
Naver Papago Api를 활용한 Nmt 번역
네이버 API 활용법 #1
Dr.Kevin 04/17/2019
지난 포스팅에서 다음 지도 API를 소개해드린 이후로 정확하게 2달이 지났습니다. 백수가 과로사한다는 말은 진리입니다.
이번 포스팅에서는 네이버 파파고 API를 이용하여 영문을 한글로 번역해보는 방법에 대해 알아보겠습니다. 일단 결론부터 말씀드리면 파파고의 영한 번역 또는 한영 번역은 품질이 우수한 것으로 보이지만, (실제로 이 작업을 하려고 했던 원래 목적인) 베트남어-한글 번역은 잘 모르겠습니다. 그리고 하루에 번역할 수 있는 글자수 한도가 1만 글자 밖에 안 됩니다. 1만 글자라 얼핏 드는 생각으로는 많을 것 같지만 실제로 해보시면 별로 많지 않다는 것을 금세 깨닫게 될 것입니다. 시작합니다!
네이버 개발자센터에서 본인 등록
아직까지 한 번도 네이버 API를 이용해보지 않은 분들을 위해 어디서 어떻게 해야 네이버 API에 등록할 수 있는지 소개해드리겠습니다. 먼저 네이버 개발자센터로 이동합니다. 그러면 아래와 같은 웹 페이지가 열립니다. 오른쪽 위 검정색 로그인 버튼이 보이죠? 여기에서 본인의 네이버 아이디와 비밀번호로 로그인 합니다.
로그인을 하고 나서 가장 처음에 해야 할 일은 상단의 메뉴의 Application > 계정 설정을 클릭하여 본인인증을 하는 것입니다.

환영합니다로 시작하는 alert에 확인을 클릭해주고, 이용약관에 동의합니다에 체크한 다음 확인을 클릭하면, 본인 인증 페이지로 넘어갑니다.
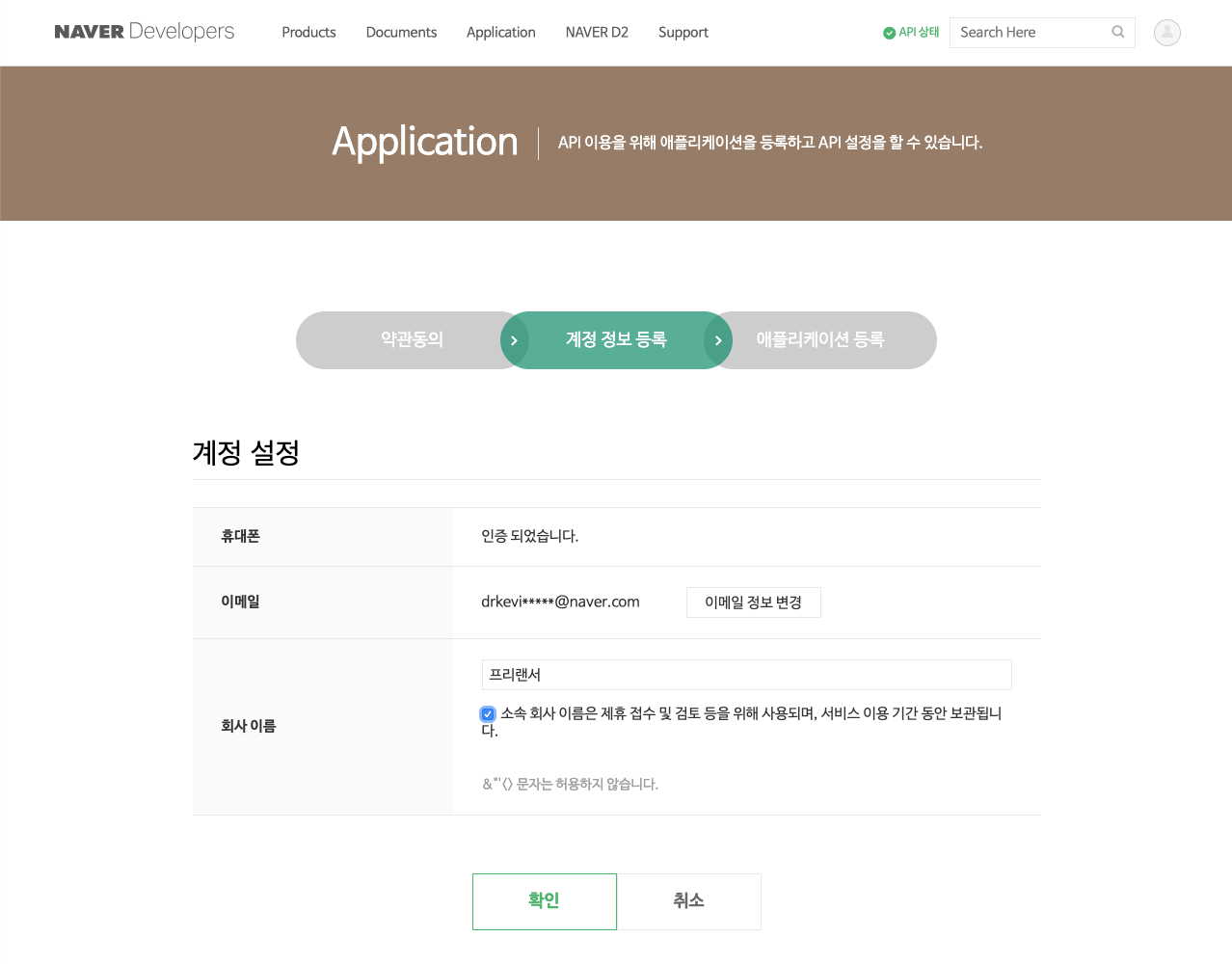
저는 백수 알바 강사이지만 프리랜서라는 좀 더 고급진 표현을 선택했습니다. 그 아래 체크박스를 선택하고 확인을 누르면 마지막 과정인 애플리케이션 등록으로 넘어갑니다.
