다.
bigramList <- corpus %>%
TermDocumentMatrix(control = list(tokenize = bigram)) %>%
apply(MARGIN = 1, FUN = sum) %>%
sort(decreasing = TRUE)
# bigram의 길이를 확인합니다.
length(bigramList)
## [1] 8396
# 문서 개수의 1% 이상 발생하는 bigram만 남깁니다.
# 빈도수가 작은 것은 굳이 관심을 가지지 않아도 됩니다.
bigramList <- bigramList[bigramList >= (nrow(x = texts) * 0.01)]
length(x = bigramList)
## [1] 451
# bigram의 컬럼명(글자)만 따로 추출하여 bigramNames에 할당합니다.
bigramNames <- names(bigramList)
# bigramNames을 육안으로 확인하기 위해 최대 100개까지 출력합니다.
top <- if (length(x = bigramNames) >= 100) bigramNames[1:100] else bigramNames
print(top)
## [1] "수 있다" "업무 강도" "높다 연봉" "것 같다"
## [5] "기업 문화" "수 없다" "업계 1위" "업무 량"
## [9] "연봉 높다" "주다 좋다" "하다 하다" "되다 있다"
## [13] "복리 후생" "있다 업무" "주다 하다" "받다 수"
## [17] "하다 주다" "강도 높다" "조직 문화" "하다 수"
## [21] "높다 급여" "일 하다" "좋다 회사" "근무 환경"
## [25] "급여 수준" "높다 편" "복지 좋다" "있다 것"
## [29] "하다 것" "교육 기회" "실적 압박" "일 많다"
## [33] "있다 하다" "지다 있다" "되다 않다" "문화 개선"
## [37] "보수 기업" "삶 균형" "경우 많다" "높다 업무"
## [41] "돈 주다" "량 많다" "보험 회사" "있다 연봉"
## [45] "근무 시간" "동종 업계" "되다 수" "보험 사"
## [49] "복지 혜택" "쓰다 수" "일 삶" "있다 좋다"
## [53] "자기 계발" "최고 수준" "1위 기업" "1위 자부심"
## [57] "국내 최고" "급여 높다" "느끼다 수" "도움 되다"
## [61] "쉽다 않다" "야근 많다" "야근 잦다" "연봉 복지"
## [65] "인간 관계" "잦다 야근" "좋다 지다" "퇴근 시간"
## [69] "필요 있다" "것 생각" "근로 문화" "눈치 보다"
## [73] "라이프 밸런스" "보험업 특성" "삼성 계열사" "삼성 화재"
## [77] "성과 주의" "손해 보험" "시스템 되다" "신경 쓰다"
## [81] "업계 최고" "업무 시간" "없다 업무" "워크 라이프"
## [85] "의사 결정" "있다 않다" "있다 회사" "자부심 있다"
## [89] "출근 시간" "하다 않다" "것 없다" "것 좋다"
## [93] "국내 시장" "네임 밸류" "높다 수준" "눈치 보이다"
## [97] "늦다 퇴근" "되다 것" "많다 업무" "복지 되다"
top 객체를 spacing.txt를 생성합니다. 이 파일을 열고 띄어쓰기를 수정해야 하는 것들만 남기고 저장합니다.
# spacing.txt를 생성합니다.
write.table(
x = top,
quote = FALSE,
file = '../data/spacing.txt',
row.names = FALSE,
col.names = FALSE)
spacing.txt 파일을 읽은 다음 spacing 객체에 할당합니다. 이 객체에는 문자 벡터가 하나 저장되어 있을텐데요. 이 컬럼명을 before로 지정합니다. 그리고 before에서 띄어쓰기를 없앤 문자 벡터를 after 컬럼으로 추가한 다음 이 컬럼으로 dictionary.txt 파일을 생성합니다.
#
spacing <- read.table(file = '../data/spacing.txt', sep = '\t')
colnames(x = spacing) <- 'before'
# 중복을 제거합니다.
spacing <- unique(x = spacing)
# 띄어쓰기 없앤 문자벡터를 after 컬럼으로 추가합니다.
spacing$after <- spacing$before %>% str_remove_all(pattern = ' ')
# 이제 dictionary.txt로 저장합니다.
write.table(
x = spacing$after,
quote = FALSE,
file = '../data/dictionary.txt',
row.names = FALSE,
col.names = FALSE)
사전 만들기를 완성했다면 형태소 분석을 재실행합니다. 이번에는 사전을 추가합니다.
# 사전을 추가한 다음 형태소 분석을 다시 실행합니다.
parsed <- r_parser_r(
contentVector = texts$content,
language = 'ko',
korDicPath = '../data/dictionary.txt')
# 길이를 확인합니다.
length(x = parsed)
## [1] 270
# 형태소 분석 결과 중 일부를 육안으로 확인합니다.
parsed[1:10]
## [1] "그룹 인센티브 포함 많다 급여 네임밸류 단기 목표 지향 문화 선진 외국 기업 겉 따르다 하다 문화 임원 계약 기간 때문 장기 목표 가져가다 수 없다 현실 이해 이 보완 수 있다 체계 마련 발전 "
## [2] "연봉 주다 연봉 순위 자기 생활 주 오오 않다 사람 최고 회사 영업 쪽 자기 인생 1도 없다 야근 없다 날 드물다 실적 스트레스 상당 한편 지점 실적 줄이다 업무강도 낮추다 주다 하다 "
## [3] "무엇 연봉 복지 등 장점 이외 것 모르다 승진 나 힘들다 잦다 야근 조직문화 딱딱하다 조직문화 유연하다 만들다 좋다 생각 "
## [4] "본사 위치 좋다 교통 편하다 직원 충성 높다 일 사람 일 맛 나다 구내식당 줄 길다 밥 먹다 때기 다리다 먹다 하다 단점 있다 업무 분담 확실하다 일 더디다 진행 부분 있다 직원 대화 나누다 시간 직원 가족 만남 가지다 기업 개개인 전체 직원 되다 마음 되다 수 있다 "
## [5] "보험 기업 선두 주자 복지 급여 만족 보수 분위기 비율 하락 시장 경쟁력 확보 필요 시급하다 1위 기업 유지 위하다 많다 노력 시장 조사 필요 "
## [6] "시간 자유 서원 만큼 일 하다 수 있다 양복 입다 근무 것 장점 수 있다 실적 제다 보다 월급 일정 않다 영업 인하다 실적압박 시달리다 수당 수수료 챙기다 주다 설계사 힘들다 "
## [7] "기업 자부심 느끼다 수 있다 졸다 취업 결정 학교 생활 마치다 뒤 취업 나가다 좋다 높다 연봉 높다 업무강도 퇴사 사람 많다 업무강도 낮추다 주다 좋다 일한 받다 것 생각 "
## [8] "연봉 연봉 연봉 보람 없다 보수 못하다 일 하다 않다 만년 병장 느낌 수석 많다 좋다 것 좋다 것 가족 분위기 맡다 능력 근거 평가 필요 "
## [9] "급여 같다 연차 회사 직원 비하다 높다 복지 있다 업무 스트레스 직무순환 되다 않다 어디 갈다 존재 어르신 현장 목소리 듣다 수 있다 기회 만들다 주다 "
## [10] "높다 연봉 성과급 근무환경 따르다 연차 쓰다 수 있다 인력 부족 경우 가능 수 있다 삼성 자부심 퇴근시간 일정 않다 하다 눈치 봄 군대식문화 나 레비 실적 줄 세우다 직군 은근하다 차별 존재 출퇴근시간 지키다 직원 스트레스 관리 앞장서다 "
# 말뭉치를 생성하기 전에 텍스트를 벡터 소스로 변경합니다.
# 벡터 소스는 벡터의 개별 원소를 각각의 문서로 인식합니다.
corpus <- parsed %>% VectorSource() %>% VCorpus()
사전을 추가하여 형태소 분석을 실시해도 여전히 띄어쓰기가 남아있는 경우가 있습니다. 이런 문제는 하나씩 확인해봐야 합니다. 데이터 분석 중 텍스트 마이닝이 특히 어려운 점이 확인해야 할 텍스트 데이터가 무진장 많다는 것입니다. 이번 예제의 경우 아주 작은 데이터를 다루고 있으니 운이 좋다고 할 수 있습니다. (물론 그래서 분석 결과가 그렇게 좋지는 않습니다.)
# 사전으로도 처리되지 않는 단어 띄어쓰기 강제로 변환하는 함수를 생성합니다.
changeTerms <- function(corpus, before, after) {
# corpus의 길이를 확인합니다.
n <- length(x = corpus)
# 반복문을 실행합니다.
for (i in 1:n) {
corpus[[i]]$content <- corpus[[i]]$content %>%
str_replace_all(pattern = before, replacement = after)
}
# 결과를 반환합니다.
return(corpus)
}
# 띄어쓰기가 적용되지 않은 단어들을 강제로 적용합니다.
for (i in 1:nrow(x = spacing)) {
corpus <- changeTerms(
corpus = corpus,
before = spacing$before[i],
after = spacing$after[i])
}
# 의심되는 단어가 여전히 바뀌지 않은 채로 포함되어 있는지 확인합니다.
checkTerms <- function(corpus, term) {
corpus %>%
sapply(FUN = `[[`, 'content') %>%
str_detect(pattern = term) %>%
sum() %>%
print()
}
# 의심되는 단어별로 corpus에 포함된 개수를 확인합니다.
checkTerms(corpus = corpus, term = '워라벨')
## [1] 4
checkTerms(corpus = corpus, term = '일삶균형')
## [1] 8
checkTerms(corpus = corpus, term = '워크라이프밸런스')
## [1] 5
checkTerms(corpus = corpus, term = '자기계발기회')
## [1] 3
checkTerms(corpus = corpus, term = '자기개발')
## [1] 4
checkTerms(corpus = corpus, term = '네임벨류')
## [1] 5
checkTerms(corpus = corpus, term = '군대 문화')
## [1] 0
checkTerms(corpus = corpus, term = '군대식문화')
## [1] 5
checkTerms(corpus = corpus, term = '수직문화')
## [1] 4
checkTerms(corpus = corpus, term = '가정 날')
## [1] 5
checkTerms(corpus = corpus, term = '손보')
## [1] 10
checkTerms(corpus = corpus, term = '조직문화')
## [1] 13
checkTerms(corpus = corpus, term = '회사문화')
## [1] 2
checkTerms(corpus = corpus, term = '근로문화')
## [1] 5
철자가 틀린 단어나 비슷한 뜻을 하나로 통일시키는 작업을 여기에서 실시하면 됩니다.
