
R 시각화 2
ggplot2 패키지를 활용한 시각화 2
Dr.Kevin 4/25/2018
지난 포스팅 R 시각화 1에 이어 ggplot2 패키지를 활용한 시각화 2번째 포스팅을 정리해보고자 합니다. 역시 활용할 데이터는 2017 프로야구 타자 스탯입니다. 아래와 같이 시각화에 사용할 데이터프레임을 준비합니다.
# 필요 패키지를 불러옵니다.
library(readxl)
# xlsx 파일을 읽어, dataXls에 할당합니다.
hitters <- read_excel(path = './data/2017_Baseball_hitter_stat.xlsx', sheet = NULL)
# 불필요한 열(순위)을 삭제합니다.
hitters <- hitters[, -1]
# 팀명을 범주형 벡터로 변환합니다.
hitters$팀명 <- as.factor(hitters$팀명)
# 올스타팀 컬럼을 새로 만듭니다.
hitters$올스타팀 <- ifelse(test = hitters$팀명 %in% c('NC', '넥센', 'LG', 'KIA', '한화'),
yes = '나눔',
no = '드림')
# 50 타수 이상인 타자만 추출하여 hitters50 객체에 할당합니다.
hitters50 <- hitters[hitters$타수 >= 50, ]
히스토그램 그리기
지난 EDA 포스팅에서 R 기본 함수로 히스토그램을 그려봤었는데요. 간단하게 복습을 해본 뒤에 ggplot() 함수로 넘어가겠습니다.
# R 기본 함수로 히스토그램을 그립니다.
hist(x = hitters50$OPS,
breaks = 15,
ylim = c(0,35),
labels = TRUE,
main = '2017 프로야구 타자 분포 (OPS 기준)',
xlab = 'OPS (장타율 + 출루율)',
ylab = '빈도수',
family = 'NanumGothic')
abline(v = 0.9, col = 'red')
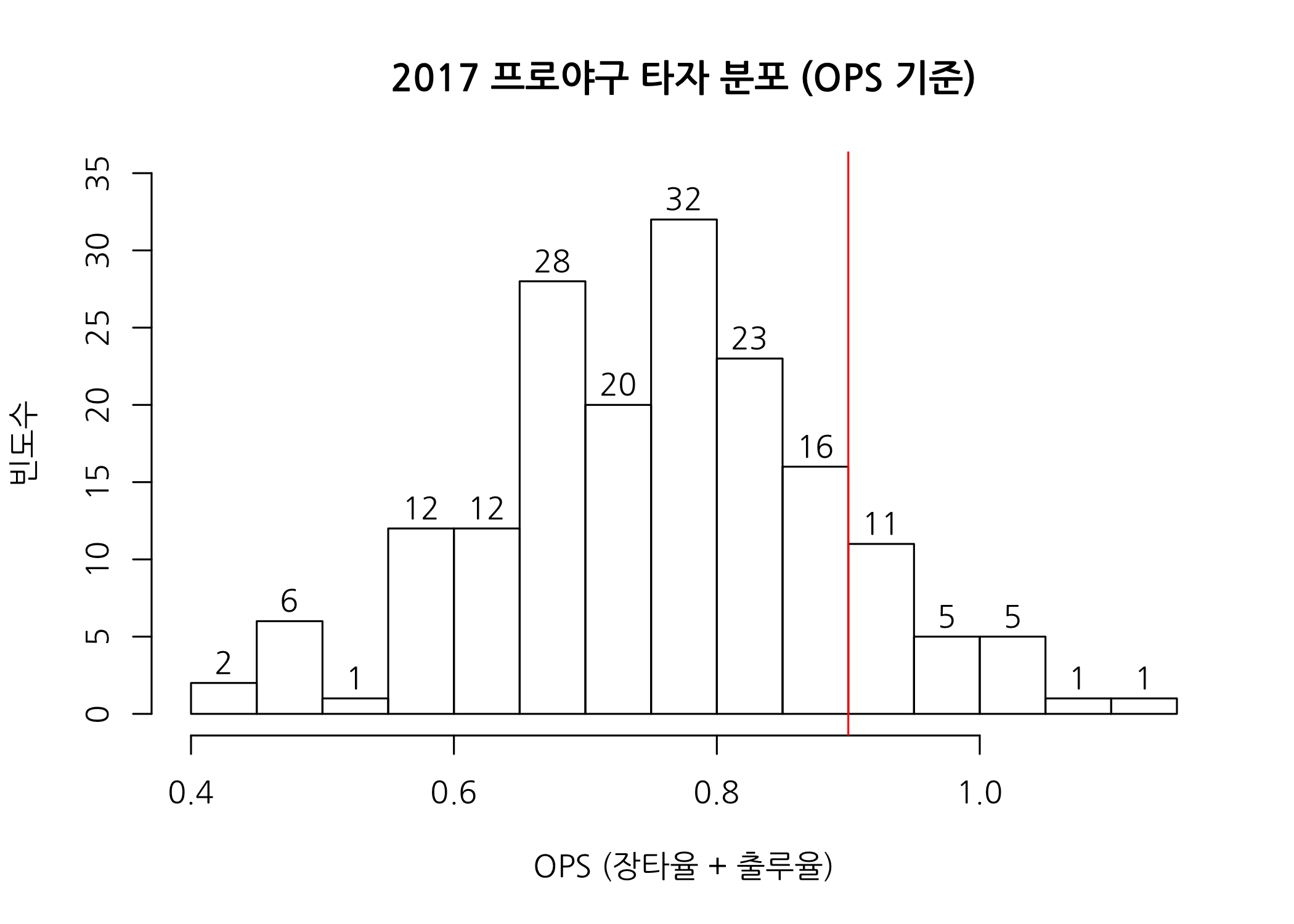
이런 모양의 히스토그램을 ggplot2 패키지로 구현해보도록 하겠습니다. 지난 번 포스팅에서 산점도를 그렸던 방법과 비슷합니다. 다만 geometries_function()을 geom_point() 대신에 geom_histogram()을 사용한다는 것이 다릅니다. 먼저 히스토그램 기본형을 확인한 후 몇 가지 인자를 조정해보겠습니다.
# 히스토그램에 사용될 데이터와 전체 에스테틱을 gghist에 할당합니다.
gghist <- ggplot(data = hitters50,
mapping = aes(x = OPS))
# 히스토그램 기본형을 그립니다.
gghist + geom_histogram()
## `stat_bin()` using `bins = 30`. Pick better value with `binwidth`.
기본형이라 그런지 그렇게 예쁘지는 않네요. 여러 인자들을 조정하기에 앞서 geom_histogram() 함수에서 사용되는 주요 인자를 몇 가지를 소개하도록 하겠습니다.
- binwidth : 막대의 너비를 정합니다. 구간을 나누는 기준이 되므로 막대의 개수가 결정됩니다.
- bins : 막대의 개수를 정합니다. hist() 함수의
breaks인자와 같은 기능을 합니다. - breaks : 막대의 구간을 숫자 벡터로 할당할 때 사용합니다.
3가지 인자 중에서 breaks를 사용한 예제를 아래에 보여드리겠습니다. 이와 함께 다루어야 할 인자들은 산점도 그릴 때 소개해드렸던 color, fill 등입니다. 그래프 제목은 ggtitle() 함수, x 및 y축 이름은 labs() 함수로 지정하면 되고, 세로 수직선은 geom_vline() 함수를 사용하면 됩니다.
다만 막대에 레이블을 추가하는 방법과 y축의 limits를 조정하는 방법은 지난 포스팅에서 소개해드리지 않았는데요. geom_text()와 scale_y_continuous() 함수로 해결할 수 있습니다. 각각의 방식은 코드를 먼저 소개해드리고 몇 가지 간단하게 언급하도록 하겠습니다.
# R 기본 함수로 그린 히스토그램의 막대 구간을 살펴보면
# 0.40부터 1.15까지 0.05 간격인 것을 알 수 있습니다.
breaks <- seq(from = 0.4, to = 1.15, by = 0.05)
# 히스토그램을 그립니다.
gghist +
geom_histogram(breaks = breaks,
color = 'black',
fill = 'white') +
geom_text(mapping = aes(label = ..count..),
stat = 'bin',
breaks = breaks,
vjust = -1) +
geom_vline(xintercept = 0.9,
color = 'red') +
ggtitle(label = '2017 프로야구 타자 분포 (OPS 기준)') +
labs(x = 'OPS (장타율 + 출루율)',
y = '빈도수') +
scale_y_continuous(limits = c(0, 35))
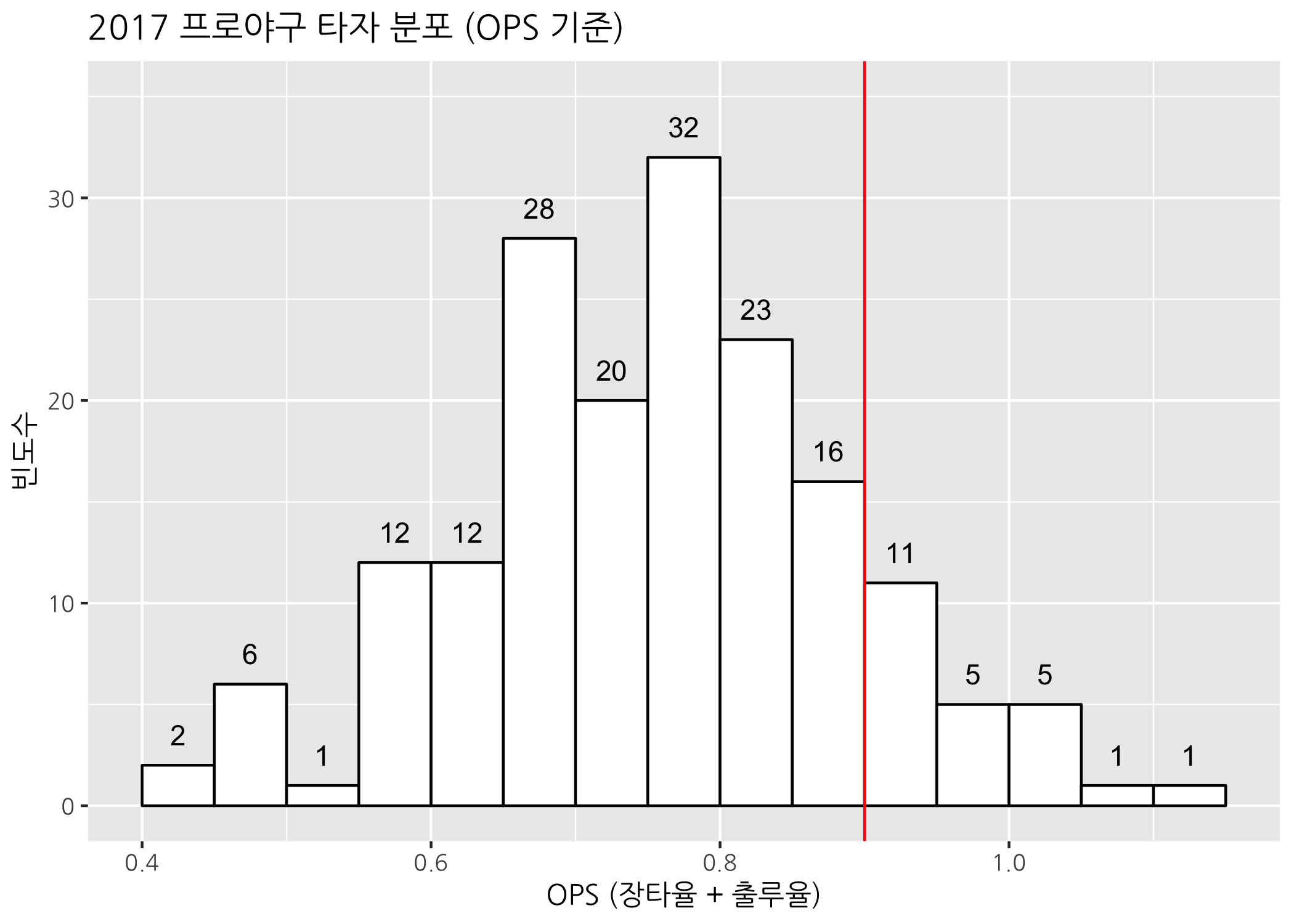
히스토그램의 막대 빈도수를 출력하고자 할 때, geom_text() 함수의 mapping 인자에 aes(lebel = ..count..)와 stat = 'bin' 이 두 부분이 한 눈에 이해하기 어려웠을 것입니다. ggplot() 함수에 할당된 데이터에는 히스토그램에 출력될 빈도수가 따로 들어있지 않으므로 막대 구간별 빈도수를 계산해서 출력하라는 의미를 담고 있습니다. breaks = breaks에서 히스토그램의 막대 구간을 정해준 것이구요. 저 막대 구간에 해당하는 빈도를 계산하는 것이지요. vjust = -1은 막대 끝인 0.5를 기준으로 위에 출력하라는 것을 의미합니다.
이렇게 하고 보니 R 기본 함수로 그래프를 그리는 것이 상당히 편리하다는 생각이 마구 듭니다. 그런데 ggplot2 패키지로 그린 그래프가 좀 더 예쁜 것 같긴 합니다. 지금 히스토그램에서 2가지를 더해보겠습니다. 하나는 히스토그램을 중첩하는 것이고, 또 다른 하나는 테마를 적용해보는 것입니다.