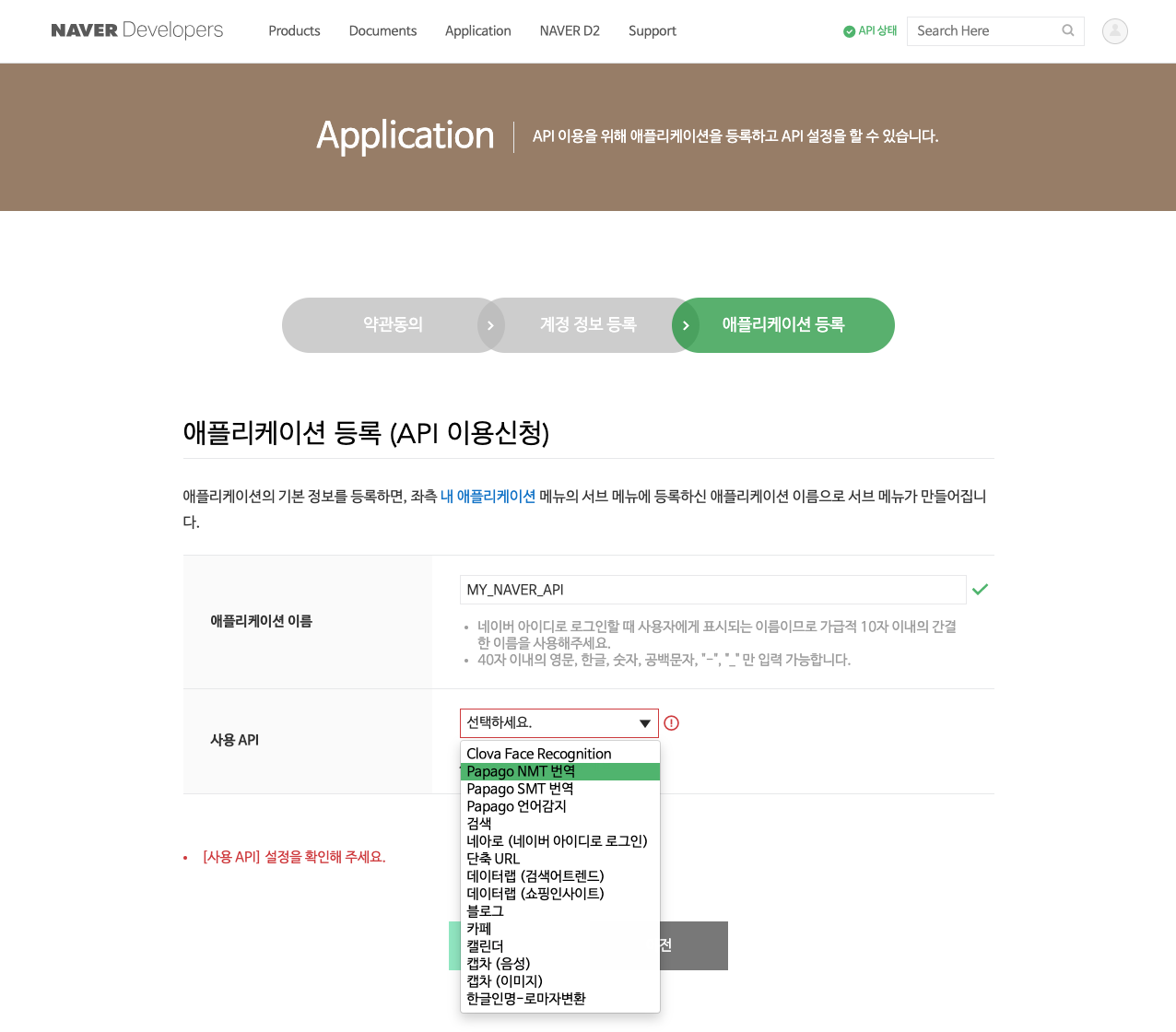
아래 이미지를 보시면 애플리케이션 이름과 사용 API를 입력하는 창이 있습니다. 애플리케이션 이름은 알아서 예쁜 이름으로 추가해주시면 됩니다. 중복 체크를 하지 않으니 마음에 드는 이름으로 입력하면 되구요. 사용 API는 Papago NMT 번역을 선택하도록 하겠습니다. Papago 번역 서비스가 2개인데요. NMT는 Neural Machine Translation의 머리글자로 인공신경망을 활용한, 그러니까 딥러닝 기반의 번역 서비스인 것 같습니다. 참고로 SMT는 Statistical Machine Translation의 머리글자로 통계 기반의 번역 기술이구요. 그래서 속도가 빠르고 번역할 수 있는 어휘 수가 많아서 신조어 번역에 장점을 갖는다라고 설명되어 있습니다.
