
Naver Search Api를 활용한 블로그 수집
네이버 API 활용법 #2
Dr.Kevin 04/18/2019
지난 포스팅에 이어 이번에는 Naver 검색 API를 이용하여 블로그를 수집하는 예제를 소개하도록 하겠습니다.
내 애플리케이션에 API 추가하기
지난 포스팅에서는 Papago NMT 번역 서비스만 선택을 했었기 때문에 내 애플리케이션에 검색 API를 추가해야 합니다. 방법은 간단합니다. 먼저 네이버 개발자센터로 가서 네이버 아이디와 비밀번호로 로그인한 다음, 상단 메뉴의 Application > 내 애플리케이션을 클릭합니다.
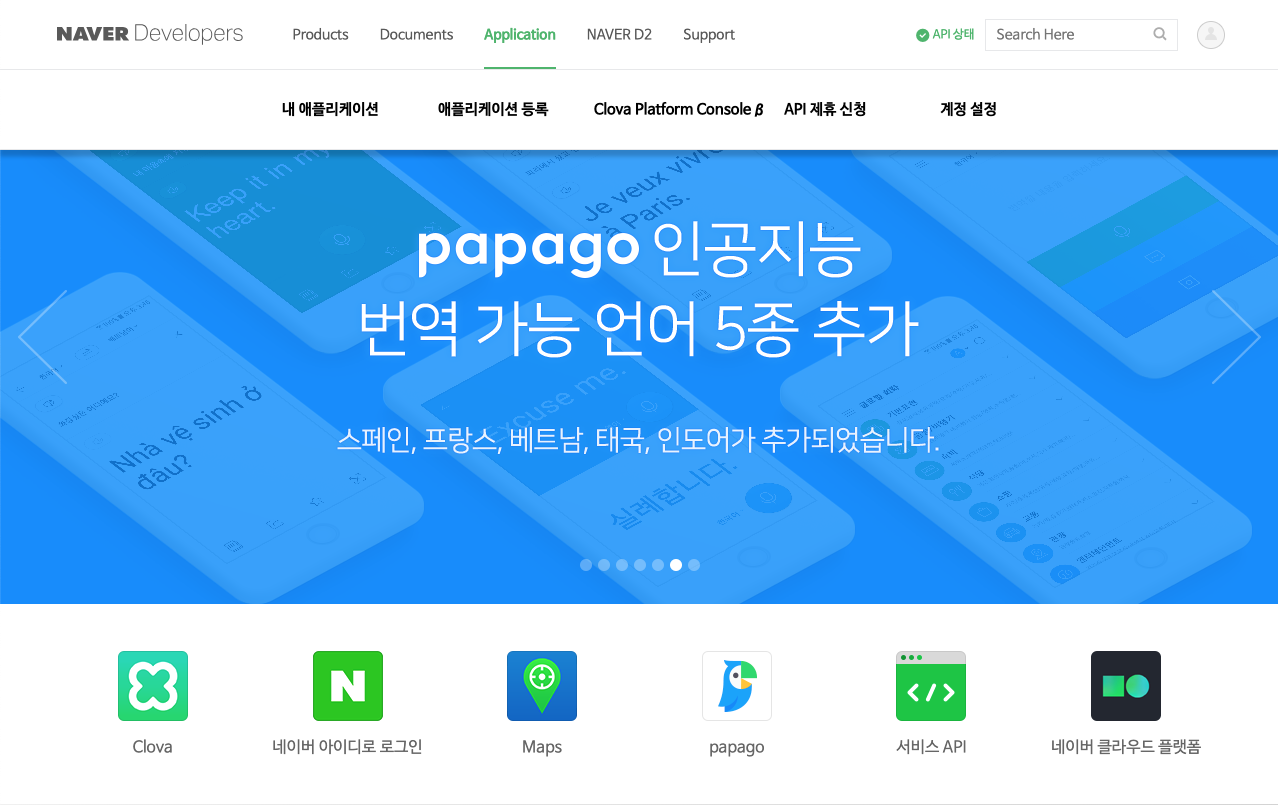
아래 이미지와 같이 내 애플리케이션으로 이동했으면 표 오른쪽에 있는 Action 항목의 연필 모양의 버튼을 클릭합니다.