# 필요 패키지를 불러옵니다.
library(ggthemes)
# 히스토그램을 중첩하고 테마를 추가합니다.
gghist +
geom_histogram(breaks = breaks,
color = 'black',
fill = 'white') +
geom_text(mapping = aes(label = ..count..),
stat = 'bin',
breaks = breaks,
vjust = -1) +
geom_vline(xintercept = 0.9,
color = 'red') +
ggtitle(label = '2017 프로야구 타자 분포 (OPS 기준)') +
labs(x = 'OPS (장타율 + 출루율)',
y = '빈도수') +
scale_y_continuous(limits = c(0, 35)) +
geom_histogram(breaks = seq(from = 0.9, to = 1.15, by = 0.05),
color = 'black',
fill = 'skyblue') +
theme_wsj() +
theme(title = element_text(size = 15,
face = 'bold',
family = 'NanumGothic'))
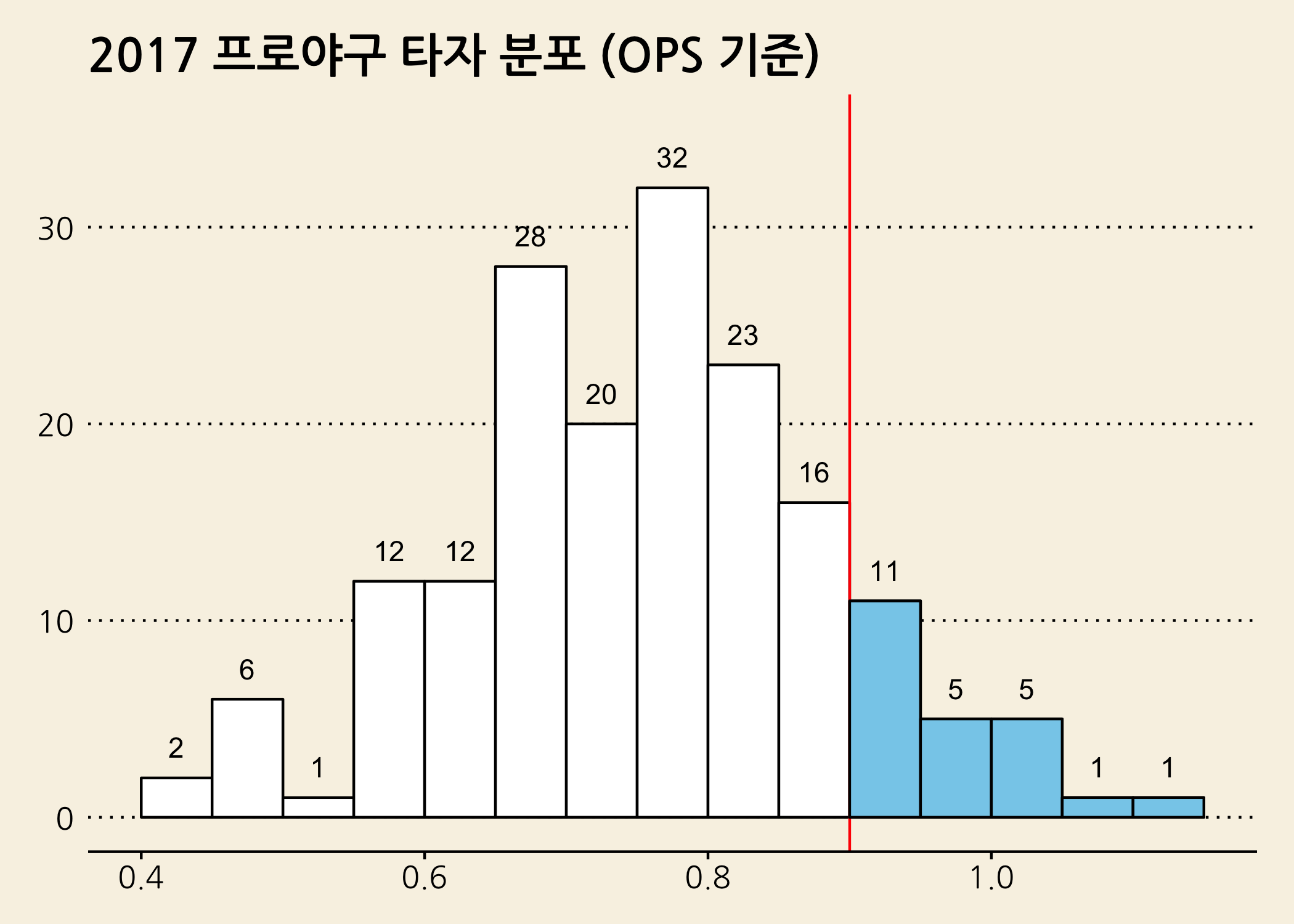
theme_wsj()는 Washington Journal의 차트와 비슷한 그래프를 그릴 수 있도록 해줍니다. 실제 차트와 비교해볼까요?

이렇게 하고 보니 비록 ggplot() 함수로 그래프를 그리기는 어려워도 괜찮은 그래프를 그려볼 수 있겠다는 생각이 드시죠?
상자수염그림 그리기
상자수염그림도 두 가지로 그려보고 비교해보겠습니다. 먼저 R 기본 함수로 그려보겠습니다.
# R 기본 함수로 상자수염그림을 그립니다.
par(family = 'NanumGothic')
boxplot(formula = 홈런 ~ 팀명,
data = hitters50,
xlab = '팀명',
ylab = '홈런',
main = '2017 프로야구 팀별 홈런 분포 비교')
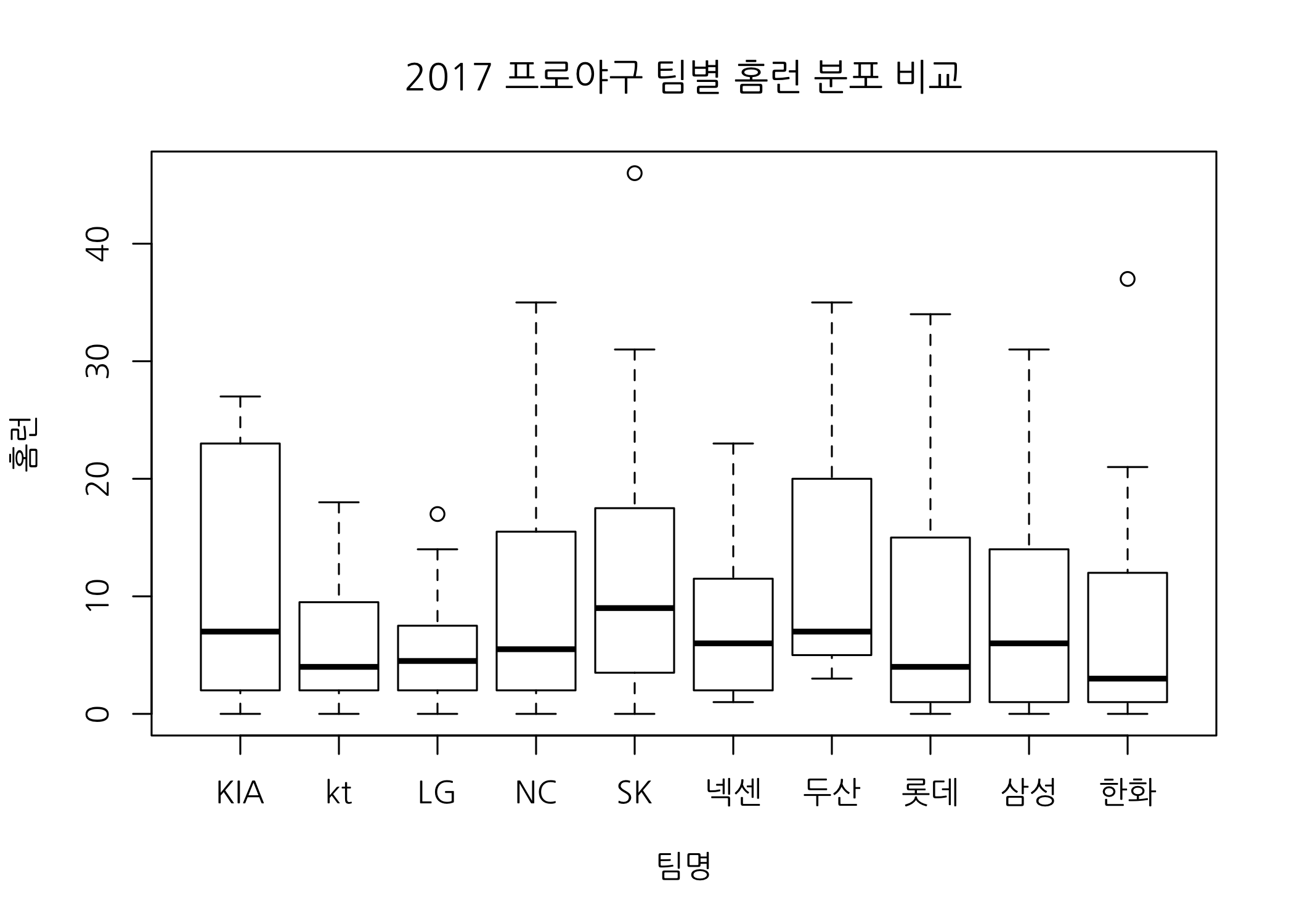
홈런 잘치는 타자들이 즐비한 SK 와이번즈의 중위수와 최대값이 가장 높습니다. 이제 ggplot() 함수로 상자수염그림을 그려보겠습니다.
# 상자수염그림에 사용될 데이터와 전체 에스테틱을 ggbox에 할당합니다.
ggbox <- ggplot(data = hitters50,
mapping = aes(x = 팀명,
y = 홈런))
# 상자수염그림 기본형을 그립니다.
ggbox + geom_boxplot()
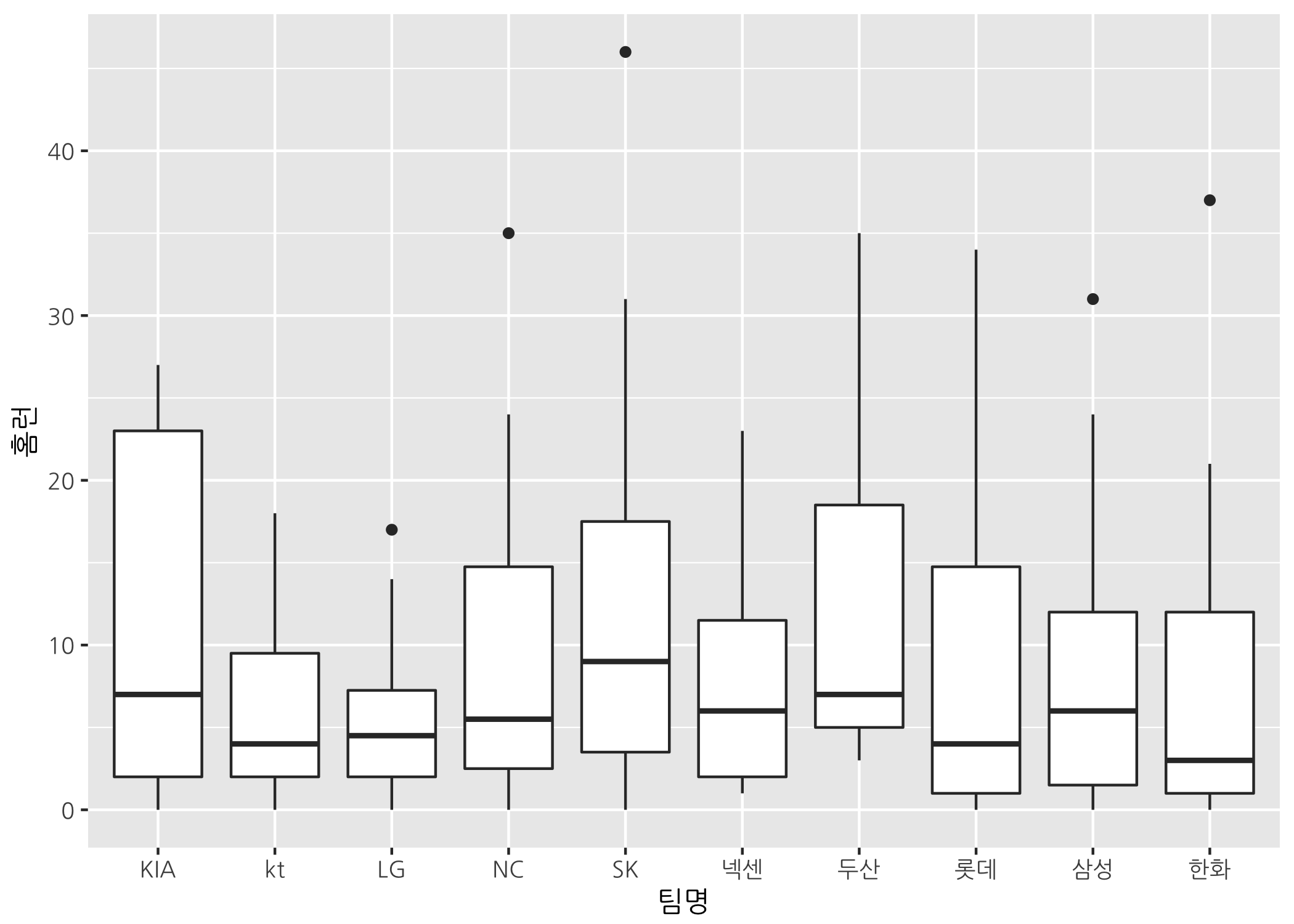
역시 기본형은 좀 밋밋하죠? 일단 R 기본 함수로 그린 것과 비슷하게 그릴 수 있도록 여러 인자값을 지정해주겠습니다. 그리고 이번에는 Economist 테마를 추가합니다.