# 추가로 변경합니다.
corpus <- changeTerms(corpus = corpus, before = '워라벨', after = '워라밸')
corpus <- changeTerms(corpus = corpus, before = '일삶균형', after = '워라밸')
corpus <- changeTerms(corpus = corpus, before = '워크라이프밸런스', after = '워라밸')
corpus <- changeTerms(corpus = corpus, before = '자기계발기회', after = '자기계발 기회')
corpus <- changeTerms(corpus = corpus, before = '자기개발', after = '자기계발')
corpus <- changeTerms(corpus = corpus, before = '네임벨류', after = '네임밸류')
corpus <- changeTerms(corpus = corpus, before = '군대 문화', after = '군대문화')
corpus <- changeTerms(corpus = corpus, before = '군대식문화', after = '군대문화')
corpus <- changeTerms(corpus = corpus, before = '수직문화', after = '군대문화')
corpus <- changeTerms(corpus = corpus, before = '가정 날', after = '가정의날')
corpus <- changeTerms(corpus = corpus, before = '손보', after = '손해보험')
corpus <- changeTerms(corpus = corpus, before = '조직문화', after = '기업문화')
corpus <- changeTerms(corpus = corpus, before = '회사문화', after = '기업문화')
corpus <- changeTerms(corpus = corpus, before = '근로문화', after = '기업문화')
간혹 corpus 객체를 전처리 하다가 실수로 문자 벡터로 변환해버릴 수 있습니다. 그럴 경우 tm 패키지의 함수들을 사용할 수 없으니 반드시 corpus 객체의 속성을 확인하여야 합니다. PlainTextDocument면 통과입니다.
# corpus 객체의 속성을 확인합니다.
class(x = corpus[[1]])
## [1] "PlainTextDocument" "TextDocument"
아래 함수들은 corpus 객체를 전처리할 때 유용하게 사용할 수 있는 함수들입니다. 만약 영문을 사용하거나 기호나 숫자를 없애야 한다면 아래 함수들을 사용하시기 바랍니다. 아래 3줄은 실행하지 않도록 설정했으니 참고하시기 바랍니다.
# 소문자로 변경합니다. (영어가 포함되었을 경우. 대문자는 toupper)
# [주의] content_transformer() 함수를 사용하지 않으면 character로 강제 변환됩니다.
corpus <- tm_map(x = corpus, FUN = content_transformer(FUN = tolower))
# 특수문자를 제거합니다.
corpus <- tm_map(x = corpus, FUN = removePunctuation)
# 숫자를 삭제합니다.
corpus <- tm_map(x = corpus, FUN = removeNumbers)
corpus 객체 전처리의 마지막은 불용어(stopwords)를 삭제하는 것입니다. 한글 불용어는 인터넷에서 공개된 자료가 많으니 별도로 정리하여 사용하든가 아니면 아래 링크를 사용하시면 됩니다. 아래 링크는 인터넷에서 수집하여 정리한 다음 제 github에 올린 것입니다.
# 불용어 객체를 생성합니다.
myStopwords <- read.table(
file = 'https://raw.githubusercontent.com/MrKevinNa/TextMining/master/stopwords.txt') %>%
.$V1
# 불용어(stopwords)를 삭제합니다.
corpus <- tm_map(x = corpus, FUN = removeWords, myStopwords)
# whitespace를 제거합니다.
corpus <- tm_map(x = corpus, FUN = stripWhitespace)
# 문서번호를 새로운 컬럼에 만든 후 데이터 프레임으로 저장합니다.
parsedDf <- data.frame(
id = generateIDs(obj = parsed, index = 'doc'),
parsedContent = parsed,
corpusContent = sapply(X = corpus, FUN = `[[`, 'content'))
문서단어행렬(DTM) 생성
말뭉치 전처리까지 완료했다면 이제 문서단어행렬(Document-Term Matrix)을 생성할 차례입니다. 말뭉치에서 글자의 길이가 2 이상인 단어들만 남긴 다음 DTM의 원소가 TF인 행렬을 만듭니다. 생성된 dtm 객체를 출력하면 여러 가지 정보를 확인할 수 있습니다. sparsity는 전체 행렬에서 0이 차지하는 비중을 의미합니다. weighting은 행렬을 구성하는 각각의 값(value)을 계산한 방식을 나타냅니다.
# DTM을 생성합니다.
dtm <- DocumentTermMatrix(x = corpus, control = list(wordLengths = c(2, Inf)))
# 단어(=컬럼명) 양옆의 공백을 제거합니다.
colnames(x = dtm) <- trimws(x = colnames(x = dtm), which = 'both')
# 차원을 확인합니다.
dim(x = dtm)
## [1] 270 1901
현재 작업 중인 dtm 객체는 270개 행(문서)에서 1901개 열(단어)로 구성된 것입니다. 단어의 수가 상당히 많습니다. 작업의 편의를 위해 대부분이 0인 sparse Terms 일부를 삭제하여 차원을 축소하는 편이 좋습니다. sparse 인자에 할당하는 값의 크기가 작을수록 term의 개수가 크게 감소합니다. 그러니까 sparse가 크다는 것은 그만큼 희소성이 있는 컬럼을 남겨두겠다는 의미가 됩니다. 아래 라인은 각각의 열(단어) 기준으로 sparsity가 0.99를 넘는 열을 삭제합니다. 그 결과 문서의 개수는 변함 없이 단어의 개수만 크게 감소합니다.
# dtm의 차원을 줄입니다.
dtm <- removeSparseTerms(x = dtm, sparse = as.numeric(x = 0.99))
# 차원을 확인합니다.
dim(x = dtm)
## [1] 270 605
# 행의 합이 0인 건수를 확인합니다.
rowSums(x = dtm %>% as.matrix()) %>% table()
## .
## 7 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32
## 2 1 2 6 6 11 8 12 17 15 12 15 12 10 14 16 10 8 8 12 9 5 3 6 1
## 33 34 35 36 37 38 39 40 41 42 44 45 46 49 50 51 56 58 62 63 65 93
## 6 3 4 6 1 3 3 2 2 1 5 2 1 2 1 1 1 1 1 1 1 1
# 문서 이름(row name)을 지정합니다. 나중에 생성할 parsedDf와 병합하기 위함입니다.
dtm$dimnames$Docs <- generateIDs(obj = dtm$dimnames$Docs, index = 'doc')
# dtm 객체를 육안으로 확인합니다.
dtm$dimnames$Docs[1:40]
## [1] "doc001" "doc002" "doc003" "doc004" "doc005" "doc006" "doc007"
## [8] "doc008" "doc009" "doc010" "doc011" "doc012" "doc013" "doc014"
## [15] "doc015" "doc016" "doc017" "doc018" "doc019" "doc020" "doc021"
## [22] "doc022" "doc023" "doc024" "doc025" "doc026" "doc027" "doc028"
## [29] "doc029" "doc030" "doc031" "doc032" "doc033" "doc034" "doc035"
## [36] "doc036" "doc037" "doc038" "doc039" "doc040"
dtm$dimnames$Terms[1:40]
## [1] "10년" "10일" "1년" "1등" "1위" "30분"
## [7] "6시" "8시" "가능" "가정" "가정의날" "가족"
## [13] "가지다" "가치" "각오" "갈다" "감사" "감수"
## [19] "감축" "강도" "강요" "강점" "강제" "강하다"
## [25] "갖다" "갖추다" "같다" "개개인" "개발" "개선"
## [31] "개인" "개인주의" "건강" "건전" "결과" "결재"
## [37] "결정" "경력" "경영" "경영진"
이번에는 TF-IDF를 원소로 갖는 DTM을 생성해보겠습니다. 같은 함수를 사용하지만 control 인자에 할당하는 파라미터가 많이 다릅니다. 역시 글자의 길이가 2 이상인 단어들만 남기고 원소를 계산하는 방식으로 weightTfIdf() 함수를 사용한다는 특징이 있습니다.
# 문서단어행렬의 원소가 TF-IDF인 dtmTfIdf 객체를 생성합니다.
dtmTfIdf <- DocumentTermMatrix(
x = corpus,
control = list(
removeNumbers = TRUE,
wordLengths = c(2, Inf),
weighting = function(x) weightTfIdf(x, normalize = TRUE) ))
# 단어(=컬럼명) 양옆의 공백을 제거합니다.
colnames(x = dtmTfIdf) <- trimws(x = colnames(x = dtmTfIdf))
# 차원을 확인합니다.
dim(x = dtmTfIdf)
## [1] 270 1871
dtmTfIdf 객체의 경우, 행이 270이고 열이 1871인 행렬이 생성되었습니다. 혹시 dtm과 차원이 다른 이유를 짐작하실 수 있나요? 그건 바로 control 인자에 할당된 removeNumbers 때문입니다. 숫자로 된 단어를 모두 제외하였기 때문에 열의 개수가 소폭 감소하였습니다.
dtmTfIdf 객체도 차원을 줄여보겠습니다.
# 네트워크의 크기를 줄이기 위해 sparse가 큰 컬럼을 제거합니다.
# 역시 이 과정을 통해 DTM의 단어 개수가 크게 줄었습니다.
dtmTfIdf <- removeSparseTerms(x = dtmTfIdf, sparse = as.numeric(x = 0.99))
# 차원을 확인합니다.
dim(x = dtmTfIdf)
## [1] 270 598
# 행의 합이 0인 건수를 확인합니다.
rowSums(x = dtmTfIdf %>% as.matrix() %>% round(digits = 1L)) %>% table()