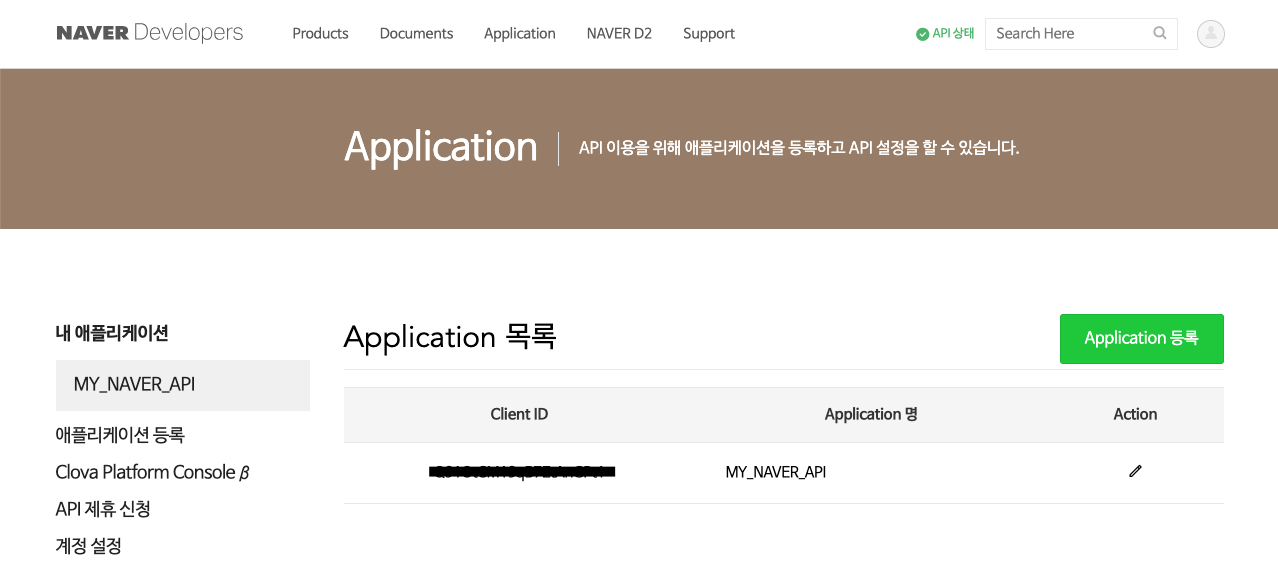
이제 기존에 생성해놓은 내 애플리케이션에서 사용 API를 추가할 수 있습니다. API 설정 탭에서 화면을 아래로 내려서 사용 API에서 추가로 사용하고자 하는 API를 선택하면 됩니다. 주의해야 할 점은 블로그를 수집한다고 해서 블로그를 선택해서는 안 된다는 점입니다. API 이름이 블로그인 것은 내 블로그에 글을 읽고, 쓰고 하는 작업을 하겠다는 의미입니다. 웹 크롤링 관점에서 남들이 써놓은 블로그를 수집하는 것은 검색에 해당됩니다. 따라서 검색을 선택합니다.