# 그래프 제목과 축 이름을 바꾸고, Economist 테마를 추가합니다.
ggbox +
geom_boxplot(outlier.shape = 1,
outlier.size = 2) +
ggtitle(label = '2017 프로야구 팀별 홈런 분포 비교') +
labs(x = '팀명',
y = '홈런') +
theme_economist() +
theme(title = element_text(size = 15,
face = 'bold',
family = 'NanumGothic'))
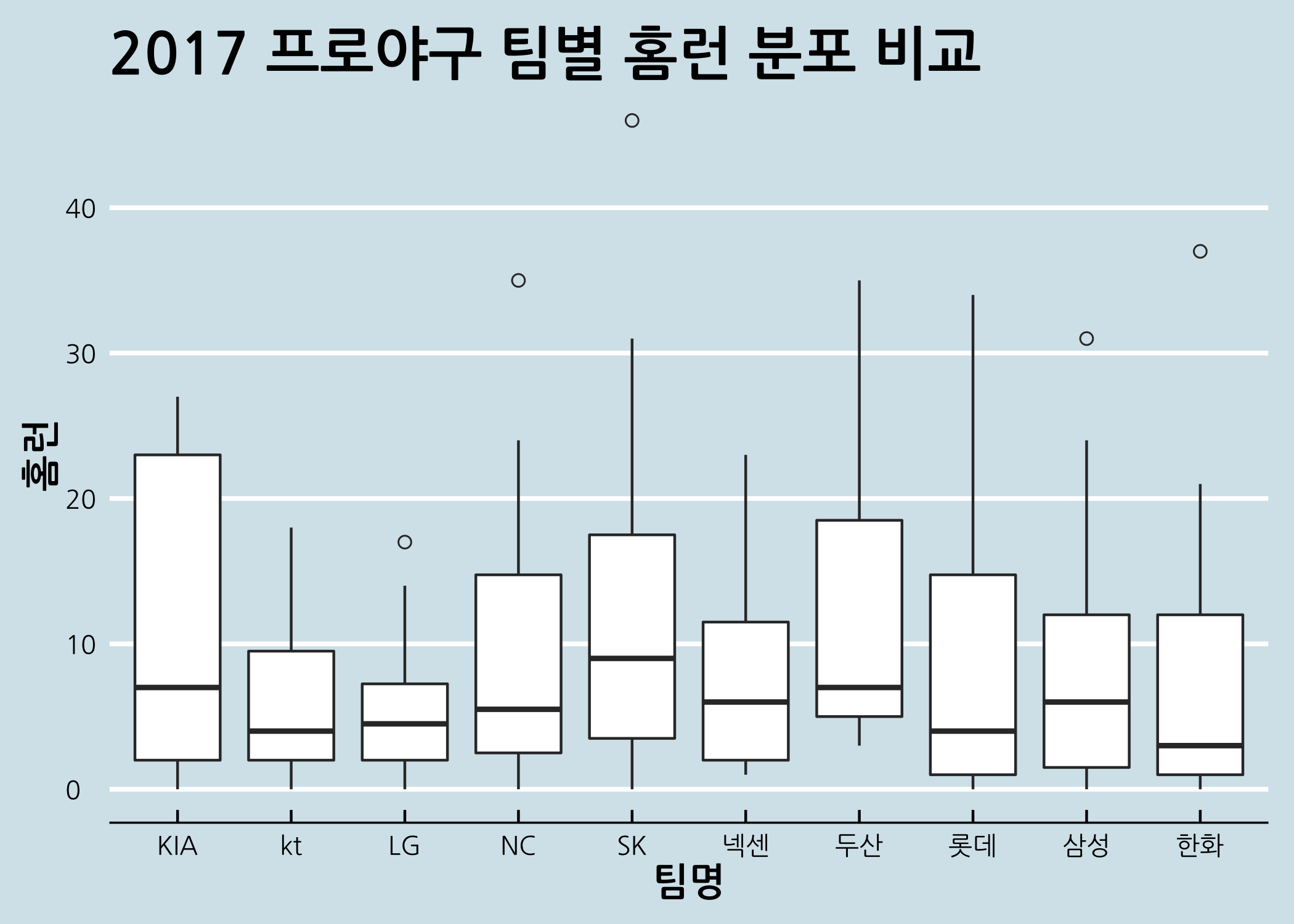
geom_boxplot()에 새로운 인자들을 추가한 것을 보셨나요? ggplot2 패키지에는 아웃라이어에 대한 표시를 입맛에 맞게 추가할 수 있습니다. 관련 인자들을 간단하게 소개하겠습니다.
- outlier.color : 아웃라이어의 테두리 색을 지정합니다.
- outlier.fill : 아웃라이어의 채우기 색을 지정합니다.
- outlier.shape : 아웃라이어의 형태를 지정합니다.
- outlier.size : 아웃라이어의 크기를 지정합니다.
- outlier.stroke : 아웃라이어의 테두리 두께를 지정합니다.
- outlier.alpha : 아웃라이어의 투명도를 지정합니다.
이미 기본 함수에서 모두 다루었던 인자들이라 크게 어렵지 않을 것입니다. 아웃라이어의 모양을 조금 바꾸고, 상자의 색을 다르게 채워보겠습니다. 이렇게 하면 범례가 새로 생깁니다.
# 아웃라이어를 빨간 '*'로 바꾸고, 상자의 색을 팀별로 다르게 채웁니다.
ggbox +
geom_boxplot(mapping = aes(fill = 팀명),
outlier.shape = '*',
outlier.color = 'red',
outlier.size = 10) +
ggtitle(label = '2017 프로야구 팀별 홈런 분포 비교') +
labs(x = '팀명',
y = '홈런') +
theme_economist() +
theme(title = element_text(size = 15,
face = 'bold',
family = 'NanumGothic'))
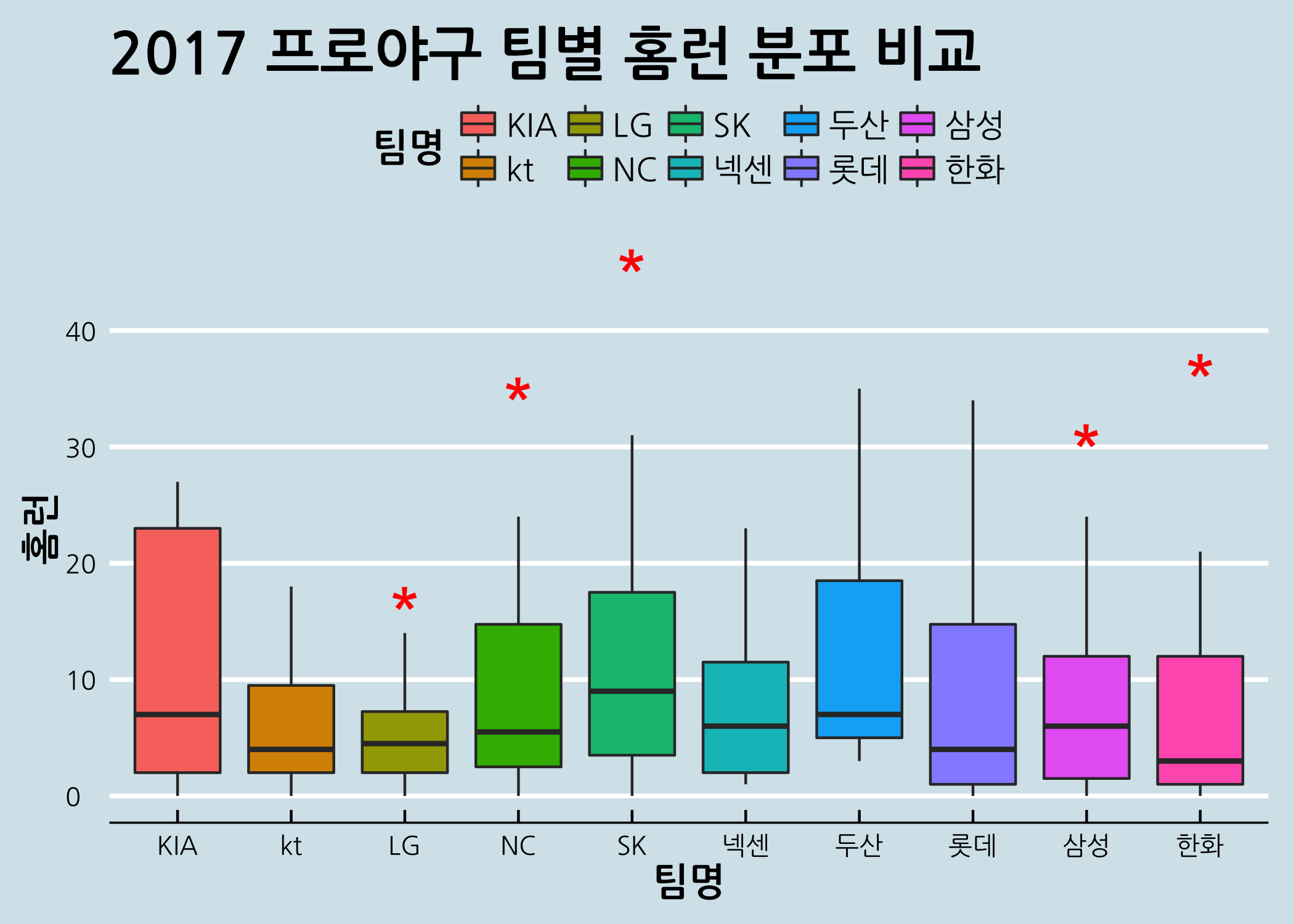
Economist 차트 이미지도 한 번 비교해볼까요? 제가 보기에는 얼핏 비슷해 보입니다만, 여러분은 어떻게 생각할지 궁금하네요.

막대그래프 그리기
ggplot2 패키지에서 막대그래프를 그릴 때 주로 사용하는 geometry function은 geom_bar()와 geom_col()입니다. 각 함수에 대한 간략한 설명을 하기 전에 위에서 했던 대로 그래프 전체에 적용할 부분을 ggplot()에 할당한 후 geom_bar()를 이용하여 기본형을 그려보겠습니다.
# 막대그래프에 사용될 데이터와 전체 에스테틱을 ggbar에 할당합니다.
ggbar <- ggplot(data = hitters,
mapping = aes(x = 팀명,
y = 홈런))
# 막대그래프 기본형을 그립니다.
ggbar + geom_bar()
위 코드를 실행시키면 Error: stat_count() must not be used with a y aesthetic.라는 에러메시지가 뜨면서 그래프가 그려지지 않을 것입니다. 왜냐하면 geom_bar() 함수는 각각의 x축에 해당하는 행의 수, 즉 이 데이터에서는 1군에 등록된 선수의 수를 세어서 막대그래프로 그려주기 때문입니다. ggbar() 함수의 mapping 인자에서 y를 제거하고 다시 그려보면 그 이유를 알 수 있습니다.
# y를 제거하고 다시 막대그래프를 그립니다.
ggplot(data = hitters,
mapping = aes(x = 팀명)) +
geom_bar()
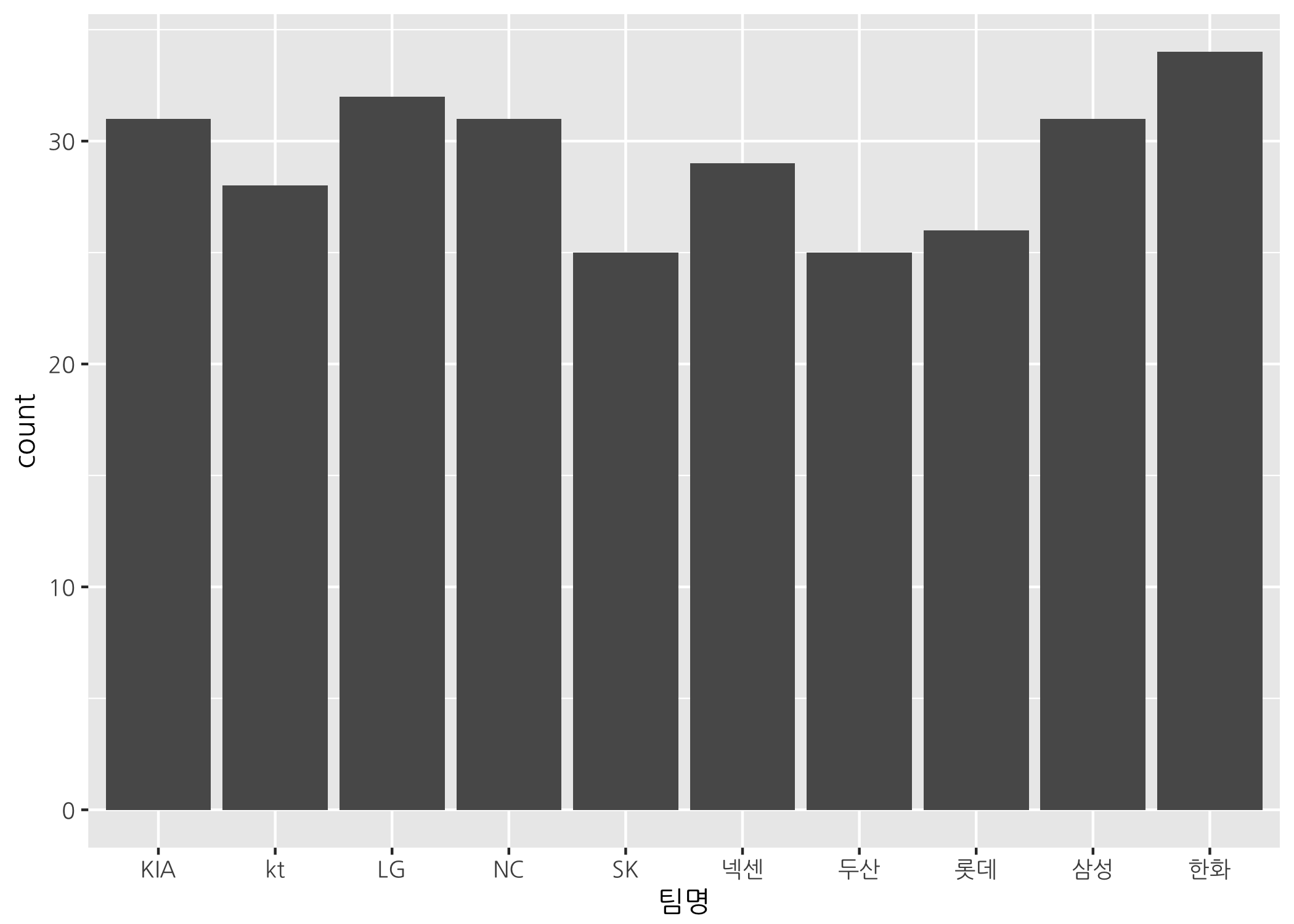
그러면 우리가 원하는 방식, 즉 각 팀별 홈런 개수를 막대그래프로 그리려면 어떻게 해야 할까요? 쉽게 할 수 있는 방법은 2가지가 있습니다. 먼저 geom_col() 함수를 사용하는 것입니다.