## .
## 1.5 1.8 1.9 2 2.1 2.2 2.3 2.4 2.5 2.6 2.7 2.8 2.9 3 3.1 3.2 3.3 3.4
## 1 1 2 2 3 1 6 2 8 10 10 10 15 17 25 28 17 21
## 3.5 3.6 3.7 3.8 3.9 4 4.1 4.2 4.3 4.4
## 20 24 11 8 12 6 4 3 2 1
# 문서 이름(row name)을 지정합니다. 나중에 생성할 parsedDf와 병합하기 위함입니다.
dtmTfIdf$dimnames$Docs <- generateIDs(obj = dtmTfIdf$dimnames$Docs, index = 'doc')
고빈도 단어 시각화
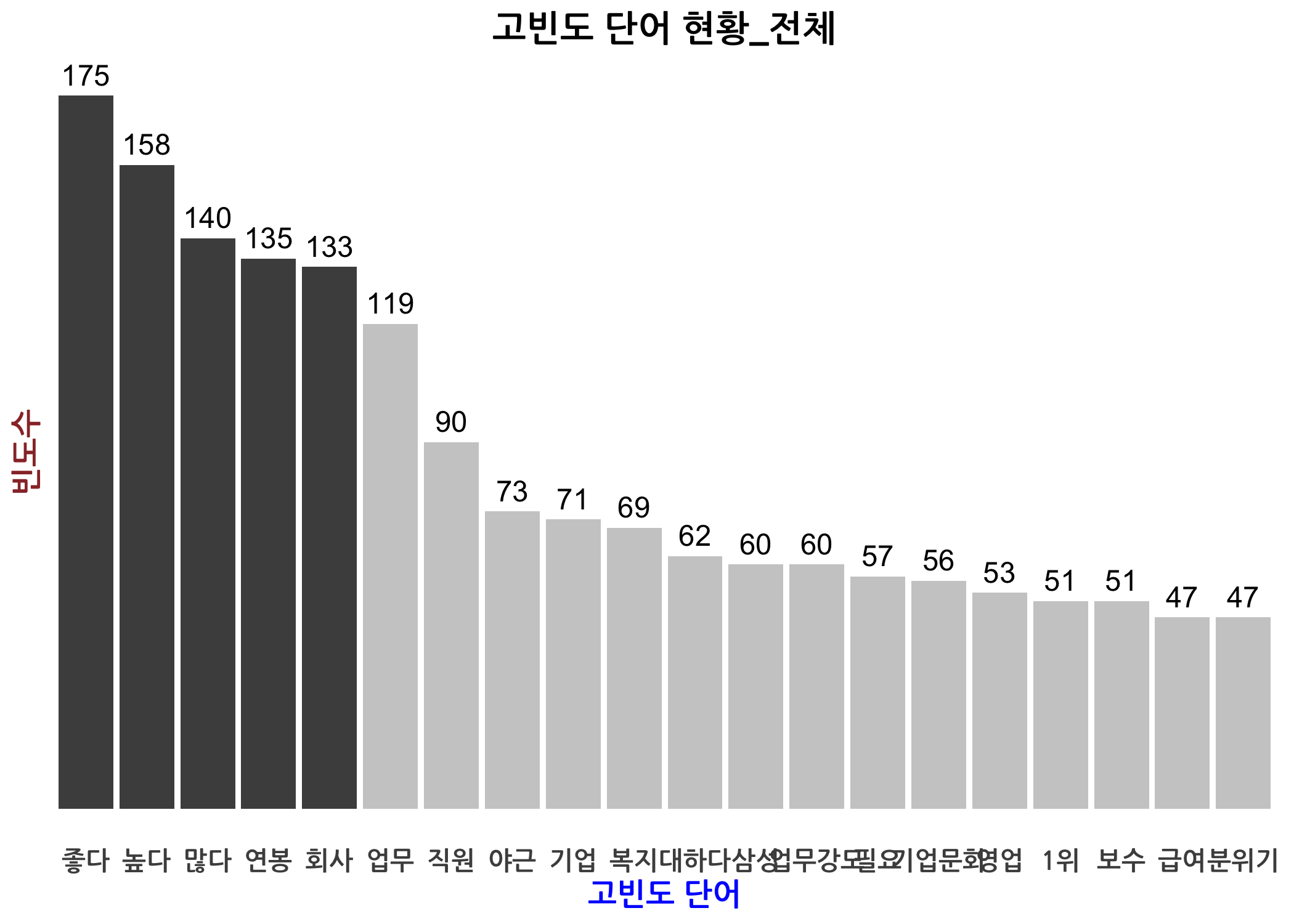
dtm과 dtmTfIdf 객체를 생성하였으므로 고빈도 단어 시각화를 3가지 소개해드리겠습니다. 먼저 상위 20개 단어로 막대그래프를 그린 것입니다. dtm에서 열 합계를 계산한 다음 빈도수 기준으로 내림차순 정렬을 하고 상위 20개만 추출하면 막대그래프를 그릴 준비를 마친 것입니다.
# dtm에 언급된 단어(term)별 빈도수를 생성합니다.
wordsFreq <- dtm %>% as.matrix() %>% colSums()
# 사용된 단어의 총 개수를 확인합니다.
length(x = wordsFreq)
## [1] 605
# 내림차순으로 정렬하고, 상위 20개만 확인합니다.
wordsFreq <- wordsFreq[order(wordsFreq, decreasing = TRUE)]
head(x = wordsFreq, n = 20L)
## 좋다 높다 많다 연봉 회사 업무 직원 야근
## 175 158 140 135 133 119 90 73
## 기업 복지 대하다 삼성 업무강도 필요 기업문화 영업
## 71 69 62 60 60 57 56 53
## 1위 보수 급여 분위기
## 51 51 47 47
# 단어 빈도를 막대그래프로 그리기 위해 데이터 프레임으로 변환한 다음
# 내림차순으로 정렬합니다.
wordDf <- data.frame(
word = names(x = wordsFreq),
freq = wordsFreq,
row.names = NULL) %>%
arrange(desc(x = freq))
# 건수를 확인합니다.
nrow(x = wordDf)
## [1] 605
ggplot() 함수를 이용하여 막대그래프를 그립니다. 그 전에 깔끔한 그래프를 그릴 수 있도록 나만의 테마를 만듭니다.
# ggplot() 함수에 적용할 나만의 테마(mytheme)를 설정합니다.
mytheme <- theme(
plot.title = element_text(size = 14, face = 'bold', hjust = 0.5),
axis.title.x = element_text(color = 'blue', size = 12, face = 'bold'),
axis.title.y = element_text(color = '#993333', size = 12, face = 'bold'),
axis.text.x = element_text(family = 'NanumGothic', size = 10, face = 'bold'),
axis.text.y = element_blank(),
axis.ticks.length = unit(0, 'cm'),
panel.background = element_blank(),
panel.grid = element_blank() )
# 총 빈도수 상위 15개 단어로 막대그래프를 그립니다. (내림차순 정렬)
ggplot(
data = head(x = wordDf, n = 20L),
mapping = aes(
x = reorder(word, -freq),
y = freq)) +
geom_bar(
stat = 'identity',
fill = c(rep(x = 'gray30', times = 5), rep(x = 'gray80', times = 15))) +
geom_text(
mapping = aes(label = freq),
size = 4,
vjust = -0.5) +
labs(
x = '고빈도 단어',
y = '빈도수',
title = '고빈도 단어 현황_전체') +
mytheme
이번에는 아주 유명한 텍스트 시각화 기법 중 하나인 단어 구름(Word Cloud)를 생성해보겠습니다. 단어의 색을 예쁘게 하기 위해 파스텔 색상으로 나만의 팔레트를 만들고 빈도수가 높은 단어에 색을 적용하도록 하겠습니다.
# 필요한 패키지를 불러옵니다.
library(RColorBrewer)
library(wordcloud2)
library(htmlwidgets)
# 나만의 팔레트를 설정합니다. (n:사용할 색깔 수, name:색깔 조합 이름)
display.brewer.pal(n = 8, name = 'Set2')
pal <- brewer.pal(n = 8, name = 'Set2')
# http://colorbrewer2.org/ 참고
# 워드클라우드에 적용할 데이터의 길이를 최대 300건으로 제한합니다.
# 이 숫자가 넘어가면 워드클라우드가 예쁘게 그려지지 않습니다.
if (nrow(x = wordDf) >= 300) wordCloud <- wordDf[1:300, ] else wordCloud <- wordDf
# Wordcloud를 그립니다.
wordcloud2(
data = wordCloud,
size = 0.8,
fontFamily = 'NanumGothic',
color = pal,
backgroundColor = 'white',
minRotation = -pi / 4,
maxRotation = pi / 4,
shuffle = TRUE,
rotateRatio = 0.25,
shape = 'circle',
ellipticity = 0.6)

세 번째 그래프는 트리맵입니다. 사실 별 거 아니지만 단어 빈도수가 높은 순서대로 네모 칸의 크기를 다르게 하여 고빈도 단어들을 한 눈에 파악할 수 있도록 한 것입니다.
# 필요한 패키지를 불러옵니다.
library(treemap)
# 고빈도 단어 트리맵을 그립니다.
treemap(
dtf = wordDf,
title = '고빈도 단어 트리맵',
index = c('word'),
vSize = 'freq',
fontfamily.labels = 'NanumGothic',
fontsize.labels = 14,
palette = pal,
border.col = 'white')

단어 연관성 분석
이번에는 특정 단어와 함께 출현하는 빈도가 높은, 연관성 높은 단어를 추출하는 방법에 대해서 알아보겠습니다. 모두에 말씀드린 바와 같이 저는 3가지 방법을 사용하는데요. 이번 포스팅에서는 2가지만 소개하겠습니다. 둘 다 간단합니다.
첫 번째 방법은 dtmTfIdf 객체를 행렬로 변환한 다음 상관(계수) 행렬을 구하는 걸로 거의 모든 것이 끝납니다. 그리고 나서 특정 단어가 속한 컬럼을 뽑아 행렬 원소를 내림차순으로 정렬하면 끝납니다. 아래는 고빈도 단어 중 명사 위주로 관심 있는 몇 가지에 대해 상위 10개씩 확인해본 것입니다.
# 상관계수 행렬을 직접 생성합니다.
corTerms <- dtmTfIdf %>% as.matrix() %>% cor()
# 차원을 확인합니다.
dim(x = corTerms)
## [1] 598 598
# 상관계수 행렬로 연관성 높은 단어를 확인합니다.
checkCorTerms <- function(n = 10, keyword) {
# 키워드 유무를 확인합니다.
corTerms %>%
colnames() %>%
str_subset(pattern = keyword) %>%
print()
# 연관 키워드가 있는 컬럼의 전체 단어를 한꺼번에 출력합니다.
corRef <- data.frame()
# 상관계수 높은 순서로 정렬합니다.
corRef <- corTerms[ , keyword] %>%
sort(decreasing = TRUE) %>%
data.frame() %>%
set_colnames(c('corr'))
# 미리보기 합니다.
head(x = corRef, n = n + 1)