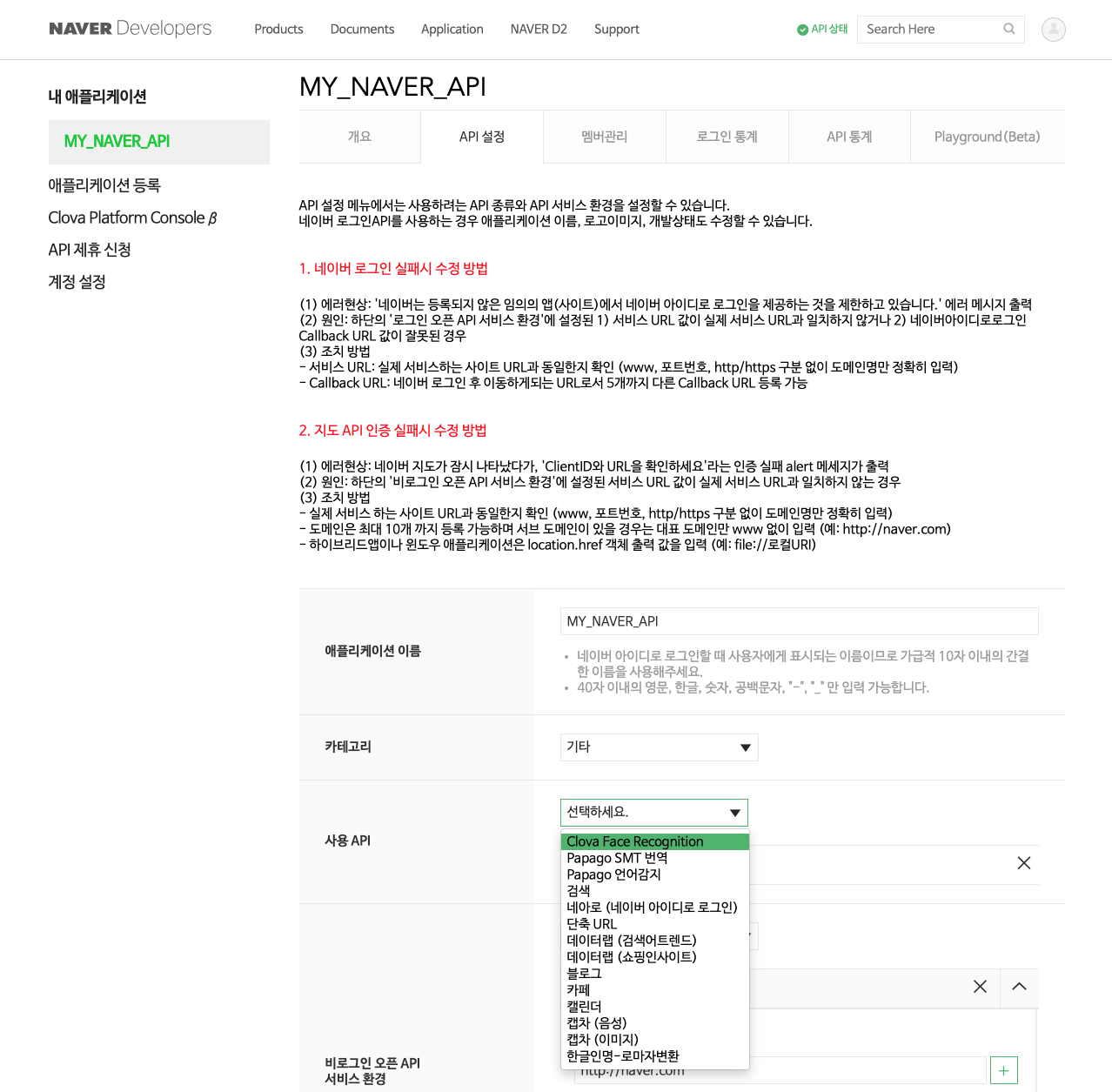
API 선택이 끝났으면 해당 항목의 개발 가이드 문서를 확인해야 할 차례입니다. 상단 메뉴 중 Product > 서비스 API > 검색을 차례로 선택합니다.
아래와 같은 화면으로 이동하면 개발 가이드 보기를 선택하면 됩니다. 참고로 오픈 API 이용 신청은 하지 않아도 됩니다. 우리는 이미 필요한 애플리케이션을 만들었고, 그 안에 필요한 API도 선택했기 때문입니다. 이 부분이 조금 헷갈리게 되어 있는 것 같습니다.