# geom_col() 함수로 막대그래프를 그립니다.
ggbar + geom_col()
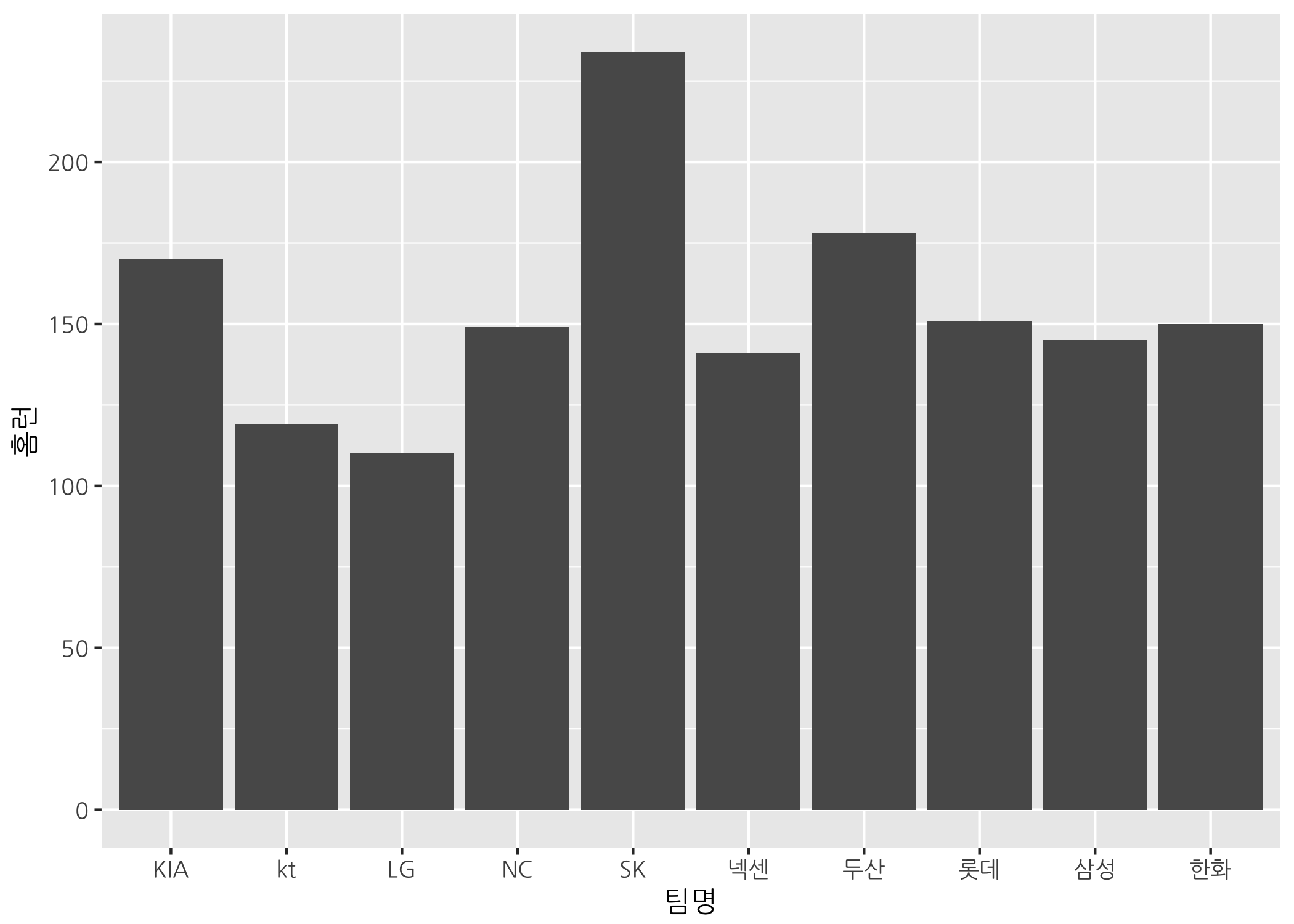
다른 방법으로는 geom_bar() 함수의 stat 인자에 기본값인 count 대신 identity로 바꿔서 할당하는 것입니다.
# stat 인자를 아래와 같이 설정한 후 막대그래프를 다시 그립니다.
ggbar + geom_bar(stat = 'identity')
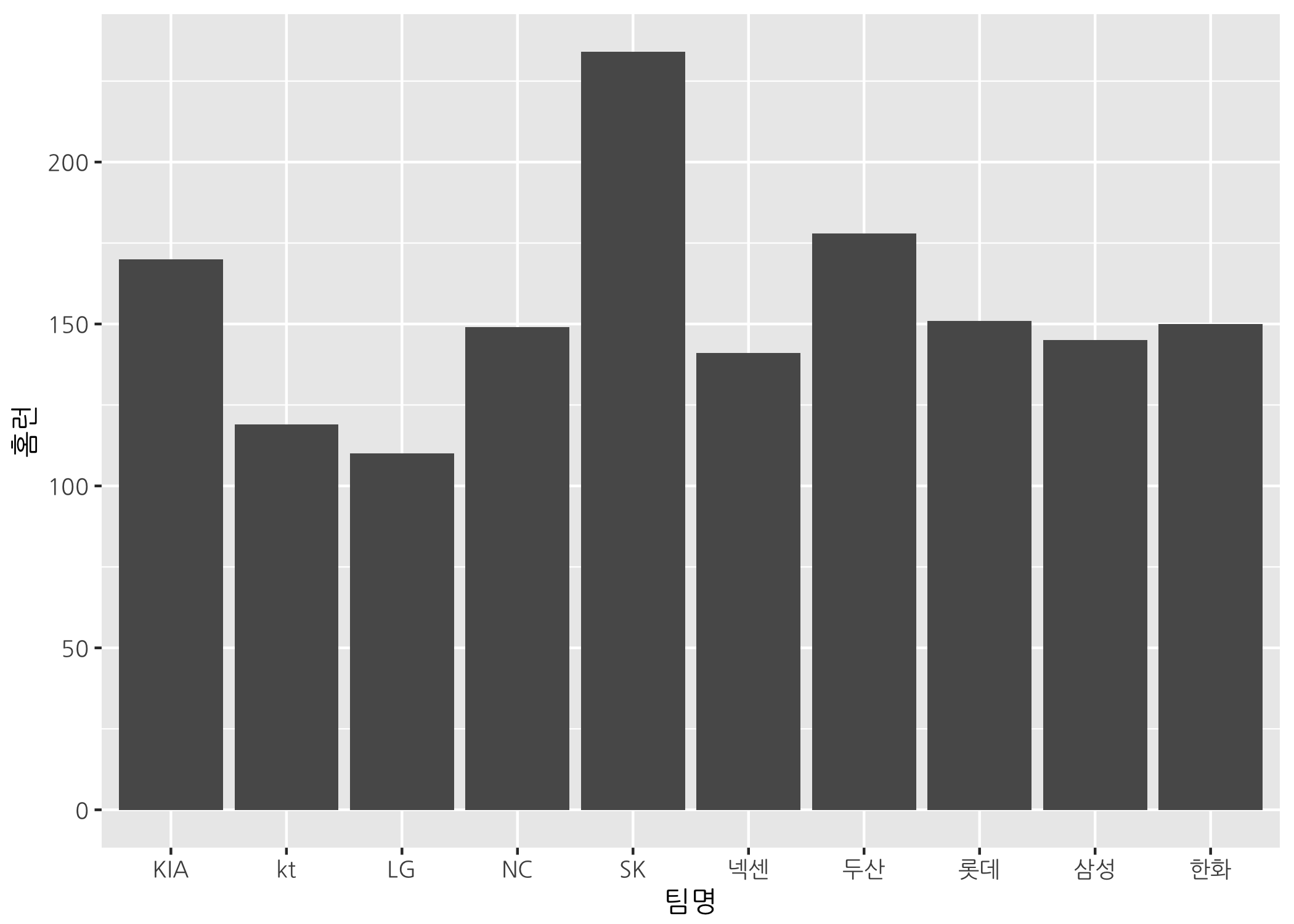
이 두 가지 방법은 동일한 효과를 보입니다. 사용하기 편한 방법을 선택하면 되겠죠? 저는 geom_col() 함수를 사용하도록 하겠습니다.
기본 그래프의 막대 색이 짙은 회색이라 그래프가 어두컴컴합니다. 막대 색을 좀 바꿔보겠습니다. 앞에서 배웠던 fill 인자를 이용하여 팀별로 다른 색을 지정해보겠습니다.
# 팀별로 채우기 색을 변경합니다.
ggbar + geom_col(mapping = aes(fill = 팀명))
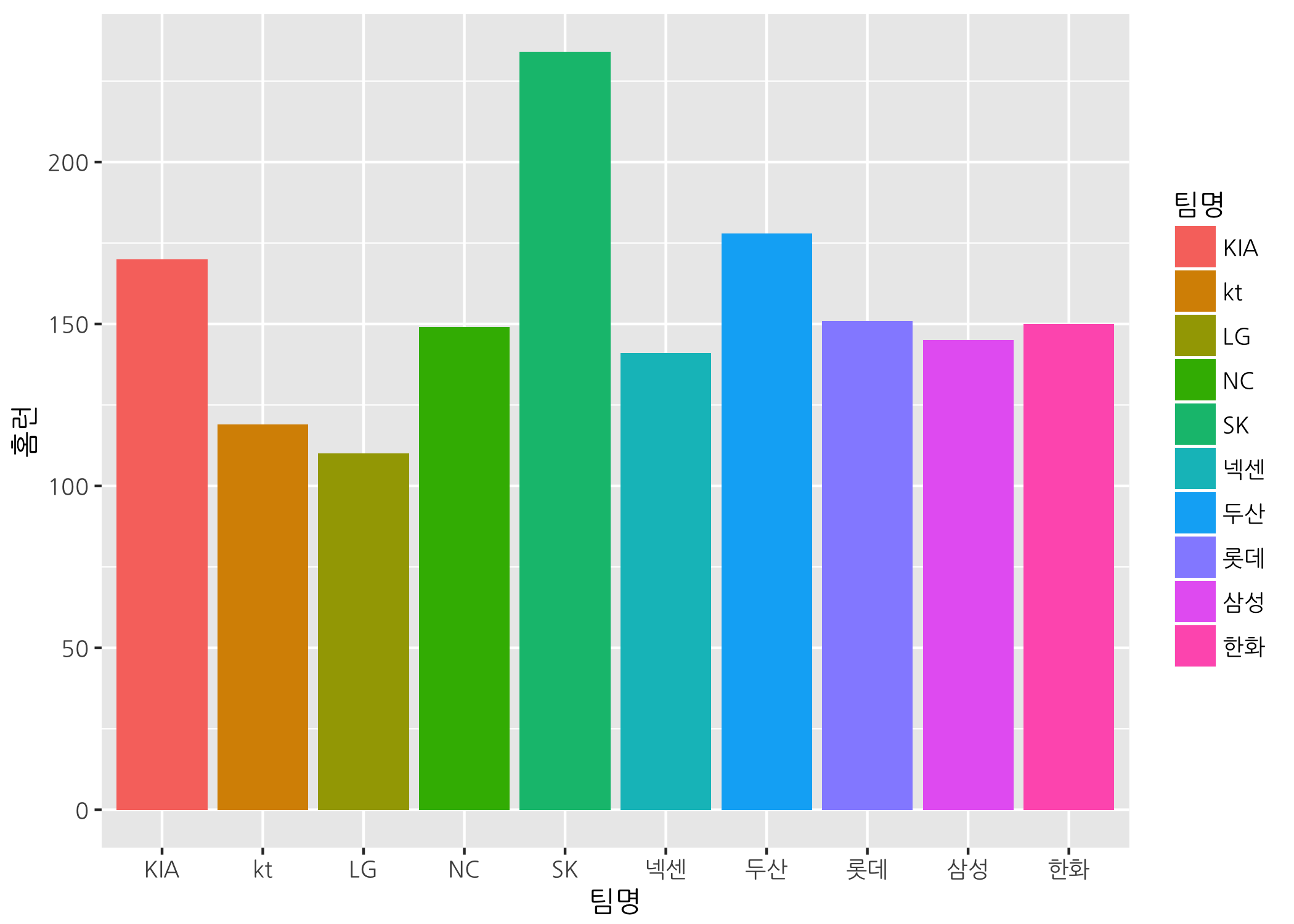
무지개색으로 막대가 채워졌습니다. 이런 색상이 마음에 들지 않으면 나만의 팔레트를 만들어서 마음에 드는 색을 지정할 수 있습니다. 먼저 R에서 제공하는 기본 팔레트를 확인해보겠습니다. RColorBrewer 패키지를 불러와야 합니다. 이 패키지가 설치되지 않은 분은 먼저 패키지를 설치하고 불러오기 바랍니다.
# 필요 패키지를 불러옵니다.
library(RColorBrewer)
# R에서 제공하는 기본 팔레트를 확인합니다.
display.brewer.all()
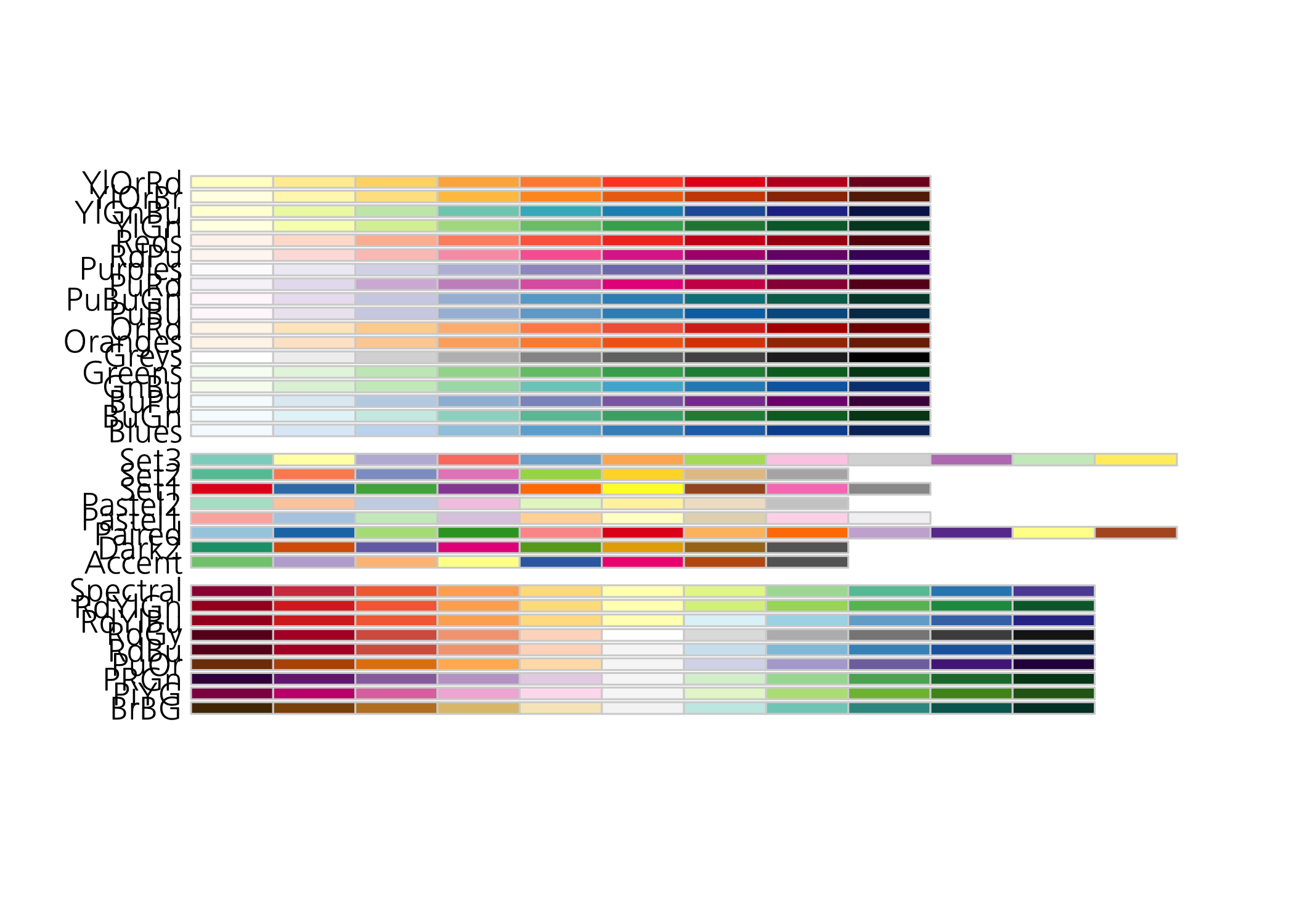
상당히 많은 팔레트가 제공되고 있습니다. 한 번에 많은 팔레트가 출력되다보니 뭐가 뭔지 알아보기도 힘들어서 마음에 드는 팔레트를 고르기 어렵습니다. 팔레트를 하나씩 살펴보는 방법을 알려드리겠습니다. 직접 마음에 드는 걸 골라보기 바랍니다.