}
# 빈도수 높은 단어 중 관심 있는 명사 위주로 확인합니다.
checkCorTerms(n = 10, keyword = '연봉')
## [1] "연봉"
## corr
## 연봉 1.0000000
## 상승 0.3024012
## 높다 0.3007580
## 해결 0.2232224
## 상당 0.2172382
## 인식 0.1951647
## 각오 0.1802804
## 커리어 0.1726297
## 맡다 0.1715646
## 브랜드 0.1652702
## 자기 0.1599896
checkCorTerms(n = 10, keyword = '야근')
## [1] "야근" "야근수당"
## corr
## 야근 1.0000000
## 잦다 0.4773754
## 일상 0.2983263
## 가정 0.2503515
## 기본 0.2398341
## 필수 0.2285899
## 쎄다 0.2266016
## 기업문화 0.2265103
## 이익 0.2259482
## 과도하다 0.2215771
## 기본급 0.2192393
checkCorTerms(n = 10, keyword = '삼성')
## [1] "삼성" "삼성그룹" "삼성화재"
## corr
## 삼성 1.0000000
## 자부심 0.3204171
## 타이틀 0.2773458
## 근무시간 0.2634302
## 자랑 0.2251222
## 상당 0.2109360
## 마감 0.2067216
## 나아지다 0.1919994
## 조절 0.1815198
## 압박 0.1761186
## 금융업 0.1759662
checkCorTerms(n = 10, keyword = '업무강도')
## [1] "업무강도"
## corr
## 업무강도 1.0000000
## 세다 0.3707511
## 높다 0.3550106
## 조절 0.3210592
## 높이다 0.2888525
## 강하다 0.2673936
## 낮추다 0.2421293
## 저녁 0.2073970
## 느끼다 0.2046691
## 바라다 0.1947416
## 교육기회 0.1897041
checkCorTerms(n = 10, keyword = '기업문화')
## [1] "기업문화"
## corr
## 기업문화 1.0000000
## 유연하다 0.3502078
## 잦다 0.3384624
## 단순 0.3172063
## 보수 0.3013308
## 경직 0.2981385
## 양립 0.2934218
## 바꾸다 0.2889535
## 개선 0.2755130
## 딱딱하다 0.2719651
## 이외 0.2719651
checkCorTerms(n = 10, keyword = '분위기')
## [1] "분위기"
## corr
## 분위기 1.0000000
## 차별 0.3143072
## 대우 0.2700052
## 자유 0.2649019
## 체계 0.2559453
## 나가다 0.2460992
## 키우다 0.2065264
## 전문가 0.2043906
## 재무구조 0.2009425
## 수직 0.1970148
## 사용 0.1969903
checkCorTerms(n = 10, keyword = '스트레스')
## [1] "스트레스"
## corr
## 스트레스 1.0000000
## 낮다 0.3046307
## 빼다 0.2740408
## 실질 0.2669483
## 여유 0.2399733
## 교육기회 0.2307128
## 시급 0.2293218
## 관리직 0.2274678
## 금전 0.2268050
## 급여 0.2243942
## 직무순환 0.2203238
checkCorTerms(n = 10, keyword = '자부심')
## [1] "자부심"
## corr
## 자부심 1.0000000
## 삼성 0.3204171
## 포화상태 0.3185390
## 타이틀 0.2904761
## 자랑 0.2679928
## 보험업 0.2641174
## 해외진출 0.2542467
## 업계 0.2470959
## 단순 0.2133139
## 경직 0.2098528
## 줏다 0.2070730
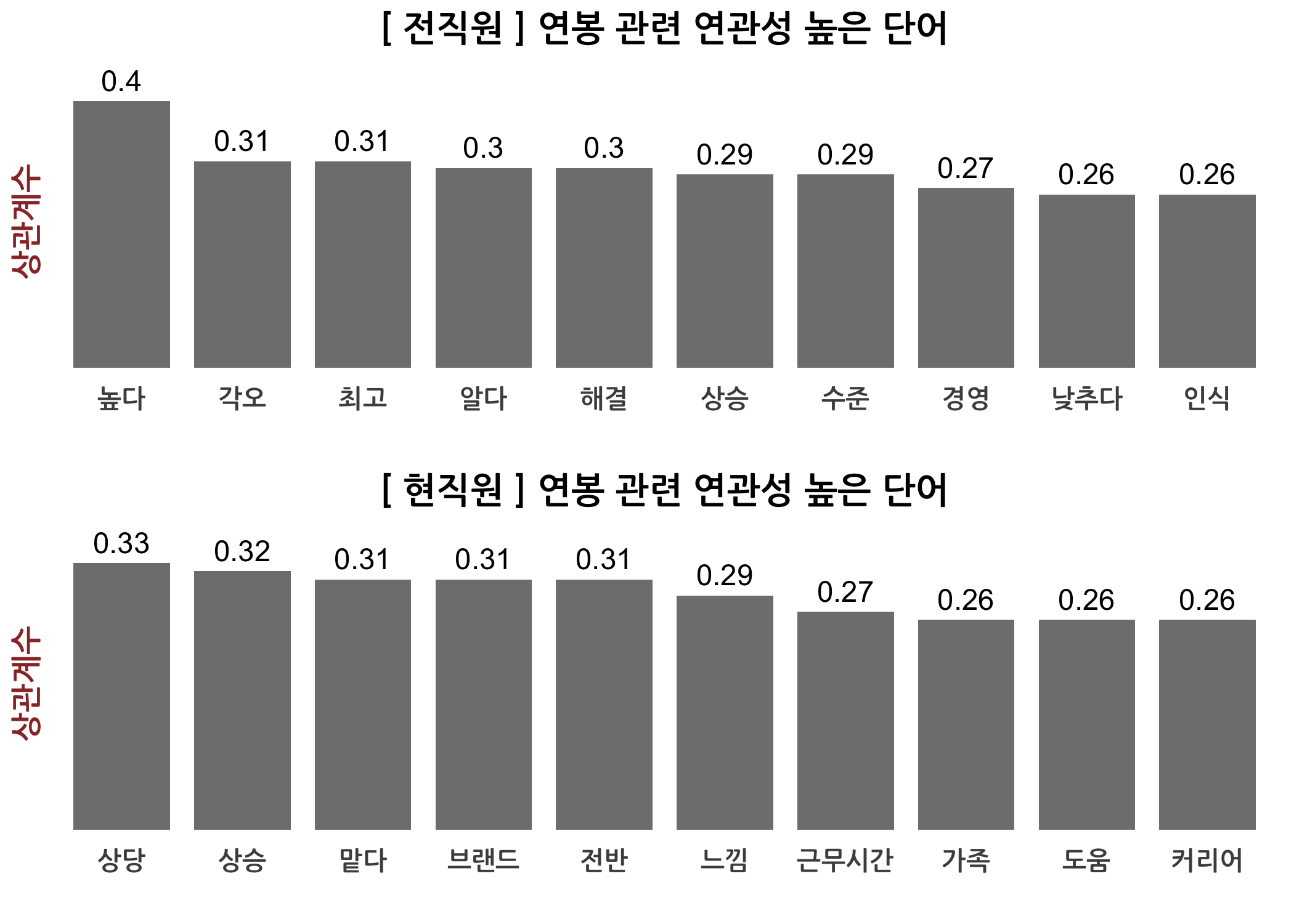
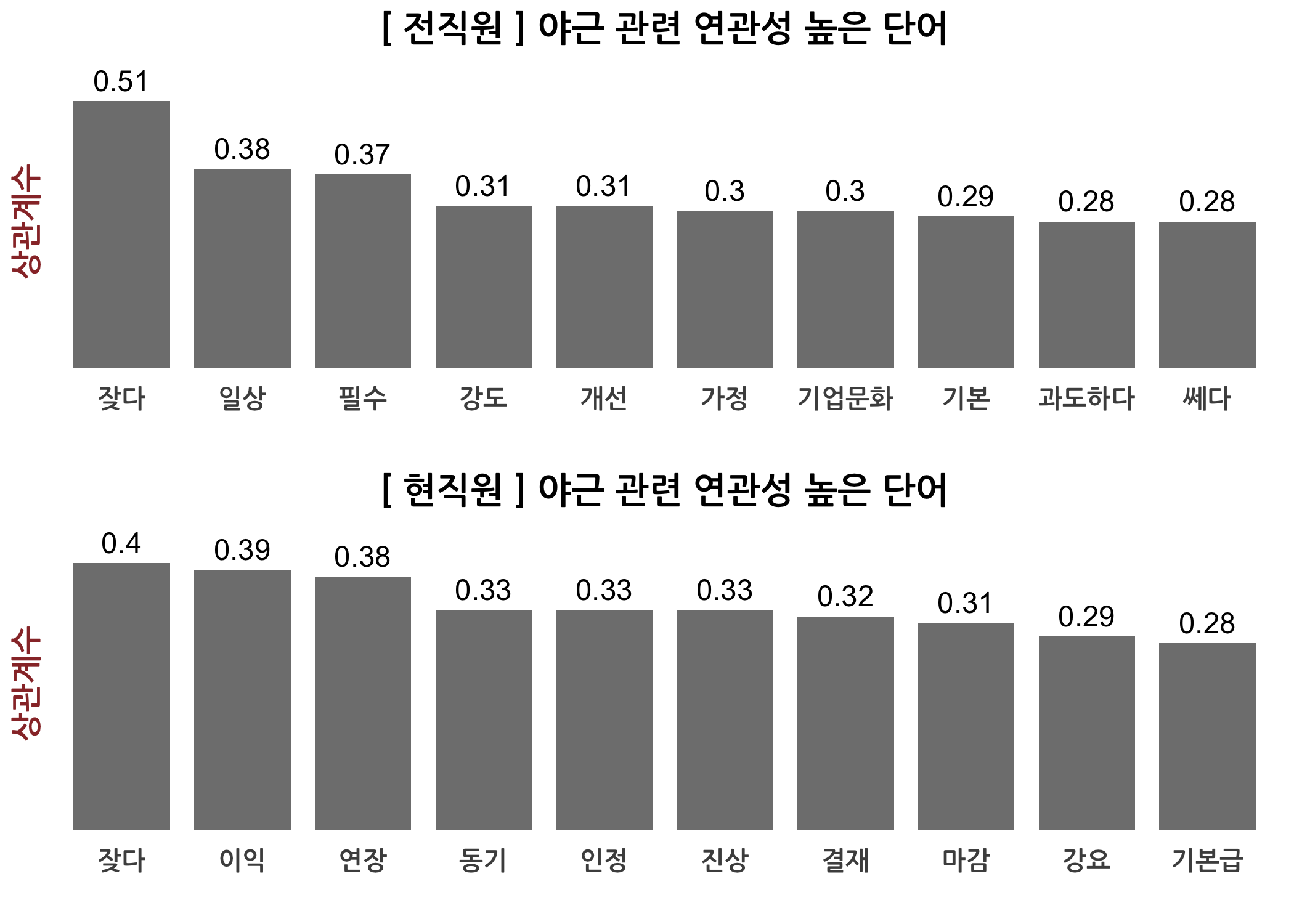
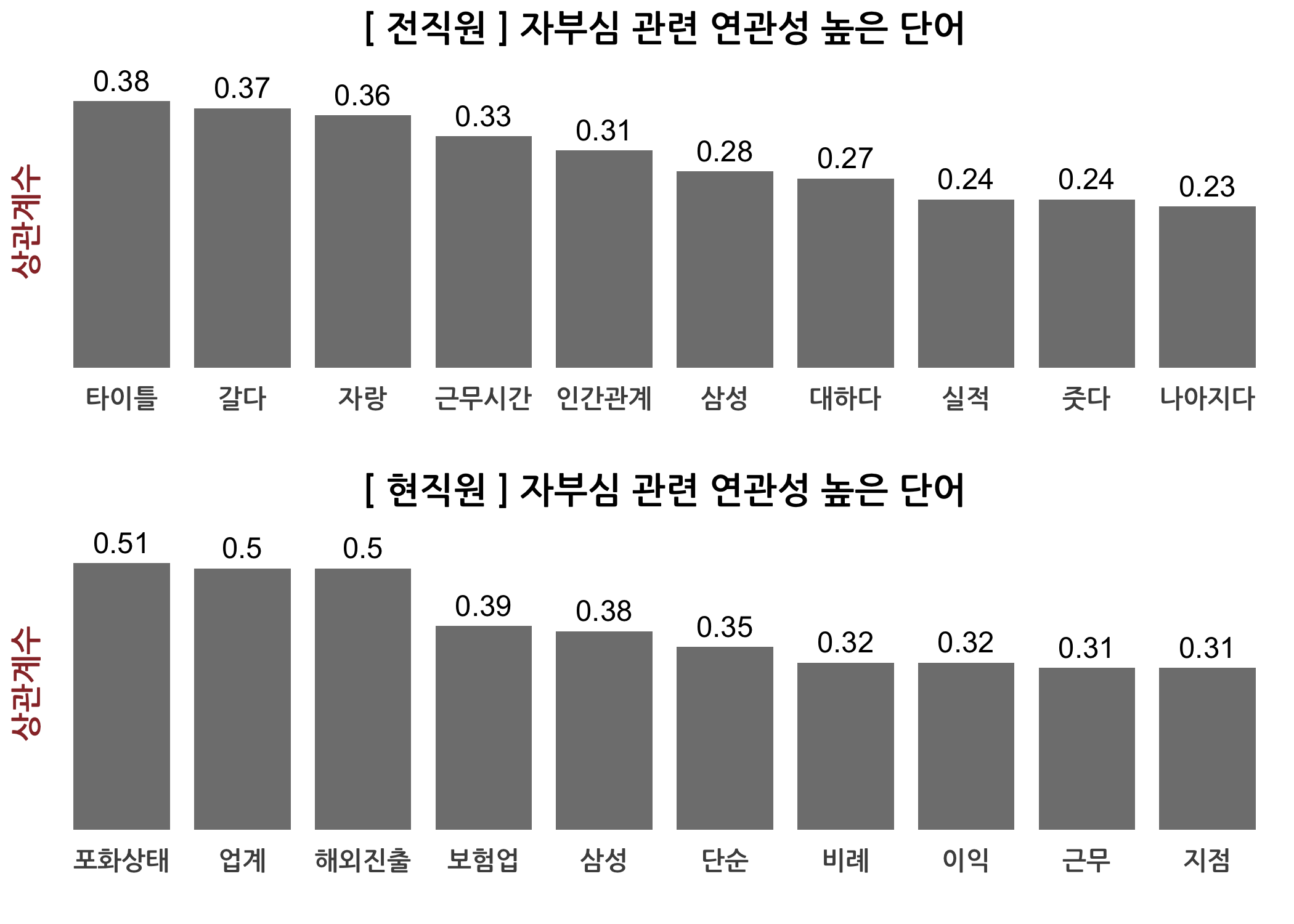
단어 연관성 분석의 두 번째 방법은 tm 패키지의 findAssocs() 함수를 하용하는 것입니다. 이 함수에 상관계수 행렬과 관심 있는 단어, 그리고 상관계수 기준점만 지정하면 알아서 결과를 제시합니다. 저는 연관성 단어를 추출하고 이것을 재직상태별로 나누어 막대그래프로 표현해보고자 아래와 같이 사용자 정의 함수를 만들었습니다. 전직원과 현직원 간 인식의 차이를 보이는 단어가 보이나요?