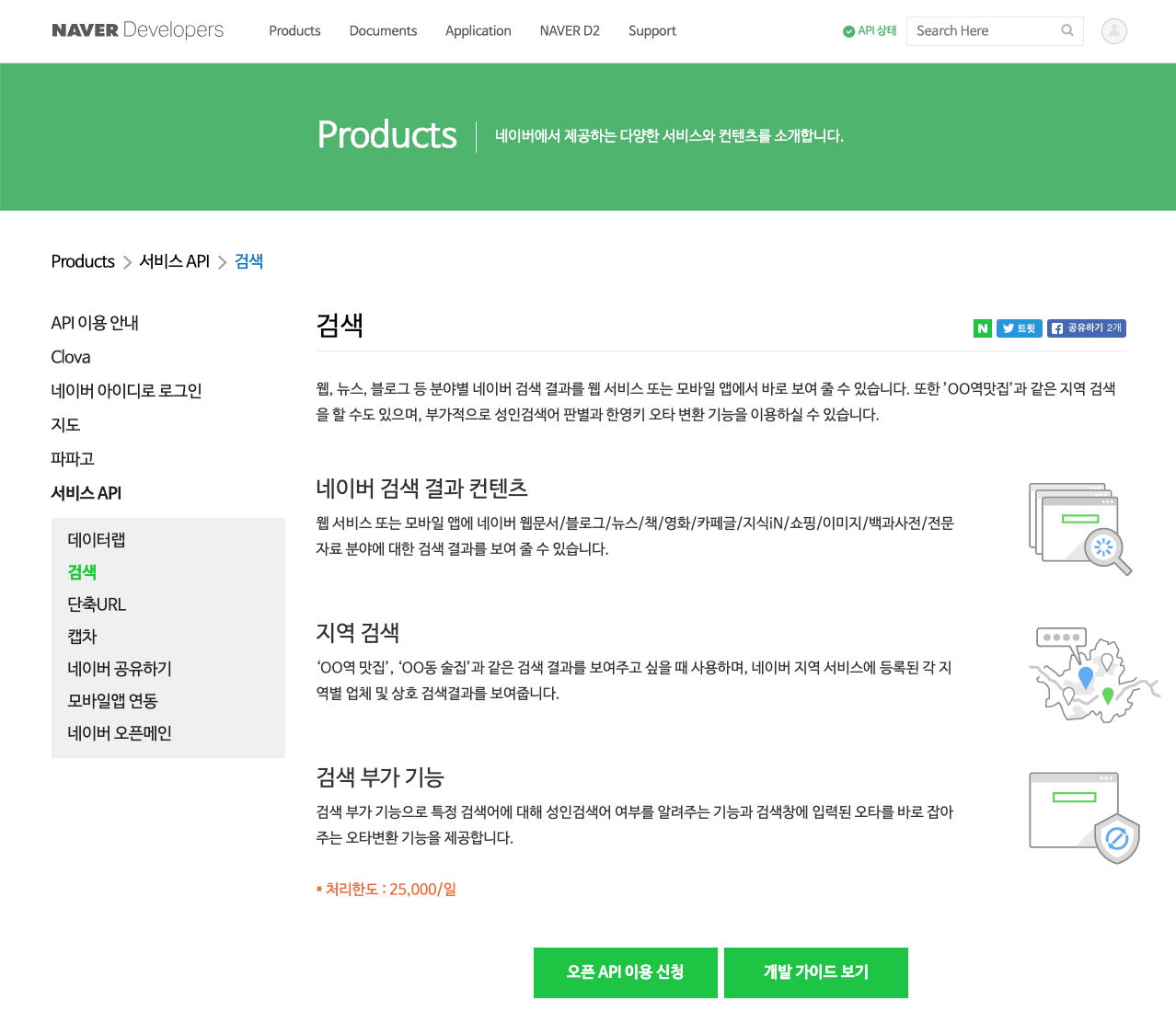
서비스 API의 검색에는 여러 가지 하위 항목이 포함되어 있습니다. 블로그는 물론, 뉴스, 책, 백과사전, 영화, 카페글, 지식iN 등 다양한 종류의 콘텐츠를 수집할 수 있습니다. 그런데 아래 이미지를 보면, 0.API 호출 예제가 보이는데 다양한 프로그래밍 언어별로 검색 서비스를 활용하는 예시를 올려놨습니다. 하지만 R은 없네요. 그래서 R을 사용하는 입장에서는 조금 아쉽지만, 그래도 뭐 제가 이렇게 만들어 드리니까요. 하하하
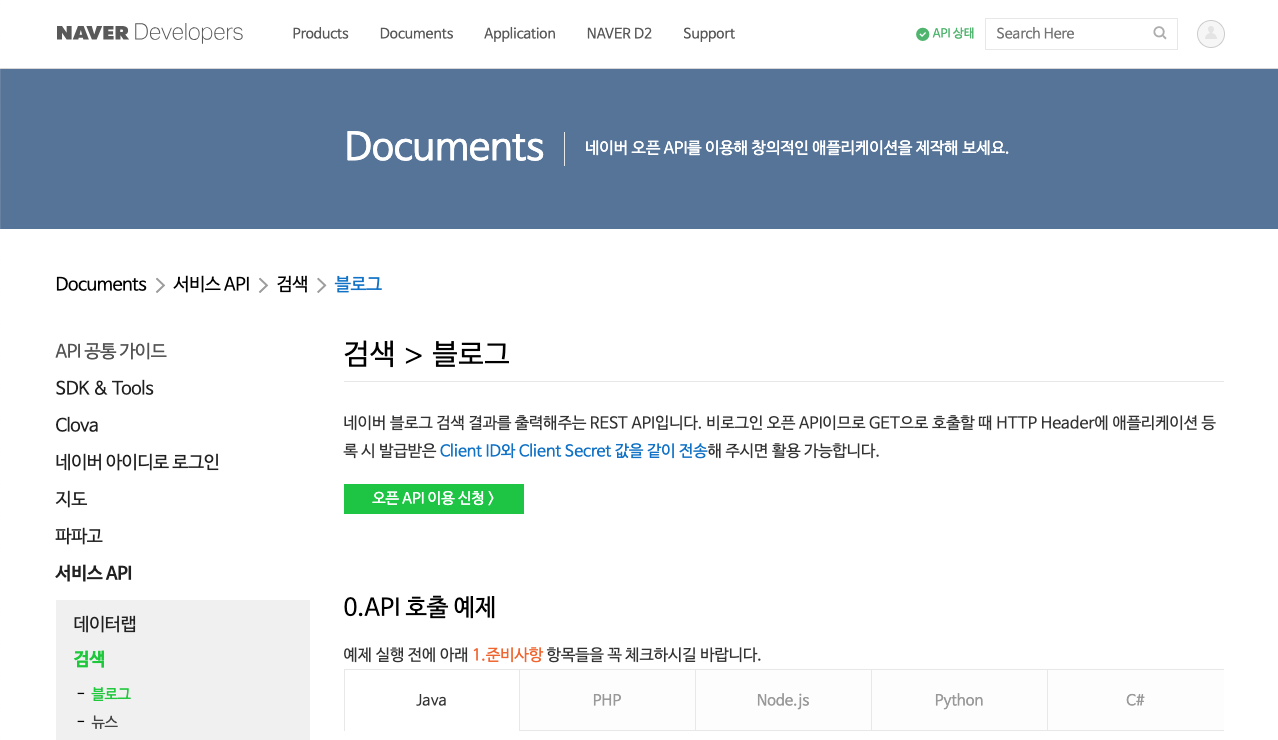
웹 페이지를 아래로 내리면 2.API 기본 정보와 3.요청 변수가 보입니다. 2.API 기본 정보에서
메서드를 확인해보니 Papago NMT 번역 서비스와 다르게 GET 방식이 사용되었다는 것을 알 수
있습니다. 그러므로 httr 패키지의 GET() 함수를 이용하여 HTTP 요청을 실행하면 됩니다.
POST() 함수와 다른 점은 요청 변수에 대해서 body 인자가 아닌 query 인자를 사용한다는 점입니다.
둘 다 리스트 형태로 할당해주어야 하는 것은 같습니다. 이 부분에 대해서 잘 이해가 되지 않는 분인 아래에 R 코드를 유심히
살펴보시기 바랍니다.