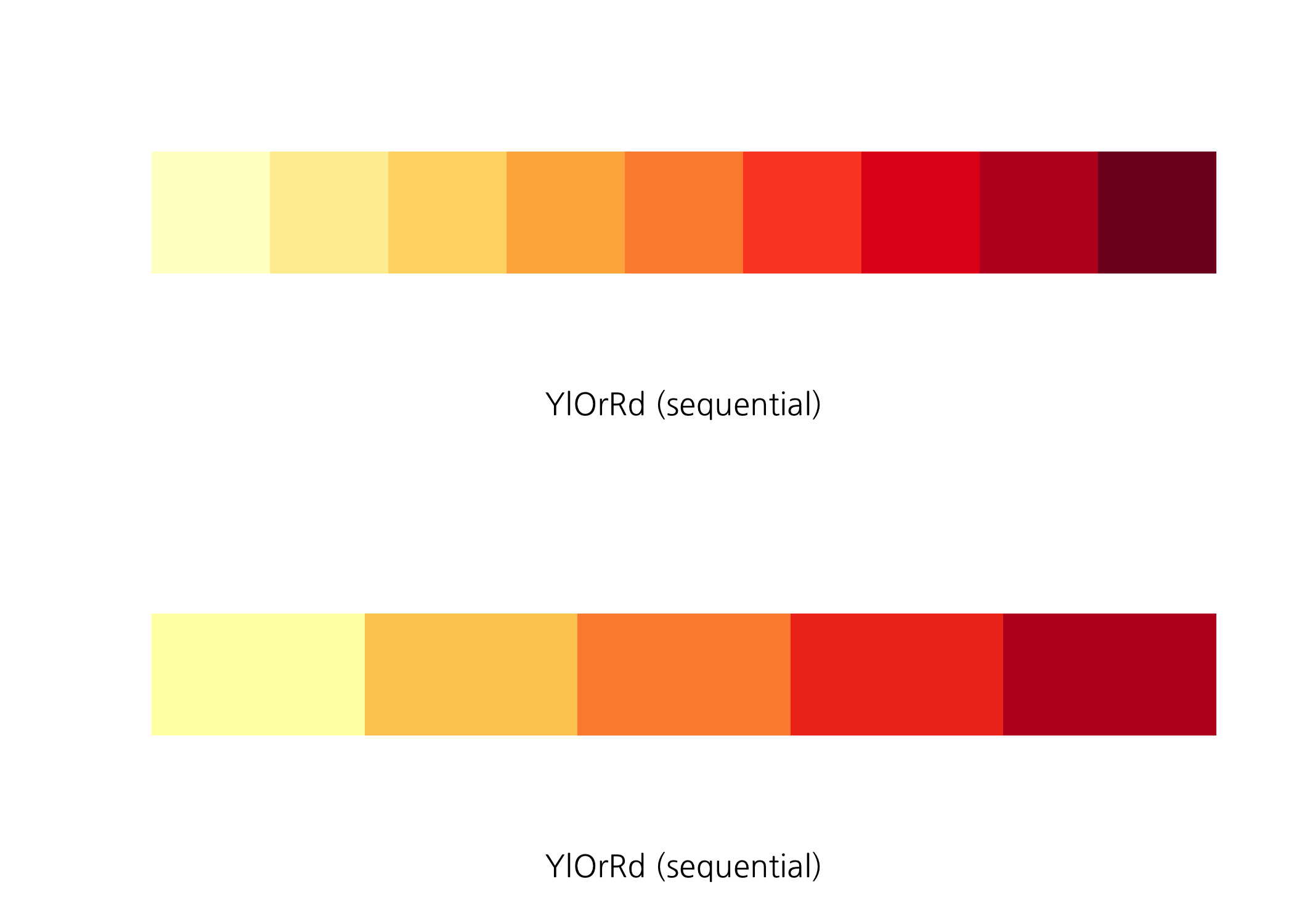
저는 YlOrRd 팔레트를 선택했습니다. 노랑-주황-빨강의 9가지 색으로 구성된 팔레트입니다. 이 팔레트가 가진 색의 스펙트럼을 확인하려면 display.brewer.pal() 함수를 사용하면 됩니다. 이 함수는 n과 name이라는 두 개의 인자를 갖는데요. n에는 색의 개수, name에는 팔레트 이름을 할당하면 됩니다. 아래와 같이 하시면 금세 이해할 수 있을 것입니다.
# 출력 화면을 가로로 이등분합니다.
par(mfrow = c(2, 1))
# 마음에 드는 팔레트를 골라 색상을 확인합니다.
display.brewer.pal(n = 9, name = 'YlOrRd')
display.brewer.pal(n = 5, name = 'YlOrRd')
# 출력 화면을 원래대로 합니다.
par(mfrow = c(1, 1))
여기에서 주의할 점은 각 팔레트마다 색의 개수가 서로 다르며, display.brewer.pal() 함수의 n 인자에 할당할 수 있는 값은 해당 팔레트가 가진 색의 개수를 넘지 못한다는 것입니다.
저는 YlOrRd 팔레트가 마음에 듭니다. 여러분은 마음에 드는 팔레트를 발견할 때까지 몇 번이고 반복해서 찾아보기 바랍니다.
마음에 드는 팔레트의 일부 색상을 나만의 팔레트로 지정하려면 다음과 같이 하면 됩니다. 핵심은 16진법 색상코드로 구성된 벡터를 만드는 것입니다.
# 나만의 팔레트를 만듭니다.
myPal <- brewer.pal(n = 9, name = 'YlOrRd')[c(3, 5, 7)]
# 나만의 팔레트를 확인합니다. 16진법 색상코드값만 출력됩니다.
print(myPal)
## [1] "#FED976" "#FD8D3C" "#E31A1C"
새로 만든 나만의 팔레트를 막대그래프의 채우기 색으로 사용해보겠습니다.
# 나만의 팔레트를 이용하려면 gradientn()을 사용해야 합니다.
ggbar +
geom_col(mapping = aes(fill = 홈런)) +
scale_fill_gradientn(colors = myPal)
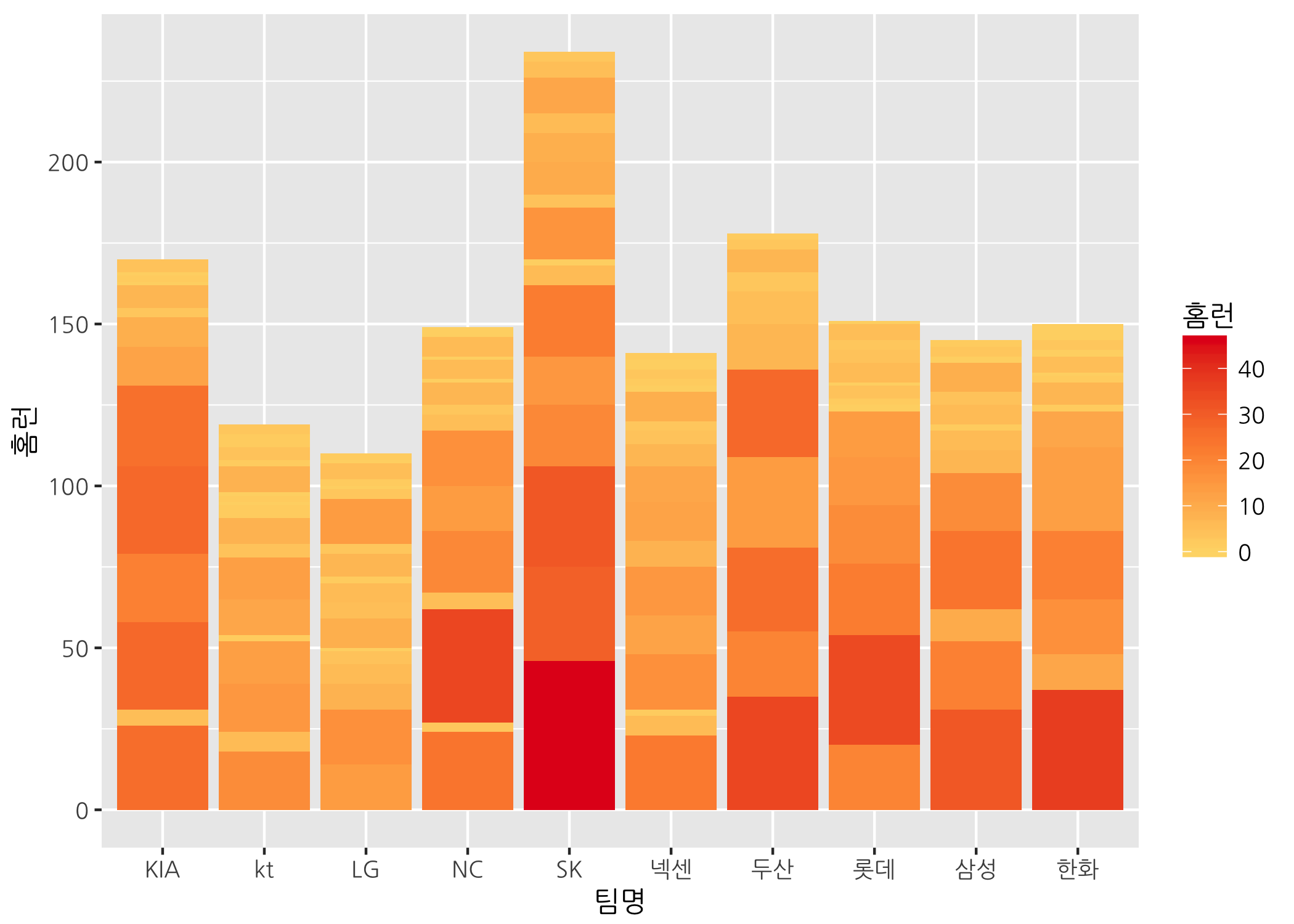
그래프가 참으로 오묘하게 그려집니다. 즉, 각각의 팀에 속한 개별 선수들의 홈런 개수를 색으로 칠해 알록달록한 그래프가 그려졌습니다. 만약 팀별로 같은 색상을 나타내게 하려면 어떻게 해야 할까요? 아마도 팀별 요약 데이터를 새로 만들어서 하는 방법이 가장 쉬울 것 같습니다.
R에서 데이터를 요약하는 방법은 무수히 많겠지만, 저는 dplyr 패키지를 주로 사용하는 편입니다. 처음 R을 배웠을 때에는 10년 넘게 SAS와 SQL에 익숙했던 터라 sqldf 패키지의 SQL 문법을 사용했었고, 그 뒤로는 apply 계열의 함수들을 쓰다가 지금은 dplyr 패키지로 옮겨왔습니다. 조만간 dplyr 패키지에 대한 간략한 사용법을 따로 정리하기로 약속하고, 오늘은 select(), group_by(), summarize() 및 mutate() 함수들을 이용하는 코드만 소개해드리겠습니다.
아래의 코드를 간단하게 설명하자면, hitters 데이터프레임에서 팀명부터 타점까지 7개 컬럼만 선택한 다음, 팀명과 올스타팀을 기준으로 summarize() 함수 안에서 숫자 데이터를 요약하고, mutate() 함수 안에서 새로운 파생변수들을 생성하라는 것입니다. n() 함수는 행의 개수를 셉니다.
# 관심 있는 선수 스탯을 팀별로 요약하여 새로운 데이터프레임을 만듭니다.
teamStat <- hitters %>%
select(c('팀명', '올스타팀', '타석', '타수', '안타', '홈런', '득점', '타점')) %>%
group_by(팀명, 올스타팀) %>%
summarize(등록 = n(),
타석 = sum(타석),
타수 = sum(타수),
안타 = sum(안타),
홈런 = sum(홈런),
득점 = sum(득점),
타점 = sum(타점)) %>%
mutate(타율 = round(안타/타수, digits = 3L),
인당안타 = round(안타/등록, digits = 2L),
인당홈런 = round(홈런/등록, digits = 2L),
인당득점 = round(득점/등록, digits = 2L),
인당타점 = round(타점/등록, digits = 2L))
# 데이터의 구조를 파악합니다.
str(object = teamStat)
## Classes 'grouped_df', 'tbl_df', 'tbl' and 'data.frame': 10 obs. of 14 variables:
## $ 팀명 : Factor w/ 10 levels "KIA","kt","LG",..: 1 2 3 4 5 6 7 8 9 10
## $ 올스타팀: chr "나눔" "드림" "나눔" "나눔" ...
## $ 등록 : int 31 28 32 31 25 29 25 26 31 34
## $ 타석 : num 5841 5485 5614 5790 5564 ...
## $ 타수 : num 5142 4937 4944 5079 4925 ...
## $ 안타 : num 1554 1360 1390 1489 1337 ...
## $ 홈런 : num 170 119 110 149 234 141 178 151 145 150
## $ 득점 : num 906 655 699 786 761 789 849 743 757 737
## $ 타점 : num 868 625 663 739 733 748 812 697 703 684
## $ 타율 : num 0.302 0.275 0.281 0.293 0.271 0.29 0.294 0.285 0.279 0.287
## $ 인당안타: num 50.1 48.6 43.4 48 53.5 ...
## $ 인당홈런: num 5.48 4.25 3.44 4.81 9.36 4.86 7.12 5.81 4.68 4.41
## $ 인당득점: num 29.2 23.4 21.8 25.4 30.4 ...
## $ 인당타점: num 28 22.3 20.7 23.8 29.3 ...
## - attr(*, "vars")= chr "팀명"
## - attr(*, "labels")='data.frame': 10 obs. of 1 variable:
## ..$ 팀명: Factor w/ 10 levels "KIA","kt","LG",..: 1 2 3 4 5 6 7 8 9 10
## ..- attr(*, "vars")= chr "팀명"
## ..- attr(*, "drop")= logi TRUE
## - attr(*, "indices")=List of 10
## ..$ : int 0
## ..$ : int 1
## ..$ : int 2
## ..$ : int 3
## ..$ : int 4
## ..$ : int 5
## ..$ : int 6
## ..$ : int 7
## ..$ : int 8
## ..$ : int 9
## - attr(*, "drop")= logi TRUE
## - attr(*, "group_sizes")= int 1 1 1 1 1 1 1 1 1 1
## - attr(*, "biggest_group_size")= int 1
새로 만든 teamStat 객체의 구조를 확인해보니, 10행 14열로 구성된 tibble이라는 것을 알 수 있습니다. 팀명과 올스타팀만 범주형이고 나머지 컬럼들은 모두 숫자형 벡터입니다. 다시 막대그래프 그리기로 돌아가보겠습니다.