다시 본론으로 돌아와서, 예전과 다르게 네이버 API가 좀 더 편리해졌다고 느껴지는 지점은 하나의 애플리케이션에 네이버에서 제공하는 모든 API를 담을 수 있다는 점입니다. 자주 사용하다보면 자연스럽게 알게 될 것이라 생각이 됩니다만, 아래 캡쳐 이미지에서 사용 API를 선택할 때 여러 API 목록이 뜬다는 것입니다. 그래서 필요한 API를 추가로 선택하면 하나의 애플리케이션으로, 그러니까 하나의 네이버 API ID와 PW로 서비스 이용이 가능하다는 점이죠. 다른 API가 필요한 분은 여러 개의 API를 선택하셔도 됩니다.
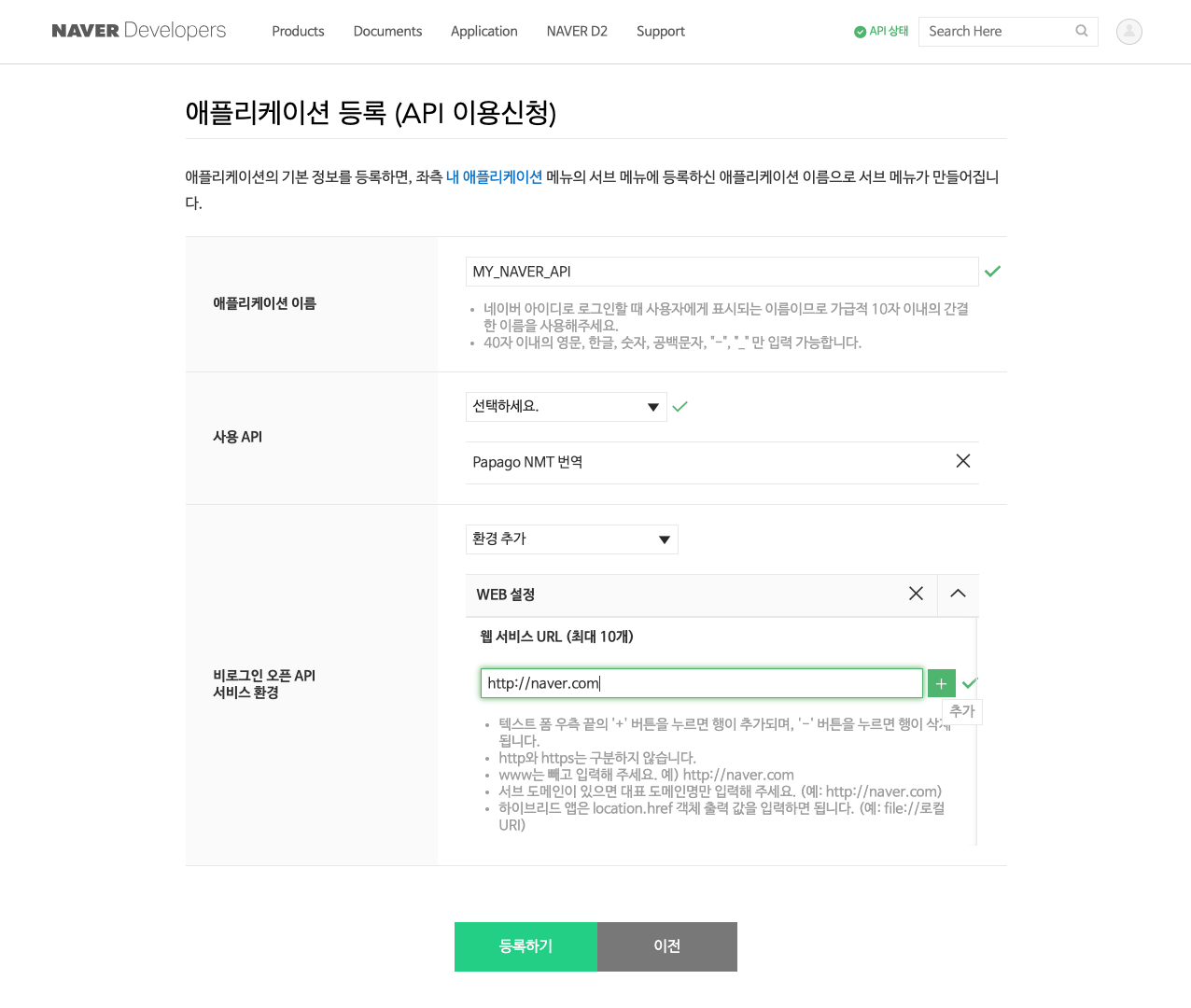
애플래케이션 등록의 마지막 관문은 환경 추가입니다. 저는 WEB 설정을 선택하고 웹 서비스 URL로는
http://naver.com으로 입력했습니다. 이 때 주의해야 할 점은 www를 제외해야 한다는 것입니다.
등록하기를 클릭하면 모든 과정이
끝납니다.
아래 이미지에서 발급받은 Naver API ID와 PW를 확인할 수 있습니다. 절대로 다른 사람에게 노출되지 않도록 주의하시기 바랍니다.