요청 URL은 두 종류를 제공하고 있습니다. 저는 XML보다 JSON 형태로 받는 것을 선호합니다. 그 이유는
JSON 형태가 훨씬 다루기 쉽기 때문입니다. jsonlite 패키지의 fromJSON() 함수를 이용하면 응답
받은 데이터로부터 필요한 데이터를 손쉽게 데이터프레임으로 변환할 수 있습니다. 이 부분 역시 R코드에서 소개해드리겠습니다.
3.요청 변수로 넘어가면 4가지 파라미터를 추가해야 하는 것으로 보입니다. 먼저 query 변수에 검색어를
할당하고, display 변수에는 한 번에 수집할 블로그 건수를 정수로 지정합니다. 최대 100개까지 수집할
수 있군요. start 변수에는 수집할 블로그의 시작 위치를 지정해주는데 최대 1000개만 가능합니다. 결국 한 번에
100개씩 수집한다고 했을 때 시작 위치에 1000을 할당하면 최대 1099건까지 모을 수 있다는 얘기입니다. 많이
안타깝네요. 그래도 sort 변수에 sim(유사도순) 및 date(날짜순)으로 선택할 여지가 있으니 몇 건 더
모을 수
있겠습니다.
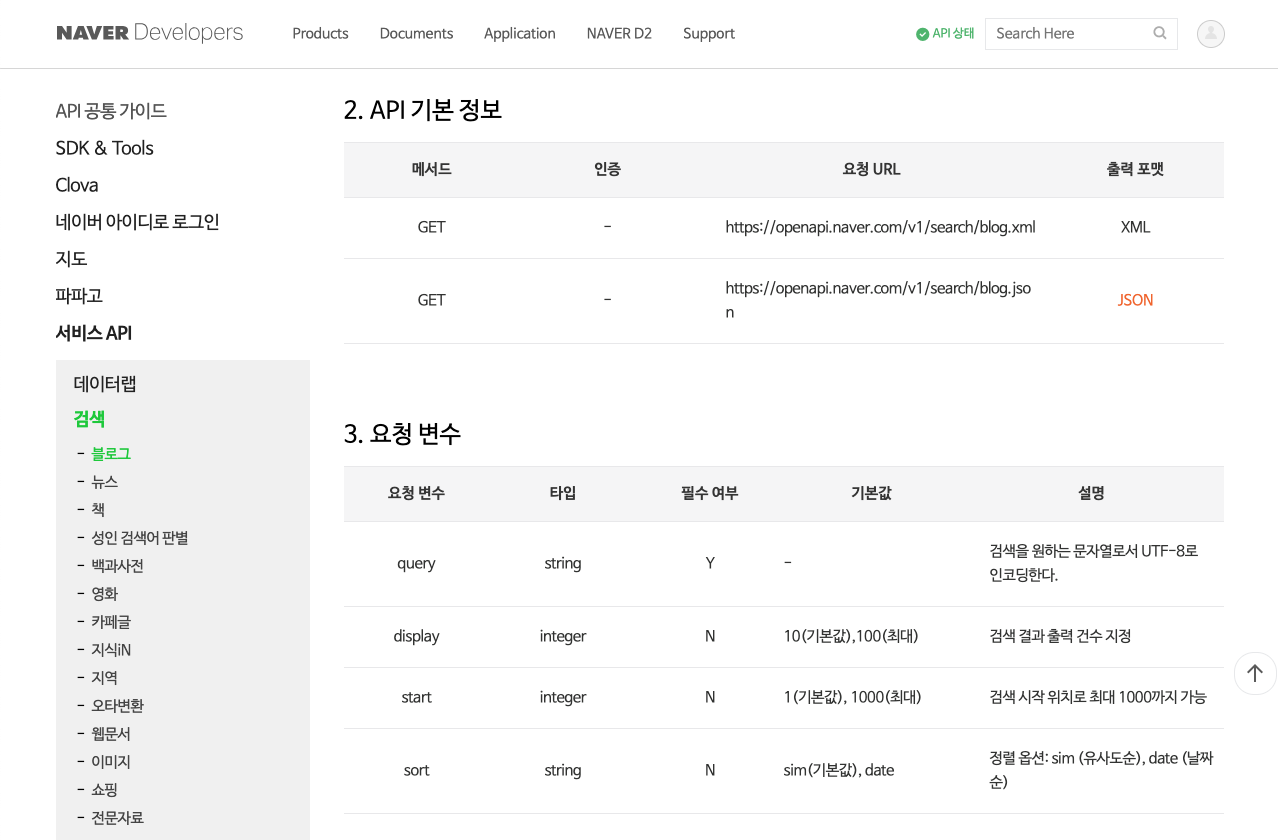
마지막으로 확인해야 할 사항은 4.출력 결과입니다. JSON 형태로 응답 받으면 표 중간에 있는 items 안에
블로그의 정보가 담겨 있습니다. fromJSON() 함수를 사용하면 이 부분을 데이터프레임으로 한 번에 변환할 수
있습니다. 제공되는 정보로는 title, link, description, bloggername,
bloggerlink 및 postdate 등 6가지
입니다.