# 팀별 스탯 데이터로 막대그래프로 ggbar에 재할당합니다.
ggbar <- ggplot(data = teamStat,
mapping = aes(x = 팀명,
y = 홈런))
# 팀별 스탯 데이터로 막대그래프를 그립니다.
ggbar +
geom_col(mapping = aes(fill = 홈런)) +
scale_fill_gradientn(colors = myPal)
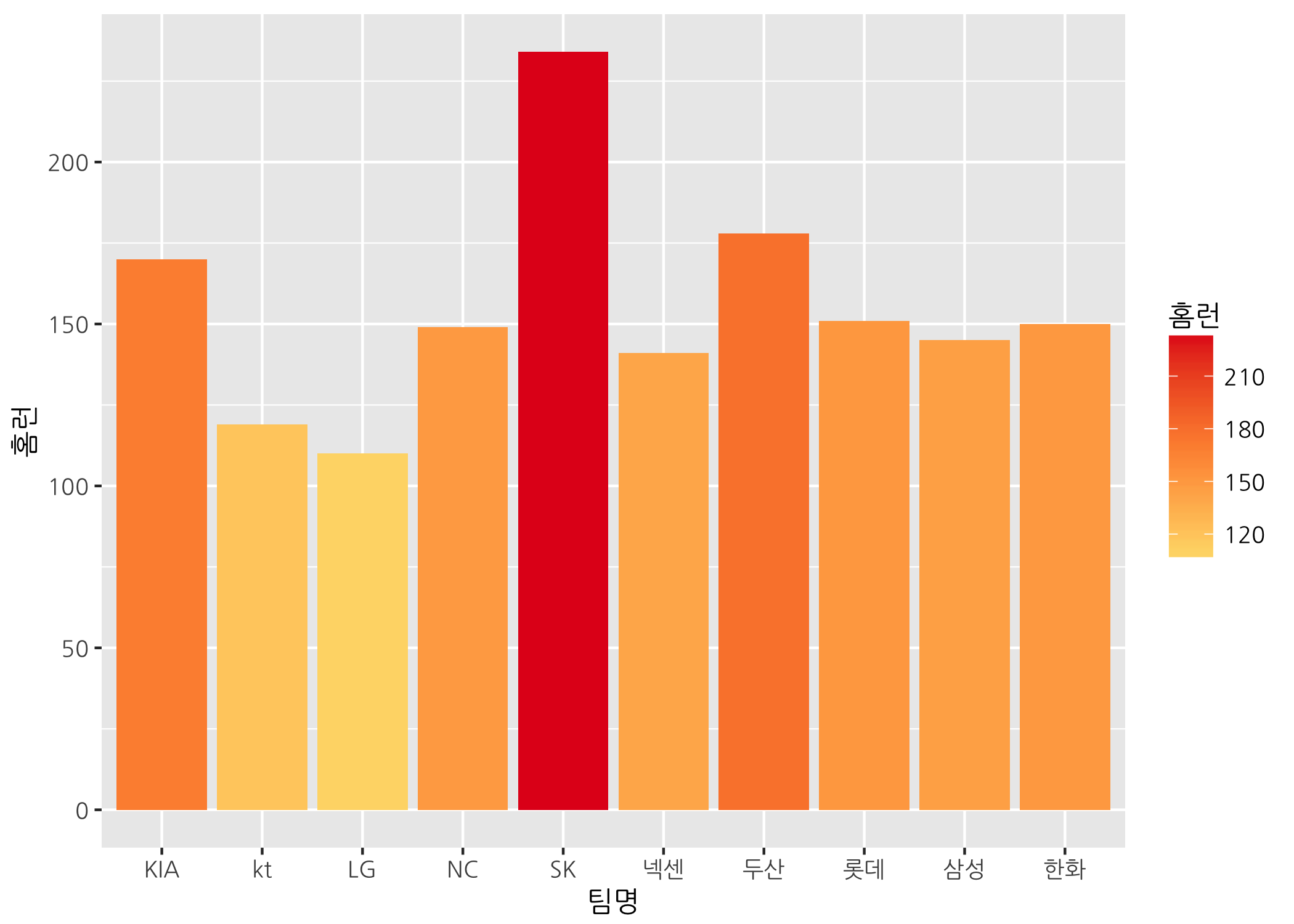
ggplot2 패키지의 장점은 그래프에 다른 컬럼을 기준으로 채우기 색을 아주 쉽게 변경할 수 있다는 것입니다. 일종의 차원 추가가 됩니다. 막대 그래프의 채우기 색을 팀타율 기준으로 바꿔보겠습니다.
# 팀 타율 기준으로 채우기 색을 바꿉니다.
ggbar +
geom_col(mapping = aes(fill = 타율)) +
scale_fill_gradientn(colors = myPal)
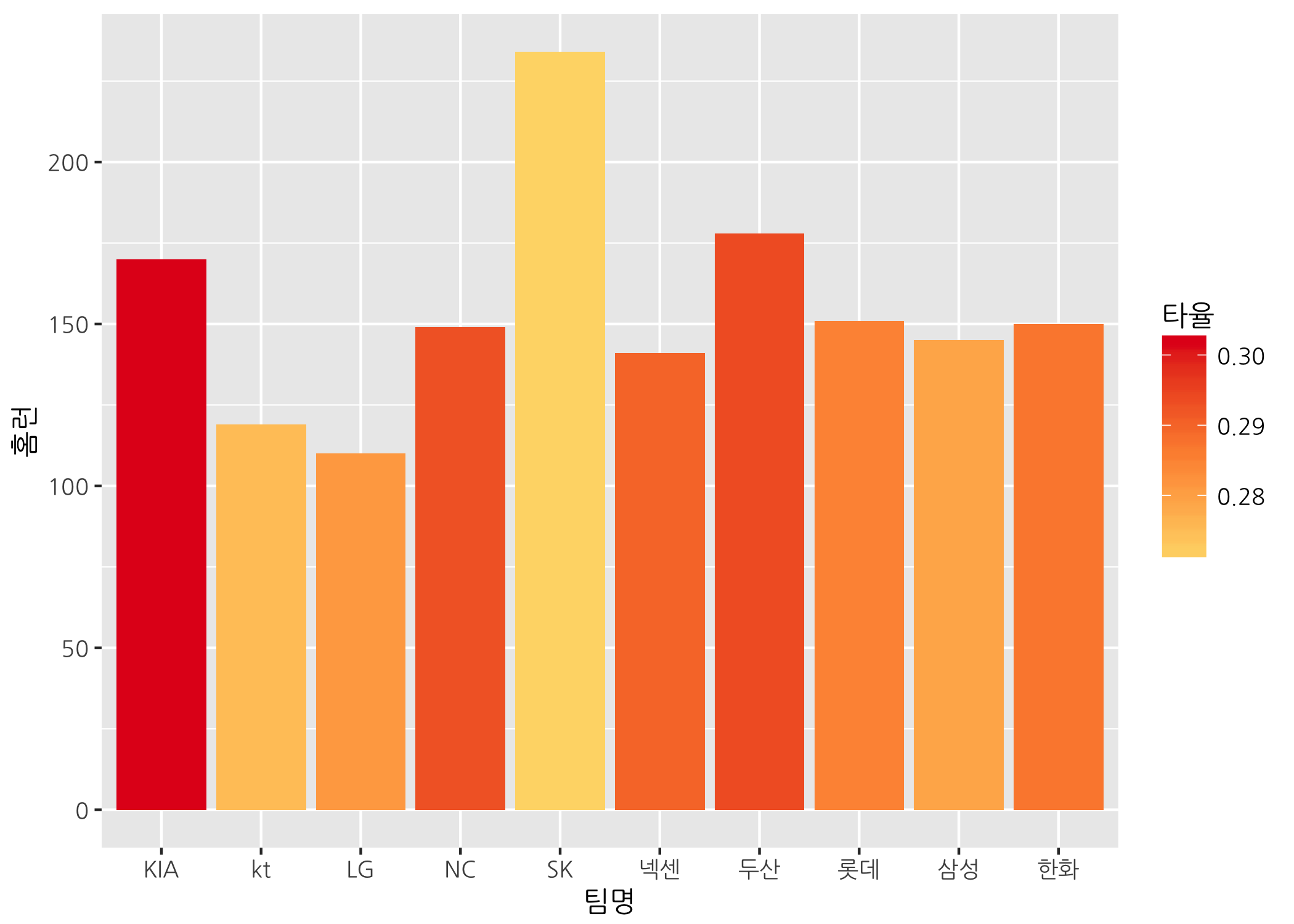
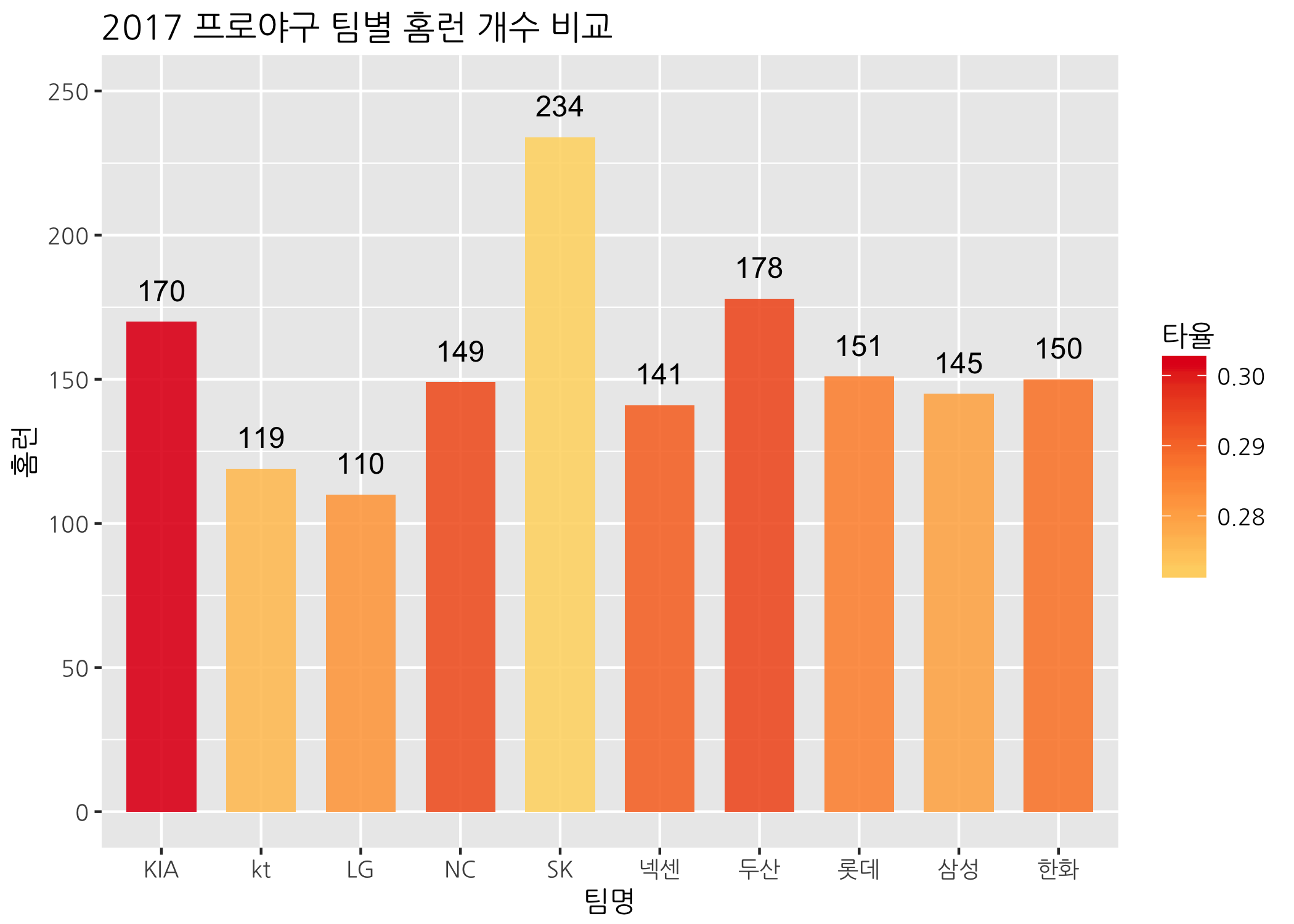
위 그래프와 달리 비룡군단은 팀 홈런 개수가 가장 많지만 팀 타율은 가장 낮은 걸로 보입니다. 팀 타율이 가장 높은 팀은 타이거즈이구요.
막대가 서로 붙어있으니 답답해 보입니다. 막대 너비를 조금 줄여보도록 하겠습니다.