# tm 패키지의 findAssocs() 함수 이용하여 상관계수 높은 단어를 확인할 수 있습니다.
# 상관계수가 기준 이상인 단어들만 추출합니다.
checkAssocs <- function(dtm, keyword, corr = 0.01) {
# 재직상태별 상관계수를 생성하고 데이터 프레임에 저장합니다.
createDtmObj <- function(dtm, workGb, n = 10) {
# 전직원/현직원별로 dtm을 나눕니다.
dtmSmp <- dtm[rownames(x = dtm) %in% texts$id[texts$재직상태 == workGb], ]
# 상관계수가 높은 단어만 저장합니다.
assocs <- findAssocs(x = dtmSmp, terms = keyword, corlimit = corr)
# 재직상태별 상관계수로 데이터 프레임을 생성합니다.
dtmObj <- eval(expr = parse(text = str_c('assocs', keyword, sep = '$'))) %>%
`[`(1:n) %>%
as.data.frame() %>%
set_colnames('corr')
# 행이름으로 word 컬럼을 생성합니다.
dtmObj$word <- rownames(x = dtmObj)
# 행이름을 삭제합니다.
rownames(x = dtmObj) <- NULL
# workGb 컬럼을 생성합니다.
dtmObj$workGb <- workGb
# 결과를 반환합니다.
return(dtmObj)
}
# 행 기준으로 붙여서 dtmObj를 생성합니다.
dtmObj <- rbind(createDtmObj(dtm = dtm, workGb = '전직원'),
createDtmObj(dtm = dtm, workGb = '현직원'))
# 막대그래프 리스트를 생성합니다.
plots <- lapply(X = split(x = dtmObj, f = dtmObj$workGb), FUN = function(x) {
# 단어의 순서를 상관계수 역순으로 재조정합니다.
x$word <- factor(x = x$word, levels = x$word[order(x$corr, decreasing = TRUE)])
# 막대그래프를 설정합니다.
ggplot(data = x,
mapping = aes(
x = word,
y = corr,
width = 0.8)) +
geom_col(fill = 'gray50') +
geom_text(mapping = aes(label = corr),
size = 4,
vjust = -0.5) +
scale_y_continuous(limits = c(0, max(x$corr)*1.1 )) +
labs(x = '',
y = '상관계수',
title = str_c('[', unique(x$workGb), ']',
keyword,
'관련 연관성 높은 단어',
sep = ' ')) +