R에서 Naver Search API 사용하기
앞에서 보여드렸던 개발 가이드 문서를 잘 확인하여 아래와 같이 R 코드를 작성하면 간단하게 해결됩니다. 먼저 필요한 패키지를 불러옵니다. 지난 포스팅에서 사용된 2가지 패키지 외에 jsonlite 패키지도 추가해줍니다.
# 필요한 패키지를 불러옵니다.
library(tidyverse)
library(httr)
library(jsonlite)
httr 패키지의 GET() 함수를 이용하여 검색어를 포함하는 블로그를 수집하는 코드를 작성해보겠습니다.
검색어를 먼저 정하여 string 객체에 할당하는 방식을 사용하겠습니다. GET() 함수에는 body와
encode 인자가 필요 없고, 대신에 query 인자가 사용됩니다.
# 검색어를 설정합니다.
string <- '미세먼지'
# 위 검색어를 query 요청 변수에 추가하여 영문으로 번역합니다.
res <- GET(url = 'https://openapi.naver.com/v1/search/blog.json',
query = list(query = string,
display = '100',
start = '1',
sortt = 'data'),
config = add_headers('X-Naver-Client-Id' = Sys.getenv('NAVER_API_ID'),
'X-Naver-Client-Secret' = Sys.getenv('NAVER_API_PW')
)
)
위 라인을 실행하면 res라는 응답(response) 객체가 생성됩니다. res를 출력하여 내용을 확인해보겠습니다.
# 응답 결과를 확인합니다.
print(x = res)
## Response [https://openapi.naver.com/v1/search/blog.json?query=%EB%AF%B8%EC%84%B8%EB%A8%BC%EC%A7%80&display=100&start=1&sortt=data]
## Date: 2019-04-18 12:49
## Status: 200
## Content-Type: application/json; charset=UTF-8
## Size: 59.7 kB
## {
## "lastBuildDate": "Thu, 18 Apr 2019 21:49:38 +0900",
## "total": 3790773,
## "start": 1,
## "display": 100,
## "items": [
## {
## "title": "<b>미세먼지</b>방충망 답답함 zero!!",
## "link": "https://blog.naver.com/napure5579?Redirect=Log&logNo=221515...
## "description": "7% 차단 F93 <b>미세먼지</b> 창문 필터를 적용한 <b>미세먼지</b>방충망으로 미세한 입자...
## ...
출력된 내용을 보면 HTTP 요청 일시, 응답 상태코드, 콘텐츠 형식 및 인코딩 방식 등을 확인할 수 있습니다. 응답 받는 내용이
JSON 타입이므로 content() 함수를 이용하여 text로 변환한 다음 fromJSON() 함수를 추가하여
JSON 타입의 데이터를 추출해보겠습니다.