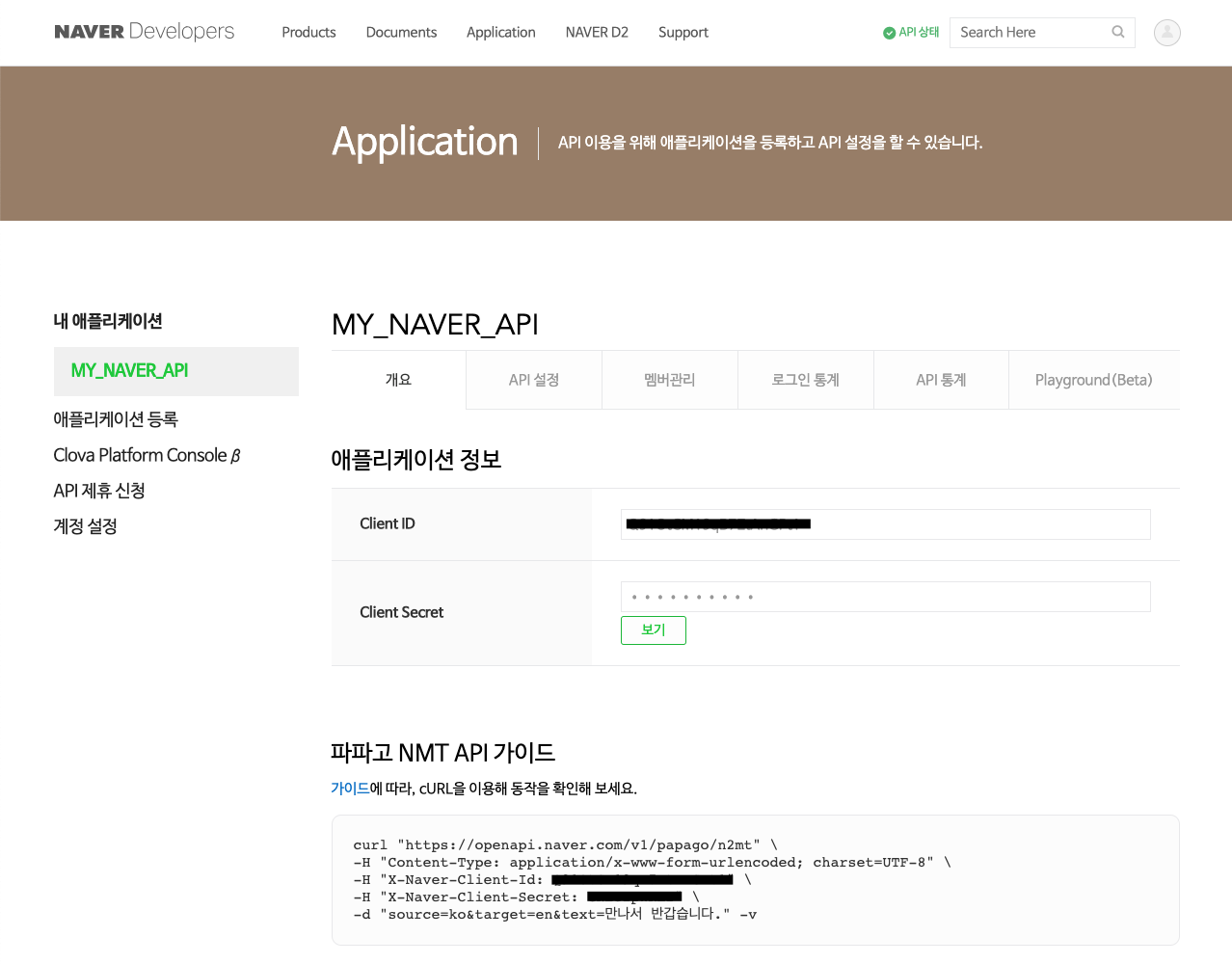
Papago NMT 번역 API 가이드 확인
이제 Papago NMT 번역 API를 어떻게 이용할 수 있는지, 그 방법을 알아보겠습니다. 모든 API가 정확하게 같을 수 없겠지만 이 방법을 활용하면 다른 API도 쉽게 이용할 수 있을테니 잘 따라오시기 바랍니다.
상단 메뉴의 Products > 파파고 NMT 번역을 선택한 다음 화면 하단에 있는 개발 가이드 보기를 클릭합니다. 그러면 아래 캡쳐 이미지와 같이 개발 가이드 문서가 열립니다.
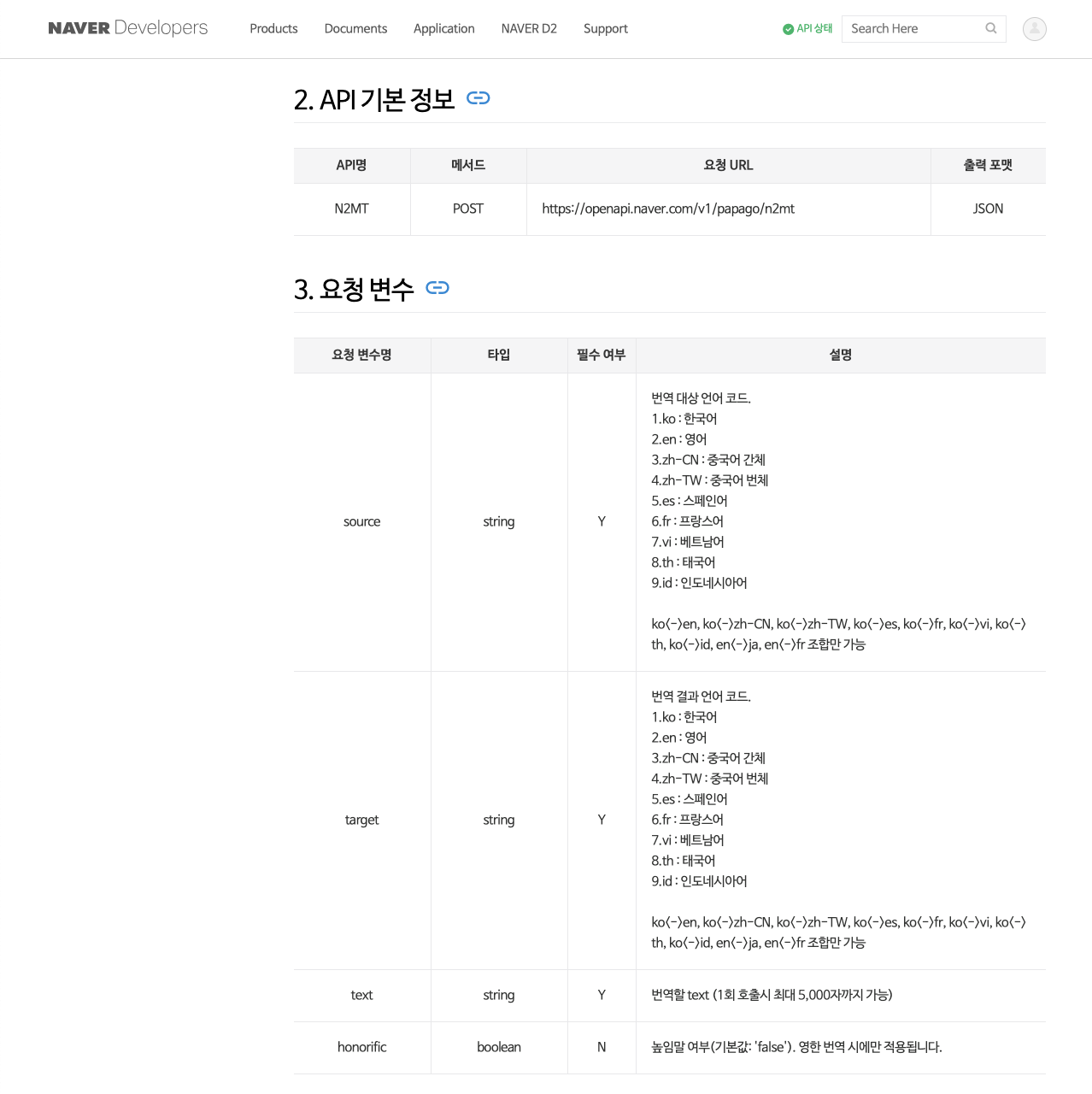
이 문서에서 눈 여겨 봐야 할 것은 2~5번 항목입니다. 먼저 2번 항목은 HTTP 요청에 어떤 방식(Method)이
사용되었고 요청 URL은 무엇인지 알려줍니다. 보이는 바와 같이 POST 방식이 사용되었습니다. 이런 경우에는,