theme(legend.position = 'none') + mytheme
})
# 2행으로 그래프를 그립니다.
do.call(what = gridExtra::grid.arrange, args = c(plots, nrow = 2))
}
# 재직상태별 상관계수 높은 단어들을 확인합니다.
checkAssocs(dtm = dtmTfIdf, keyword = '연봉')
checkAssocs(dtm = dtmTfIdf, keyword = '야근')
checkAssocs(dtm = dtmTfIdf, keyword = '삼성')
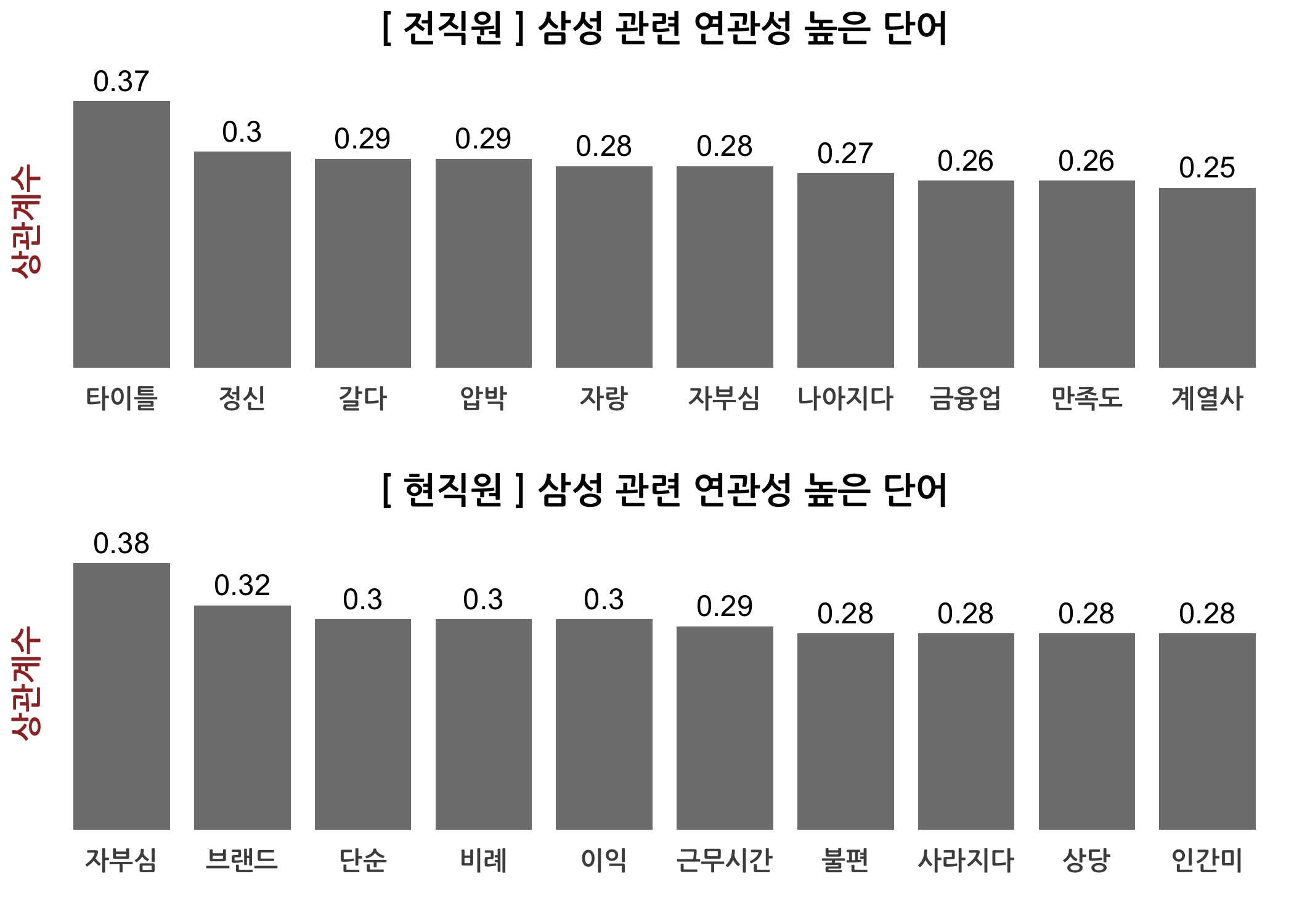
checkAssocs(dtm = dtmTfIdf, keyword = '업무강도')
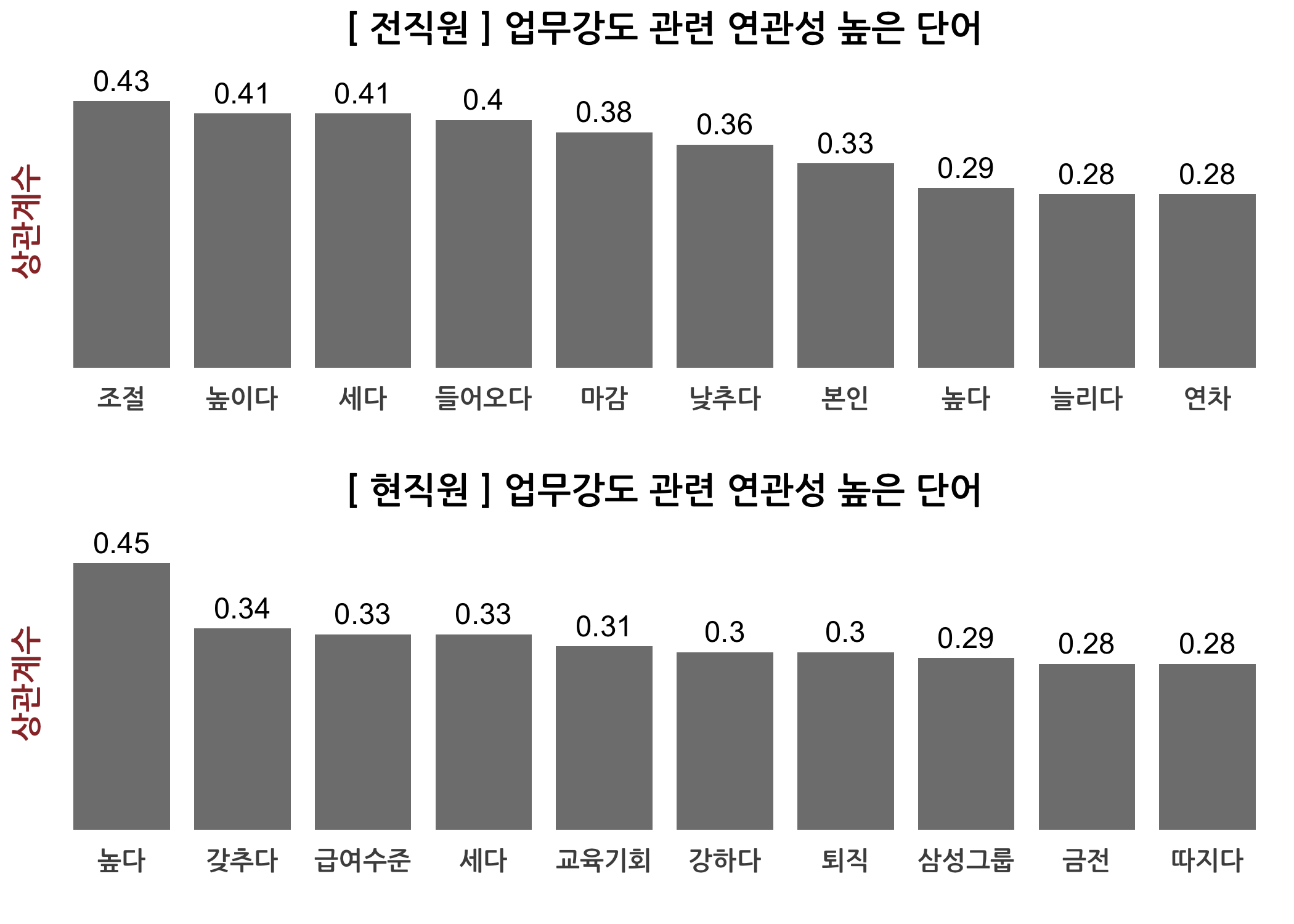
checkAssocs(dtm = dtmTfIdf, keyword = '기업문화')
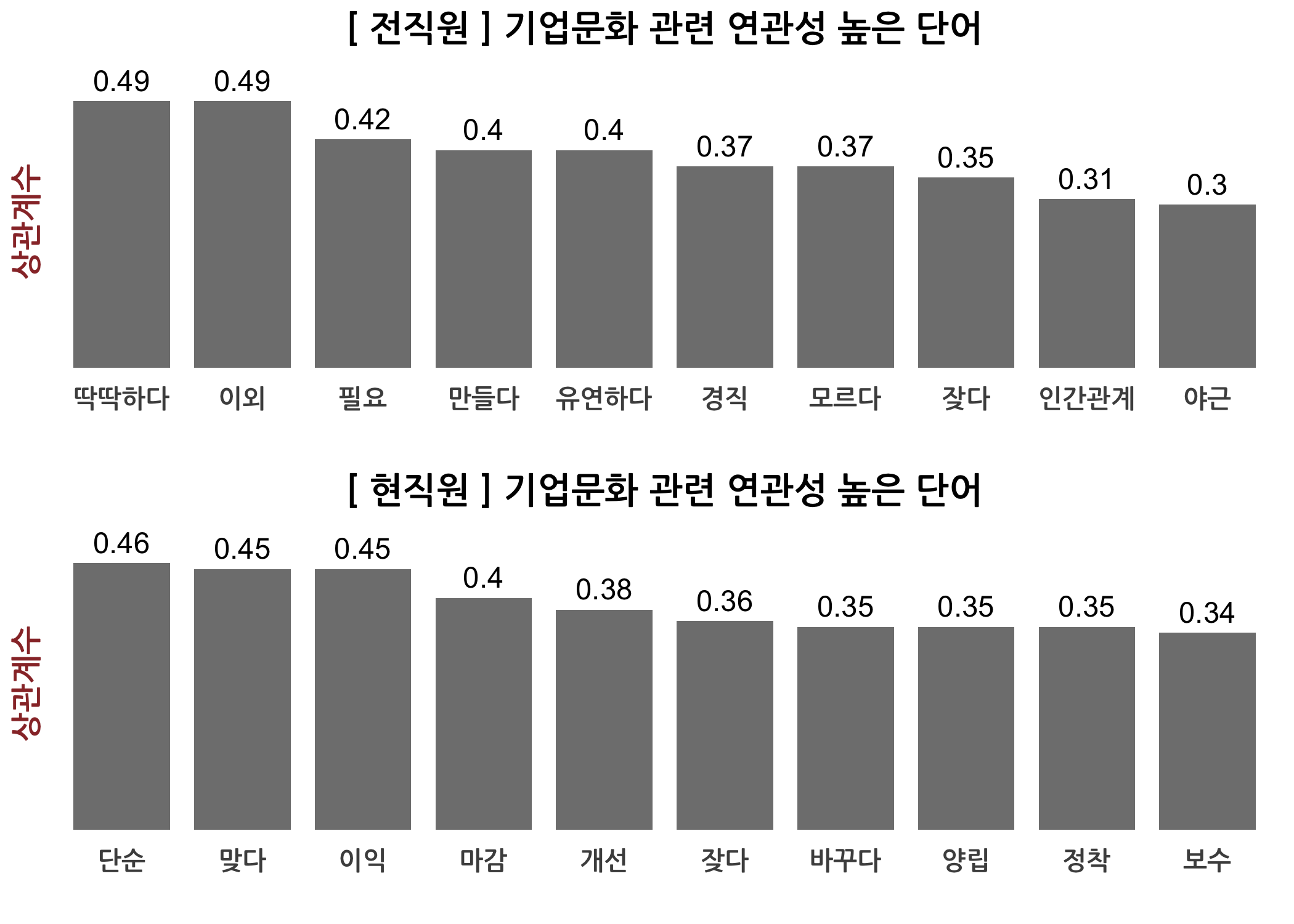
checkAssocs(dtm = dtmTfIdf, keyword = '분위기')
checkAssocs(dtm = dtmTfIdf, keyword = '스트레스')
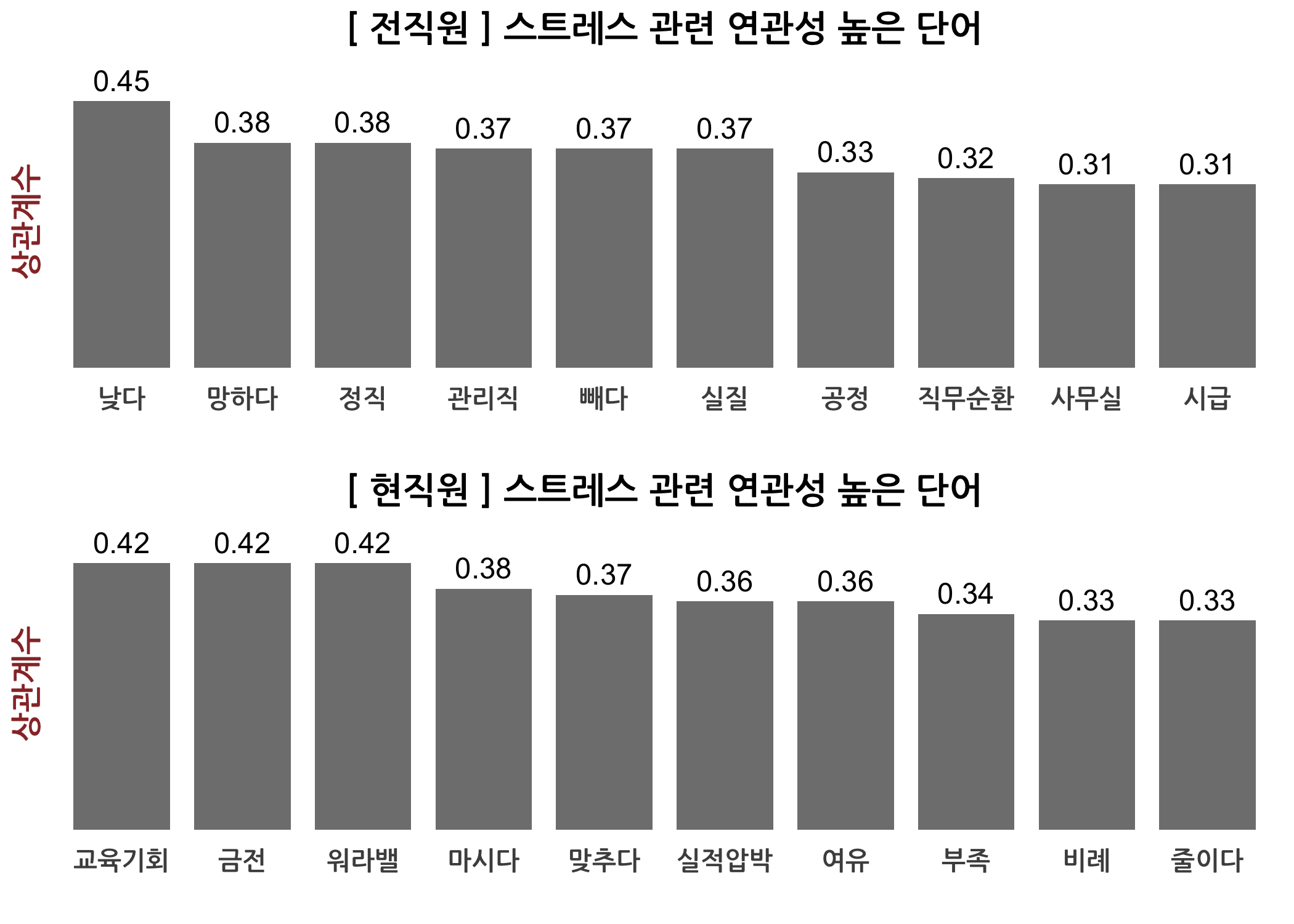
checkAssocs(dtm = dtmTfIdf, keyword = '자부심')
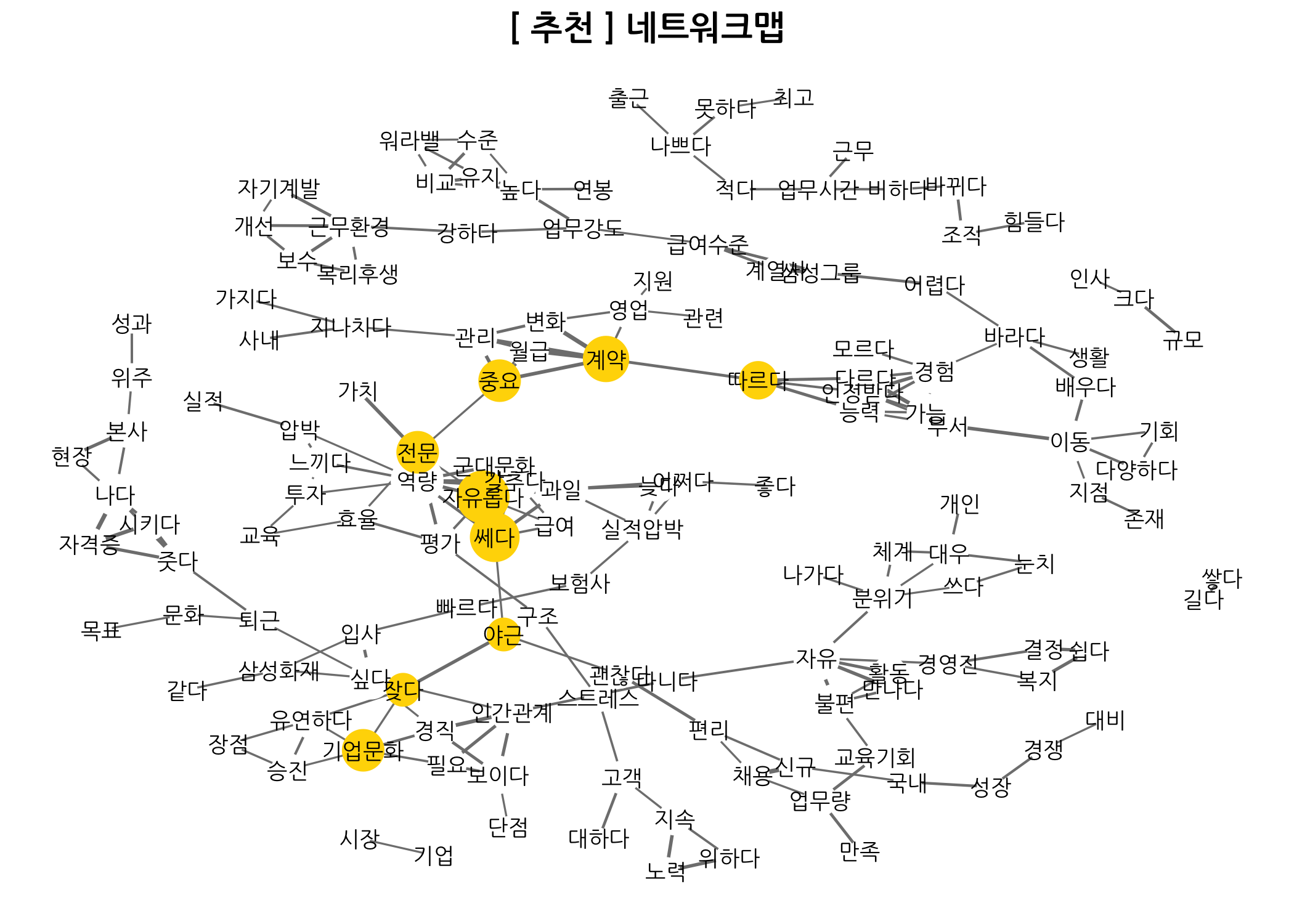
네트워크 맵 그리기
이번 포스팅의 마지막 꼭지는 네트워크 맵 그리기입니다. dtm이나 dtmTfIdf로 상관계수 행렬을 만들고 네트워크 객체를 생성한 다음 각 단어별로 매개 중심성(Betweenness Centrality)을 계산합니다. 매개 중심성은 네트워크에서 노드 간 최단 연결고리에 속하는지 여부로 결정됩니다. 숫자가 클수록 각각의 노드를 연결하는 중심에 있다는 것이죠. 이 외에 연결 중심성(Degree Centrality)도 중요합니다. 각 노드마다 연결된 엣지의 수가 다를텐데요. 이 엣지의 수가 많을수록 연결되어 있는 노드가 많다는 의미입니다. 이건 쉽죠?
아래는 매개 중심성 상위 10%에 해당하는 노드를 금색으로 색칠하고 각 노드를 연결하는 엣지는 상관계수의 1.2배로 설정했습니다. 상관계수가 높을수록 연결된 선이 굵게 표시됩니다.
# 필요한 패키지를 불러옵니다.
library(network)
library(GGally)
# 네트워크 맵을 그리는 사용자 정의 함수를 생성합니다.
drawNetworkmap <- function(dtmObj, title, sparse, corr, prob, link, cex) {
# 상관계수 행렬의 크기를 조정합니다.
corTerms <- dtmObj %>% as.matrix() %>% cor()
corTerms[corTerms <= corr] <- 0