# 막대 너비를 조정합니다. (width는 1을 기준으로 배수로 적용됩니다.)
ggbar +
geom_col(mapping = aes(fill = 타율),
width = 0.7) +
scale_fill_gradientn(colors = myPal)
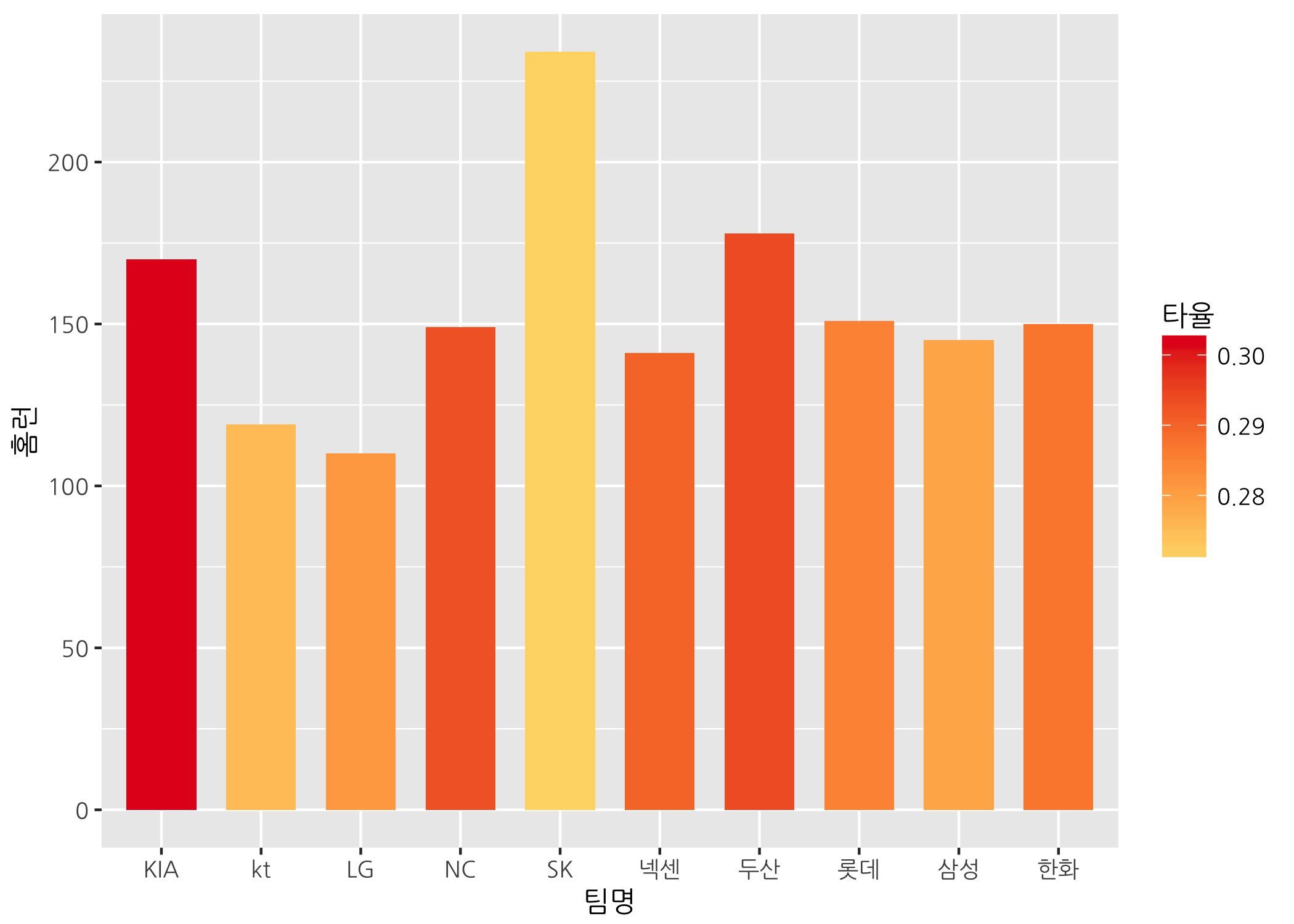
막대의 투명도도 조절할 수 있습니다. alpha 인자명 생각나시죠?
# 막대의 투명도를 조정합니다. (alpha는 0일 때 투명, 1일 때 불투명입니다.)
ggbar +
geom_col(mapping = aes(fill = 타율),
width = 0.7,
alpha = 0.6) +
scale_fill_gradientn(colors = myPal)
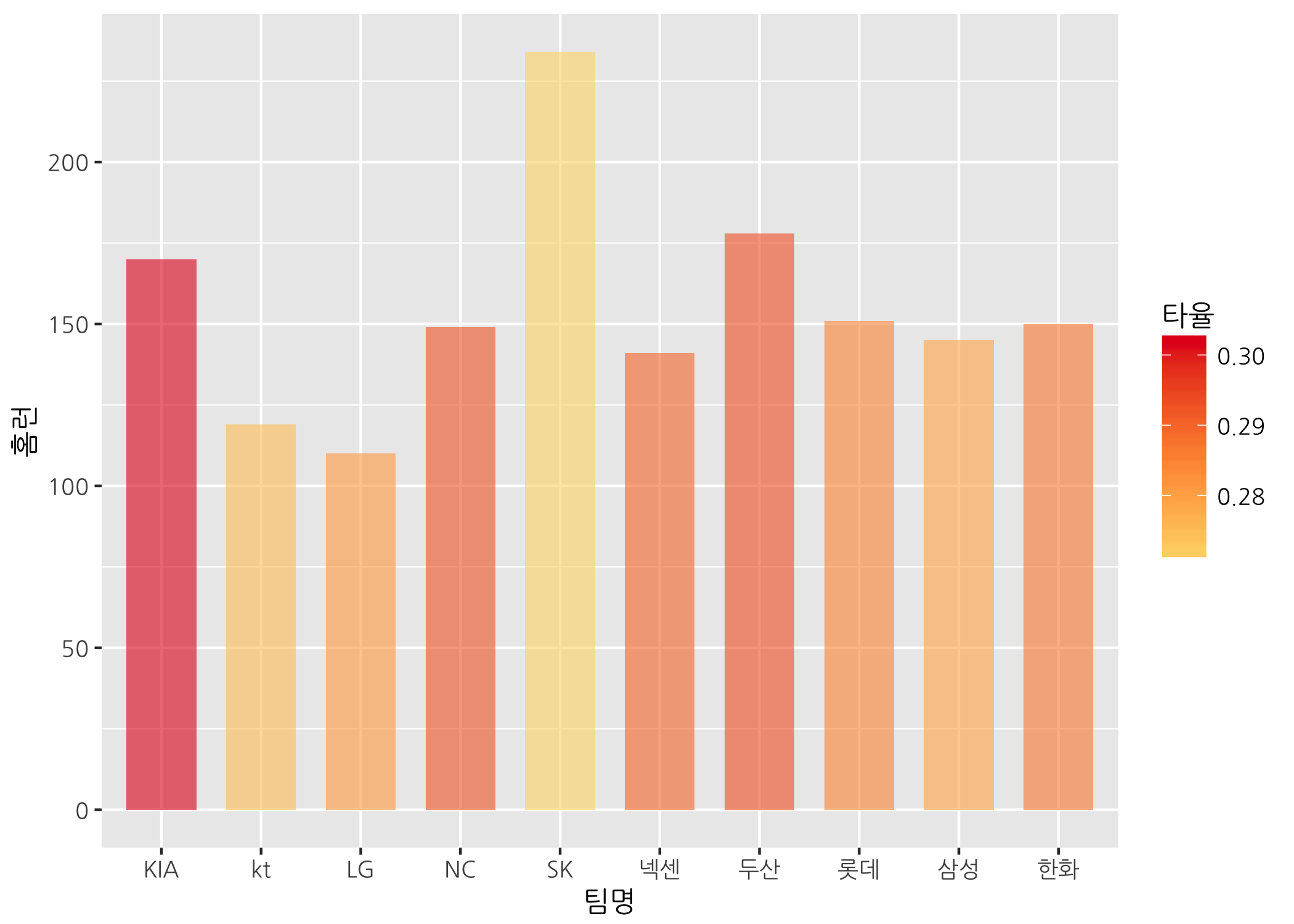
geom_text() 함수를 사용하면 막대 위에 홈런 개수를 추가할 수 있습니다. 글자 출력 위치를 조정하는 인자로는 vjust와 hjust가 있습니다. vjust는 글자가 출력될 위치를 세로 방향으로 조절하는데 0.5일 때 막대 높이 중앙에 위치하고, 0.5보다 작으면 위로, 0.5보다 크면 아래로 이동시킵니다. hjust는 글자가 출력될 위치를 가로 방향으로 조절합니다. 0.5일 때 막대 높이에서 가운데에 위치하고, 0.5보다 작으면 오른쪽으로, 0.5보다 크면 왼쪽으로 이동시킵니다. 둘 다 숫자의 절대값이 클수록 0.5에서 멀어집니다.
# geom_text() 함수로 텍스트를 추가할 수 있습니다.
# 막대 위에 홈런 개수를 출력합니다.
ggbar +
geom_col(mapping = aes(fill = 타율),
width = 0.7,
alpha = 0.9) +
scale_fill_gradientn(colors = myPal) +
geom_text(mapping = aes(label = 홈런),
size = 4,
vjust = -1) +
scale_y_continuous(limits = c(0, 250))
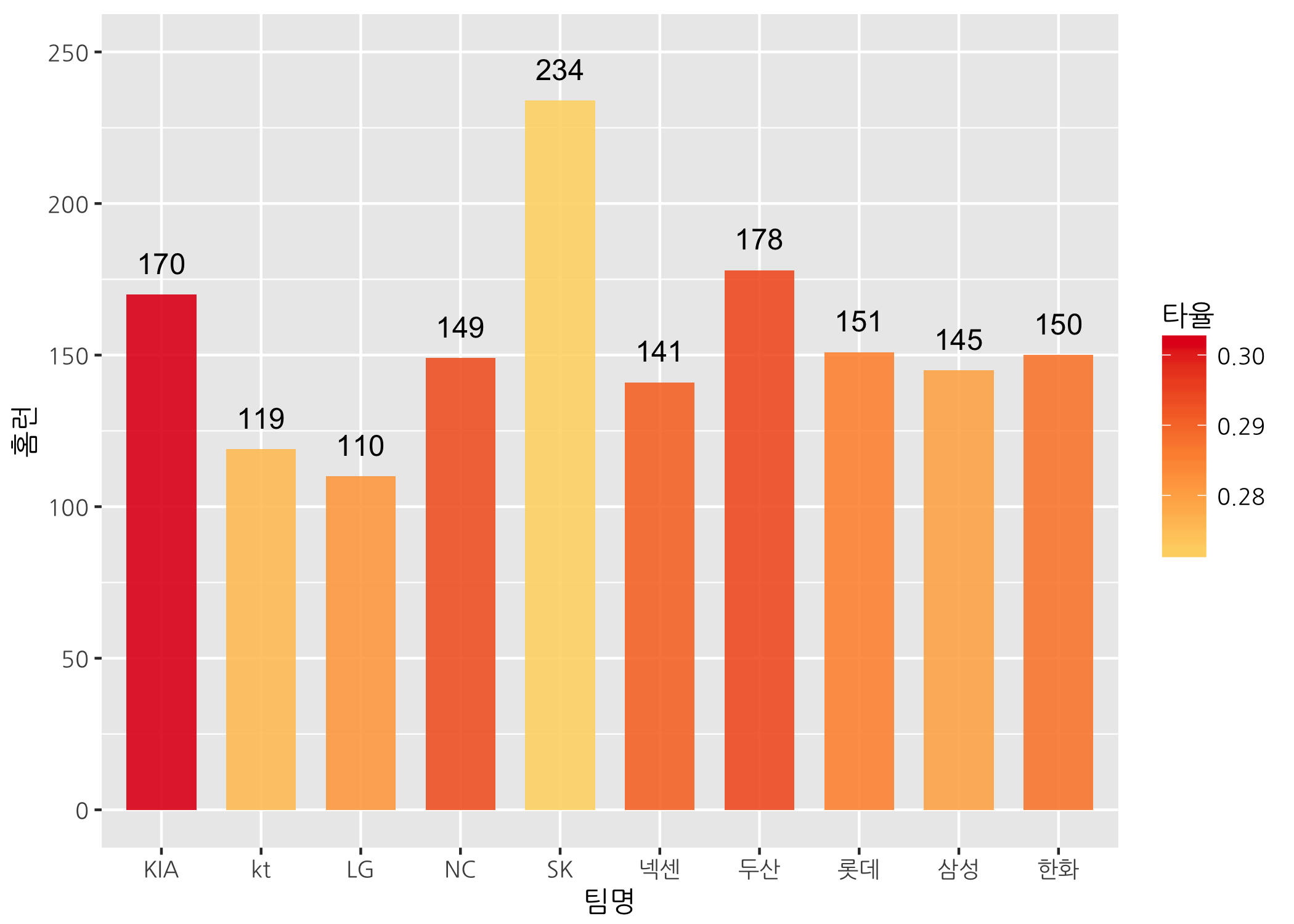
막대그래프의 메인 제목을 달아볼까요?