# JSON 타입의 데이터를 추출합니다.
json <- res %>% content(as = 'text') %>% fromJSON()
# json 객체의 구조를 파악합니다.
str(object = json)
## List of 5
## $ lastBuildDate: chr "Thu, 18 Apr 2019 21:49:38 +0900"
## $ total : int 3790773
## $ start : int 1
## $ display : int 100
## $ items :'data.frame': 100 obs. of 6 variables:
## ..$ title : chr [1:100] "<b>미세먼지</b>방충망 답답함 zero!!" "<b>미세먼지</b> 창문필터 이거 하나면 끝!" "<b>미세먼지</b>문제 내부공기위해 웨이븐 선택했어요" "LG공기청정기 집안 <b>미세먼지</b> 걱정 없네요!" ...
## ..$ link : chr [1:100] "https://blog.naver.com/napure5579?Redirect=Log&logNo=221515280442" "https://blog.naver.com/arafatare?Redirect=Log&logNo=221515628016" "https://blog.naver.com/del2047?Redirect=Log&logNo=221512271910" "https://blog.naver.com/fever1332?Redirect=Log&logNo=221515014792" ...
## ..$ description: chr [1:100] "7% 차단 F93 <b>미세먼지</b> 창문 필터를 적용한 <b>미세먼지</b>방충망으로 미세한 입자의 먼지가 무려 93%씩이나 걸"| __truncated__ "돌아다니는 미세한 유해물질까지 함께 차단을 시켜주면서 맑은 공기만을 실내로 들어오게 해 준다고... 중국먼지 때문"| __truncated__ "<b>미세먼지</b>문제 내부공기도 안심할수없습니다! 안녕하세요. 타나에요. 올해는 유난히 대기오염이... 정도였습니다"| __truncated__ "LG 퓨리케어360도 공기청정기 AS199DWR 는 <b>미세먼지</b>, 초<b>미세먼지</b>, 극초<b>미세먼지</b> 농도를 상세하게"| __truncated__ ...
## ..$ bloggername: chr [1:100] "꿈꾸는 나푸레" "하루 테라피" "타나" "미미의 낭만테이블" ...
## ..$ bloggerlink: chr [1:100] "https://blog.naver.com/napure5579" "https://blog.naver.com/arafatare" "https://blog.naver.com/del2047" "https://blog.naver.com/fever1332" ...
## ..$ postdate : chr [1:100] "20190416" "20190417" "20190413" "20190416" ...
새로 만들어진 json 객체는 리스트이며, 맨 마지막 원소인 items는 100행, 6열을 갖는 데이터프레임이라는 것을 알
수 있습니다. 그러므로 json 객체에서 items만 선택하여 별도로 저장하면 우리가 수집하려는 블로그 데이터만 추출할 수
있는 것입니다.
# 블로그 데이터만 추출합니다.
blog <- json$items
# blog 객체를 일부만 출력합니다.
glimpse(x = blog)
## Observations: 100
## Variables: 6
## $ title <chr> "<b>미세먼지</b>방충망 답답함 zero!!", "<b>미세먼지</b> 창문필터 이거 하나…
## $ link <chr> "https://blog.naver.com/napure5579?Redirect=Log&…
## $ description <chr> "7% 차단 F93 <b>미세먼지</b> 창문 필터를 적용한 <b>미세먼지</b>방충망으로 미…
## $ bloggername <chr> "꿈꾸는 나푸레", "하루 테라피", "타나", "미미의 낭만테이블", "❤애키우고 개키우는 …
## $ bloggerlink <chr> "https://blog.naver.com/napure5579", "https://blog.n…
## $ postdate <chr> "20190416", "20190417", "20190413", "20190416", "201…
Naver Search API를 활용하면 원하는 블로그 데이터를 손쉽게 수집할 수 있습니다. 하지만 검색어별로 최대 1000개
밖에 수집할 수 없다는 점은 상당히 아쉽네요.
이번 포스팅에서 안내해드릴 내용은 여기까지 입니다. 위 내용을 활용하여 Naver Search API 뉴스 수집 코드 작성에도 도전해보시면 어떨까요? 궁금하신 내용은 아래 댓글에 남겨주세요. 감사합니다!