# 네트워크 객체를 생성합니다.
netTerms <- network(x = corTerms, directed = FALSE)
# 매개 중심성을 계산합니다.
btnTerms <- sna::betweenness(dat = netTerms)
netTerms %v% 'mode' <-
ifelse(
test = btnTerms >= quantile(x = btnTerms, probs = prob, na.rm = TRUE),
yes = 'Top',
no = 'Rest')
# 노드 컬러를 지정합니다.
# 상위 10%는 금색, 나머지 90%는 흰색으로 설정합니다.
nodeColors <- c('Top' = 'gold', 'Rest' = 'white')
# 엣지 크기를 지정합니다. 이번 예제에서는 상관계수의 1.2배로 합니다.
set.edge.value(x = netTerms, attrname = 'edgeSize', value = corTerms * 1.2)
# 네트워크 지도를 그립니다.
ggnet2(
net = netTerms,
mode = 'fruchtermanreingold',
layout.par = list(cell.jitter = 0.001),
size.min = link,
label = TRUE,
label.size = cex,
node.color = 'mode',
palette = nodeColors,
node.size = sna::degree(dat = netTerms),
edge.size = 'edgeSize',
legend.position = 'None',
family = 'NanumGothic') +
labs(title = title) +
theme(plot.title = element_text(hjust = 0.5, face = 'bold'))
}
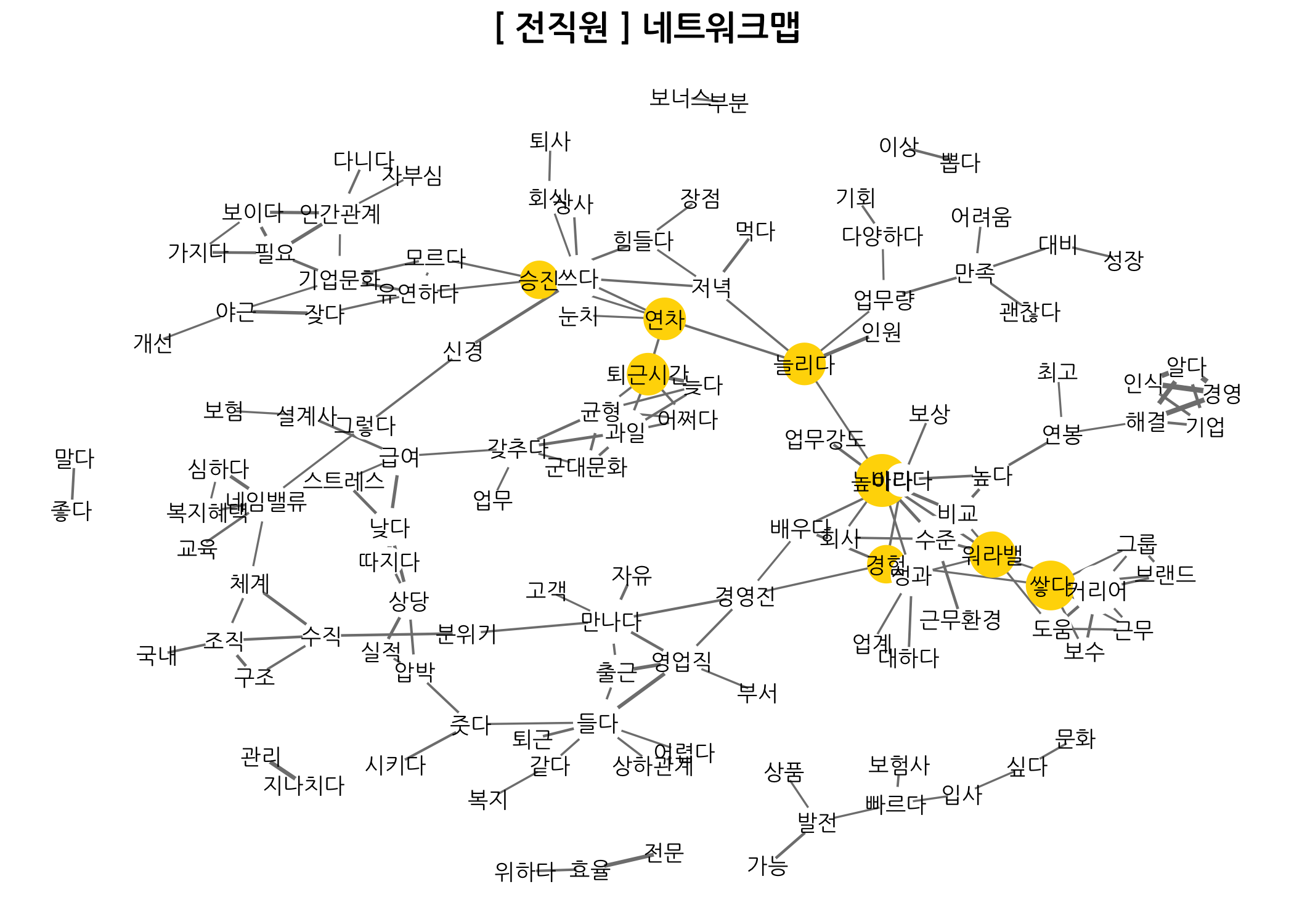
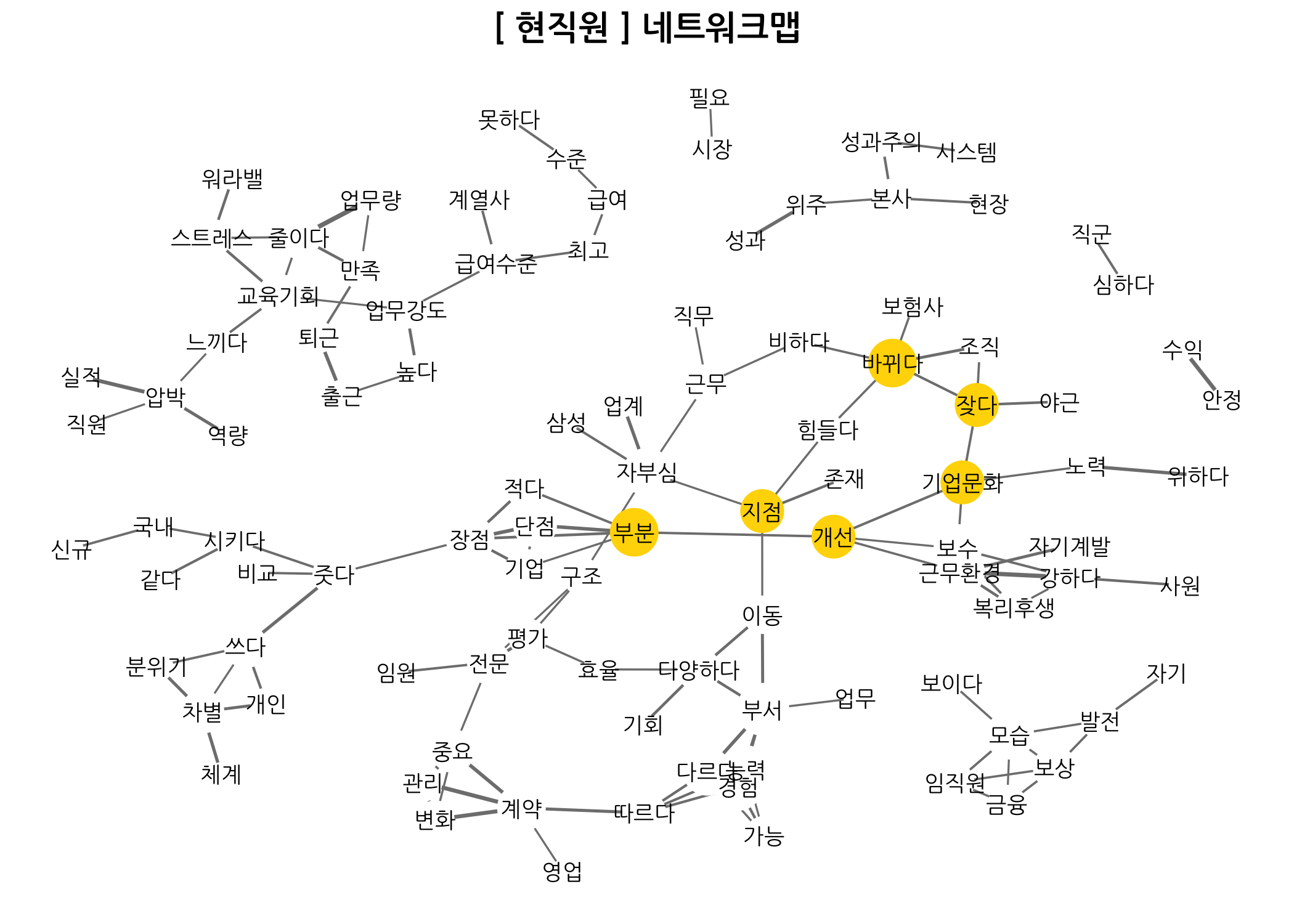
위와 같이 네트워크 맵을 그리는 사용자 정의 함수를 만들었다면, 이제 네트워크 맵을 그려보겠습니다. 먼저 재직상태별로 네트워크 맵을 그리는 것입니다. 네트워크 맵을 그리면 전체 문서에서 자주 출현하는 단어 간 연결고리를 확인할 수 있습니다. 마치 글을 읽듯이 자연스러운 부분을 발견할 수 있는데요. 예를 들면 실적 - 압박 - 상당을 들 수 있습니다. **보험 - 설계사 - 급여 - 낮다 **도 바로 붙어 있네요. 이런 식으로 네트워크 맵에 있는 연결고리를 찾는 재미가 있습니다. 동시에 이런 걸 찾으려면 힘이 들기도 하겠군요.
# 재직상태별 네트워크 맵을 그리는 함수를 생성합니다.
dt4Networkmap1 <- function(workGb, sparse, corr, prob = 0.95, link = 4, cex = 4) {
# 입력조건에 따라 dtm을 선택합니다.
checks <- texts$재직상태 == workGb