httr 패키지의 POST() 함수를 사용해야 하며, url 인자에 요청 URL을 할당해주면 됩니다. 그리고
가장 중요한 것은 출력 포맷이 JSON이라는 것입니다. POST 함수의 encode 인자에 json을
지정해주어야 정상으로 작동됩니다! (제가 이걸 놓치고 있었는데 찬엽님 덕분에 해결했습니다. 감사합니다! )
3번 항목은 요청 변수입니다. 앞에서 POST 방식이 사용되었다고 말씀드렸는데요. POST() 함수의 body 인자에
요청 변수들을 잘 묶어서 할당해주어야 합니다. 주의해야 할 점은 body 인자는 리스트 형태로 입력받는다는
것입니다. POST() 함수 사용법에 대해 익숙하지 않은 분은 나중에 소개해드릴 R 코드에서 확인할 수 있으니,
지금 이 문서에서는 어떤 요청 변수에 어떤 값을 할당해야 하는지만 확인합니다.
그러니까 source에 ko를 넣고 target에 en을 넣으면 한글 문장을 영어로 번역하겠다는 의미입니다.
그리고 text에 번역할 한글 문장을 지정해주어야 됩니다. honorific은 영한번역 시에만 적용된다고 하니
참고하기
바랍니다.
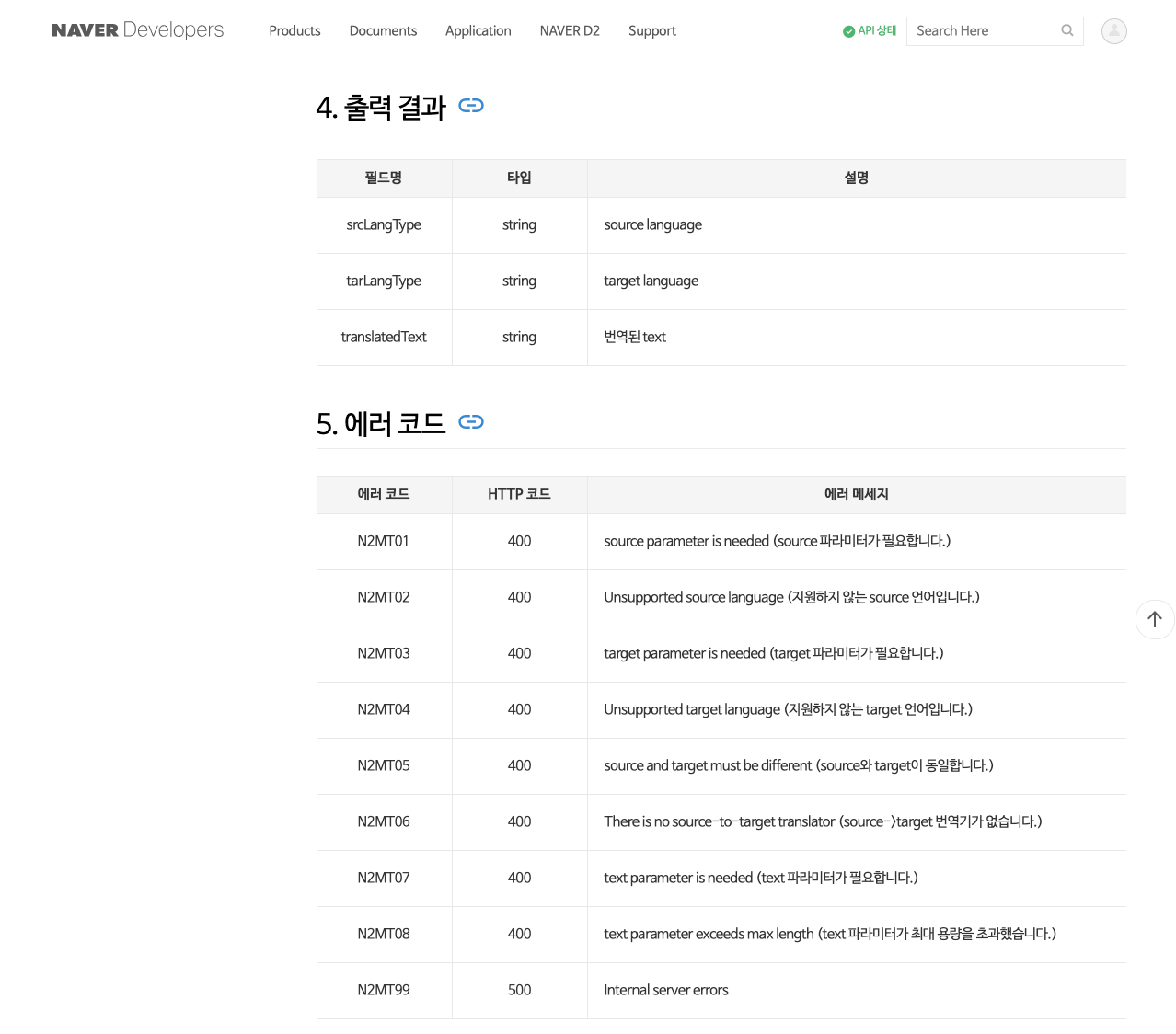
화면을 아래로 내려 차례로 4번과 5번 항목을 확인할 차례입니다. 4번 항목은 HTTP 요청 결과로 응답받게 될 내용이
무엇인지 확인할 수 있습니다. translatedText에 번역된 결과가 저장되어 있을 것입니다. 그리고 5번 항목은 HTTP
요청이 정상이 아닐 때 확인해야 하는 에러 코드 목록입니다. 이 에러 코드를 보고 Naver Papago API가 요구하는 요청
변수를 제대로 할당해주어야
합니다.
지금까지 살펴본 내용을 바탕으로 실제로 어떻게 R코드를 작성하여 결과를 얻을 수 있는지 확인해보겠습니다.
Naver Papago API ID와 PW를 환경설정에 저장
Naver Papago API를 이용하려면 앞에서 발급받은 API ID와 PW를 추가해주어야 하는데요. R 코드 안에 직접 입력하는 방식은 생각보다 위험한 방법이 됩니다. 만약 누군가에게 코드를 공유할 일이 생기면 ID와 PW를 지우고 주어야 하는데 사람은 망각의 동물이라 본인도 모르는 사이에 그냥 R코드를 주게 되는 경우가 빈번해지거든요. (물론 본인 코드를 공유하는 사람에게만 해당합니다. ㅎㅎ)
따라서 아래와 같이 R 환경변수에 Naver API ID와 PW를 등록해놓으면 타인에게 노출될 위험이 사라집니다. 지난번 포스팅에서도 소개해드렸습니다만, 이번에는 이미지를 캡쳐하여 직접 보여드리겠습니다. (상세하게 하려니 품이 많이 들지만…)
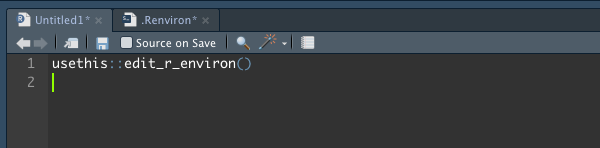
# RStudio Source 창에서 아래와 같이 입력하고 실행하면 .Renvion 파일이 열립니다.
usethis::edit_r_environ()