dtmSub <- dtmTfIdf[rownames(x = dtmTfIdf) %in% texts$id[checks], ]
# 모든 값이 0인 열을 삭제합니다.
dtmSub <- dtmSub[, as.matrix(x = dtmSub) %>% colSums() >= 1]
# 그래프 제목을 설정합니다.
title <- str_c('[', workGb, '] 네트워크맵', sep = ' ')
# 네트워크 맵을 그립니다.
drawNetworkmap(dtmObj = dtmSub, title, sparse, corr, prob, link, cex)
}
# 재직상태별 네트워크 맵을 그립니다.
dt4Networkmap1(workGb = '전직원', sparse = 0.95, corr = 0.30, link = 2, cex = 3)
dt4Networkmap1(workGb = '현직원', sparse = 0.95, corr = 0.30, link = 2, cex = 3)
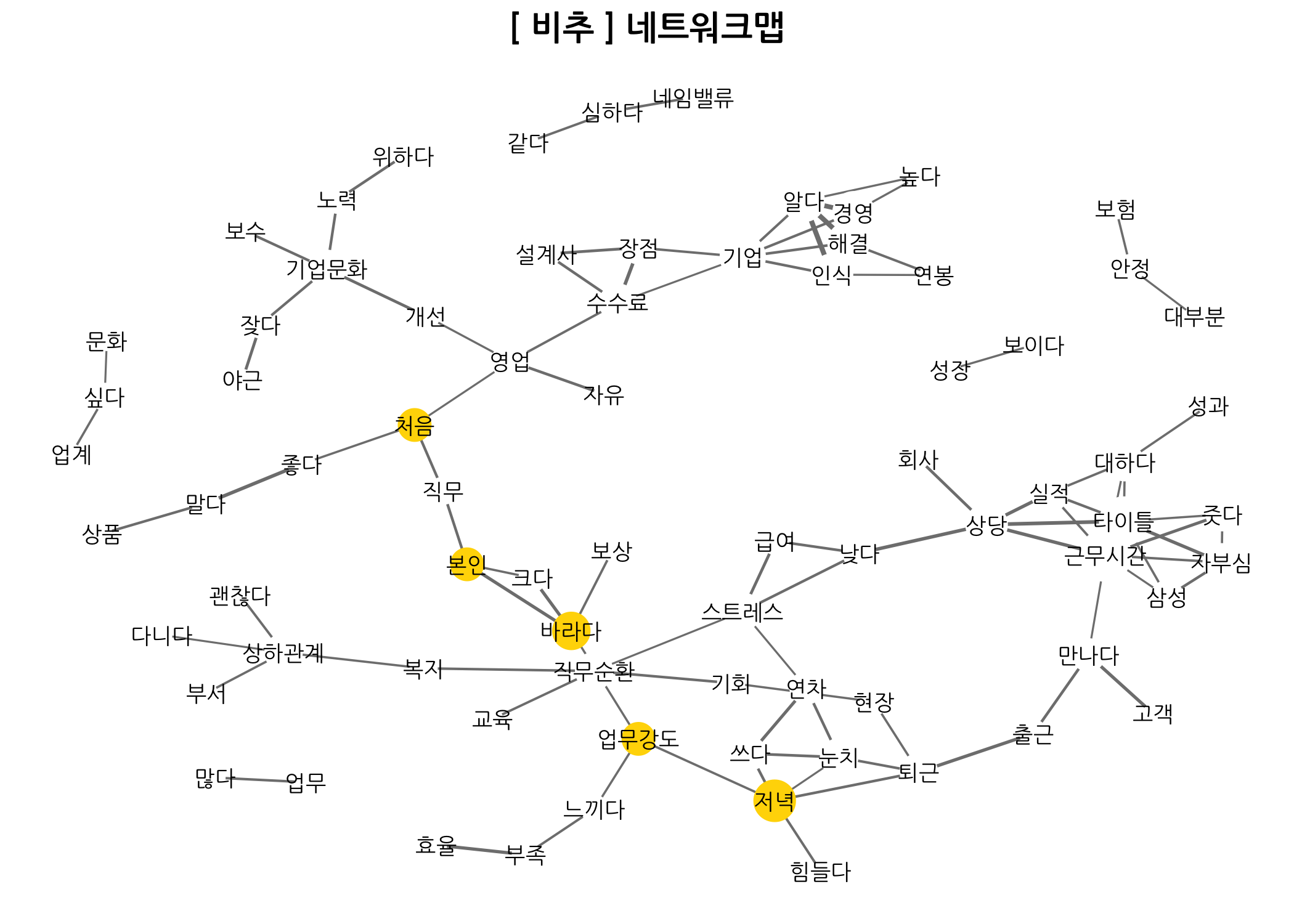
기업리뷰를 남긴 회원의 추천 여부에 따른 네트워크 맵을 비교할 수도 있습니다. 비추 네트워크 맵을 보면 처음 - 좋다 - 말다라는 문구가 보이네요. 야근 - 잦다 - 기업문화 - 개선이라는 것도 보이구요. 데이터가 좋으면 이런 부분을 쉽게 찾을 수 있는 것 같습니다.
# 추천 여부별 네트워크 맵을 그리는 함수를 생성합니다.
dt4Networkmap2 <- function(recomm, sparse, corr, prob = 0.95, link = 4, cex = 4) {
# 입력조건에 따라 dtm을 선택합니다.
checks <- texts$추천여부 == recomm
dtmSub <- dtmTfIdf[rownames(x = dtmTfIdf) %in% texts$id[checks], ]
# 모든 값이 0인 열을 삭제합니다.
dtmSub <- dtmSub[, as.matrix(x = dtmSub) %>% colSums() >= 1]
# 그래프 제목을 설정합니다.
title <- str_c('[', recomm, '] 네트워크맵', sep = ' ')
# 네트워크 맵을 그립니다.
drawNetworkmap(dtmObj = dtmSub, title, sparse, corr, prob, link, cex)
}
# 재직상태별 네트워크 맵을 그립니다.
dt4Networkmap2(recomm = '추천', sparse = 0.90, corr = 0.30, link = 2, cex = 3)
dt4Networkmap2(recomm = '비추', sparse = 0.90, corr = 0.30, link = 2, cex = 3)
이상으로 부족한 부분이 많지만 텍스트 마이닝 부분까지 모두 소개해드렸습니다. 질문이나 지적사항 모두 환영합니다. 많은 관심 부탁드립니다.