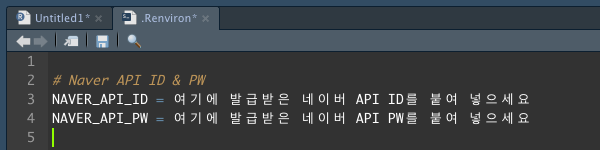
# .Renvion 파일로 이동하여 아래 내용을 추가하고 저장합니다.
# 왼쪽에 환경설정 변수는 본인 마음대로 작성해도 되지만,
# 오른쪽 환경설정 값에는 네이버 개발자센터에서 발급받은 ID와 PW를 넣습니다. (따옴표 없이도 가능합니다.)
NAVER_API_ID = 여기에 발급받은 네이버 API ID를 붙여넣으세요
NAVER_API_PW = 여기에 발급받은 네이버 API PW를 붙여넣으세요
위와 같이 실행한 다음 .Renviron 파일을 저장하고 RStudio를 재시동합니다. Naver Papago APP ID와 PW가 제대로 저장되었는지 확인하려면 아래와 같이 합니다.
# R 환경변수에 제대로 저장되었는지 확인합니다.
Sys.getenv('NAVER_API_ID')
Sys.getenv('NAVER_API_PW')
만약 제대로된 값이 출력되지 않는다면 재시도해보시기 바랍니다.
R에서 Naver Papago API 사용하기
앞에서 보여드렸던 개발 가이드 문서를 잘 확인하여 아래와 같이 R 코드를 작성하면 간단하게 해결됩니다. 먼저 필요한 패키지를 불러옵니다.
# 필요한 패키지를 불러옵니다.
library(tidyverse)
library(httr)
httr 패키지의 POST() 함수를 이용하여 한글 문장을 영어로 번역하는 코드를 작성해보겠습니다. 번역하고자
하는 문장을 먼저 정하여 string 객체에 할당하는 방식을 사용하겠습니다. 참고로 Naver API ID와 PW는
POST() 함수 내에 config 인자에 할당해야 하는데요. 이 때, add_headers() 함수를 이용해야
합니다. 그리고 X-Naver-Client-Id 및 X-Naver-Client-Secret와 같은 파라미터명은
개발 가이드 문서의 6번 항목(예시)에서 찾을 수 있으니 참고하기 바랍니다.
# 번역하려는 문장을 설정합니다.
string <- '어제 저녁에 부장에게 갈굼당하고 홧김에 술을 많이 마셨더니 머리가 깨질듯 아프다.'
# 위 문장을 text 요청 변수에 추가하여 영문으로 번역합니다.
res <- POST(url = 'https://openapi.naver.com/v1/papago/n2mt',
encode = 'json',
body = list(source = 'ko',
target = 'en',
text = string),
config = add_headers('X-Naver-Client-Id' = Sys.getenv('NAVER_API_ID'),
'X-Naver-Client-Secret' = Sys.getenv('NAVER_API_PW')
)
)
위 라인을 실행하면 res라는 응답(response) 객체가 생성됩니다. res를 출력하여 내용을 확인해보겠습니다.
# 응답 결과를 확인합니다.
print(x = res)
## Response [https://openapi.naver.com/v1/papago/n2mt]
## Date: 2019-04-18 01:12
## Status: 200
## Content-Type: application/json; charset=UTF-8
## Size: 253 B
출력된 내용을 보면 HTTP 요청 일시, 응답 상태코드, 콘텐츠 형식 및 인코딩 방식 등을 확인할 수 있습니다. 응답 받는 내용이
JSON 타입이므로 content() 함수를 이용하여 JSON 타입의 데이터를 추출해보겠습니다.
# JSON 타입의 데이터를 추출합니다.
json <- content(x = res)
# json 객체의 구조를 파악합니다.
str(object = json)
## List of 1
## $ message:List of 4
## ..$ @type : chr "response"
## ..$ @service: chr "naverservice.nmt.proxy"
## ..$ @version: chr "1.0.0"
## ..$ result :List of 3
## .. ..$ srcLangType : chr "ko"
## .. ..$ tarLangType : chr "en"
## .. ..$ translatedText: chr "My head hurts like a crack because I drank a lot last night because I was pressed by the manager."
새로 만들어진 json 객체는 리스트이며, 맨 마지막 원소에 translatedText가 있음을 알 수 있습니다. 번역
결과를 확인해볼까요?
# 영문으로 번역된 결과만 출력합니다.
print(x = json$message$result$translatedText)
## [1] "My head hurts like a crack because I drank a lot last night because I was pressed by the manager."
어떤가요? 번역 품질이 괜찮은가요? 갈굼당하다라는 표현이 조금 이상하군요. 하하하! 한영 번역도 갈 길이 좀 있군요.
오늘 안내해드릴 내용은 여기까지 입니다. 위 내용을 활용하여 Naver Papago SMT 번역 코드 작성에도 도전해보시면 어떨까요? 궁금하신 내용은 아래 댓글에 남겨주세요. 감사합니다!