# ggtitle() 함수로 메인 제목을 삽입합니다.
ggbar +
geom_col(mapping = aes(fill = 타율),
width = 0.7,
alpha = 0.9) +
scale_fill_gradientn(colors = myPal) +
geom_text(mapping = aes(label = 홈런),
size = 4,
vjust = -1) +
scale_y_continuous(limits = c(0, 250)) +
ggtitle(label = '2017 프로야구 팀별 홈런 개수 비교')
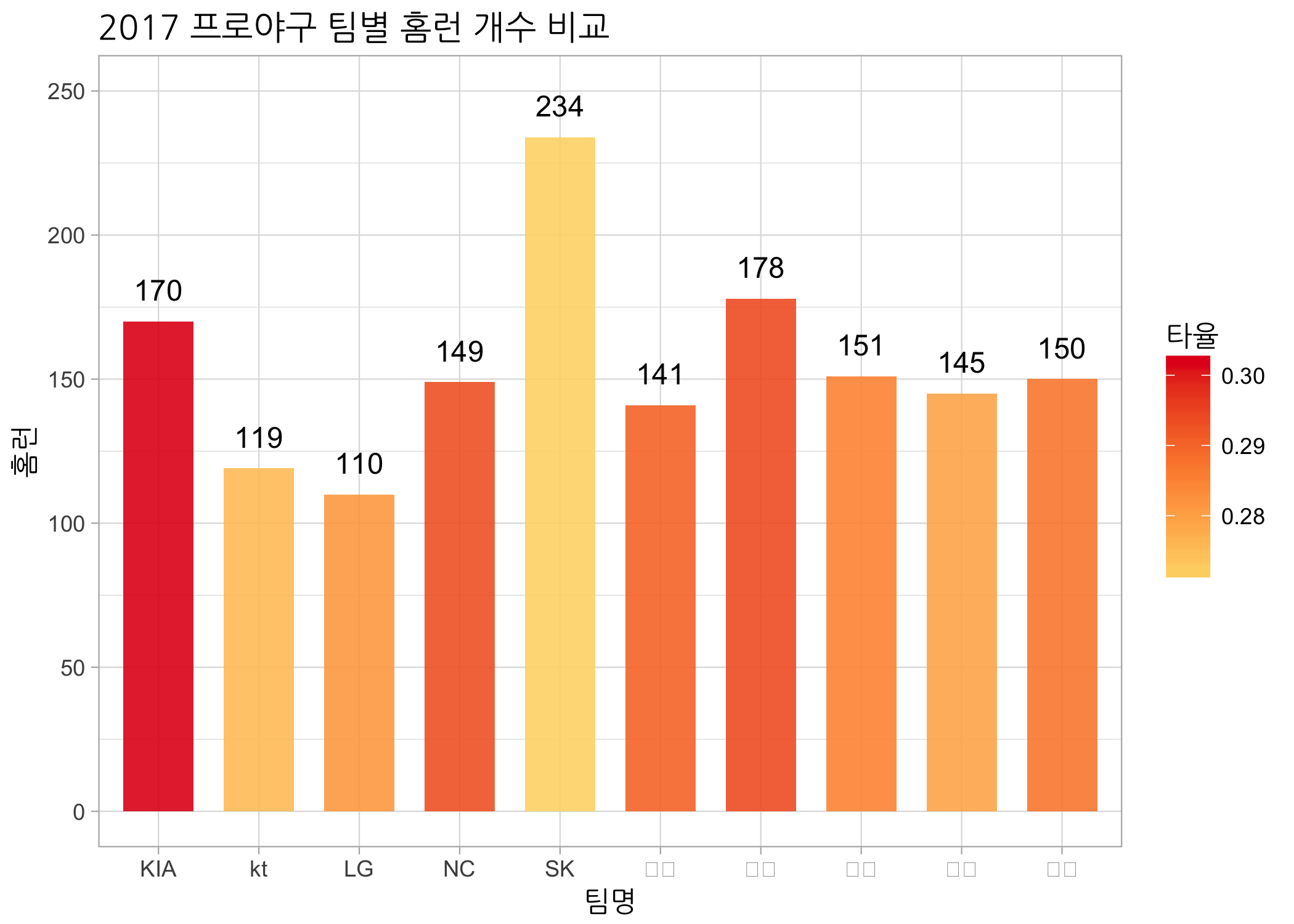
막대그래프 역시 테마를 적용해보는 것으로 마무리짓겠습니다. 이번에는 깔끔한 theme_light()를 적용해보겠습니다.
# ggtitle() 함수로 메인 제목을 삽입합니다.
ggbar +
geom_col(mapping = aes(fill = 타율),
width = 0.7,
alpha = 0.9) +
scale_fill_gradientn(colors = myPal) +
geom_text(mapping = aes(label = 홈런),
size = 4,
vjust = -1) +
scale_y_continuous(limits = c(0, 250)) +
ggtitle(label = '2017 프로야구 팀별 홈런 개수 비교') +
theme_light()
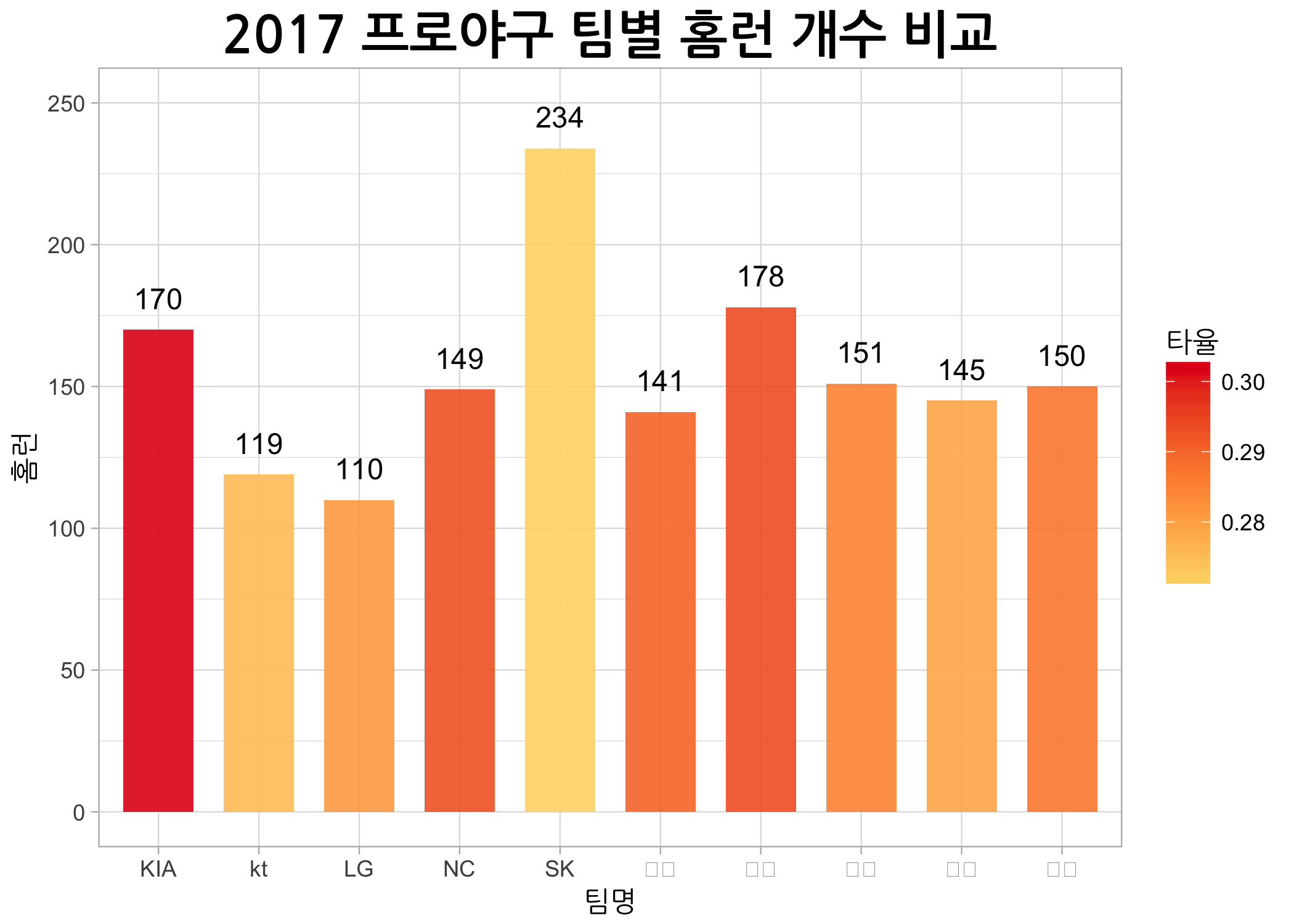
그런데 테마를 적용하니 x축에 있는 한글 팀명이 모두 네모로 바뀝니다. 아마 Mac을 사용하시는 분들만 그렇게 되는 것 같습니다. 이번 기회에 맛보기로 theme() 함수를 사용해보겠습니다. 기왕 하는 김에 제목 글씨 크기를 키우고 굵게한 다음 가운데에 오도록 변경해보겠습니다.
# ggtitle() 함수로 메인 제목을 삽입합니다.
ggbar +
geom_col(mapping = aes(fill = 타율),
width = 0.7,
alpha = 0.9) +
scale_fill_gradientn(colors = myPal) +
geom_text(mapping = aes(label = 홈런),
size = 4,
vjust = -1) +
scale_y_continuous(limits = c(0, 250)) +
ggtitle(label = '2017 프로야구 팀별 홈런 개수 비교') +
theme_light() +
theme(axis.title = element_text(family = 'NanumGothic'),
plot.title = element_text(face = 'bold',
size = 20,
hjust = 0.5))
선그래프 그리기
이번데는 선그래프를 그려보는 법을 알아보도록 하겠습니다. 시작은 선그래프의 기본형입니다. geom_line() 함수를 사용하면 됩니다.
# 선그래프에 사용될 데이터와 전체 에스테틱을 ggline에 할당합니다.
ggline <- ggplot(data = teamStat,
mapping = aes(x = 타율,
y = 인당홈런))
# 선그래프의 기본형을 그립니다.
ggline + geom_line()
생각보다 볼품 없네요. 이제 몇 가지 인자를 추가해보겠습니다. 선을 굵게 하고, 선의 색을 빨간색으로 변경하는 것으로 시작해보죠.
# 선을 굵게 하고, 선의 색을 빨간색을 바꿉니다.
ggline +
geom_line(size = 1,
color = 'red')
혹시 선을 굵게 한다고 해서 stroke 인자를 떠올리신 건 아니죠? stroke는 산점도에서 점 테두리 두께를 조절할 때 사용하는 인자입니다. 선그래프에서는 size로 선 두께를 조절합니다.
이번에는 각 팀별로 점을 추가해보도록 하겠습니다. geom_point() 함수를 추가해주면 간단하게 해결됩니다.
# 선을 굵게 하고, 선의 색을 빨간색을 바꿉니다.
ggline +
geom_line(size = 1,
color = 'red') +
geom_point(shape = 21,
size = 3,
stroke = 1.2,
color = 'red',
fill = 'white')
팀명을 점 옆에 붙여주면 더 좋을 것 같습니다. geom_text() 함수와 goem_label() 함수를 번갈아 사용해보도록 하겠습니다. 여러분은 둘 다 해보고 마음에 드는 걸로 연습을 반복하면 되겠죠?
# geom_text() 함수를 이용하여 선 왼쪽에 팀명을 출력합니다.
ggline +
geom_line(size = 1,
color = 'red') +
geom_point(shape = 21,
size = 3,
stroke = 1.2,
color = 'red',
fill = 'white') +
geom_text(mapping = aes(label = 팀명),
hjust = 1.3,
size = 4,
family = 'NanumGothic',
fontface = 'bold') +
scale_x_continuous(limits = c(0.269, 0.302))
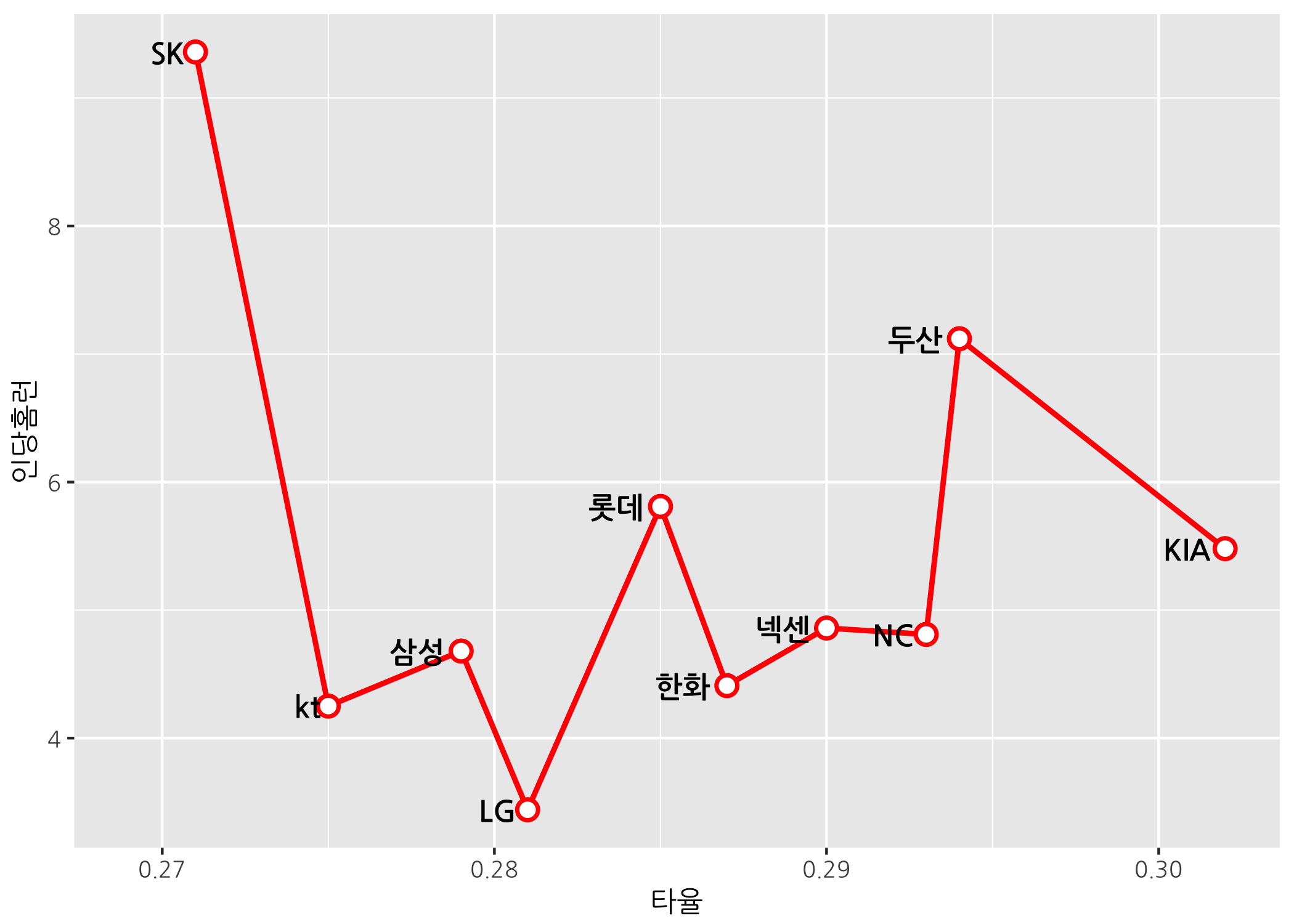
# geom_label() 함수를 이용하여 선 왼쪽에 팀명을 출력합니다.
ggline +
geom_line(size = 1,
color = 'red') +
geom_point(shape = 21,
size = 3,
stroke = 1.2,
color = 'red',
fill = 'white') +
geom_label(mapping = aes(label = 팀명),
hjust = 1.3,
size = 4,
family = 'NanumGothic',
fontface = 'bold') +
scale_x_continuous(limits = c(0.269, 0.302))
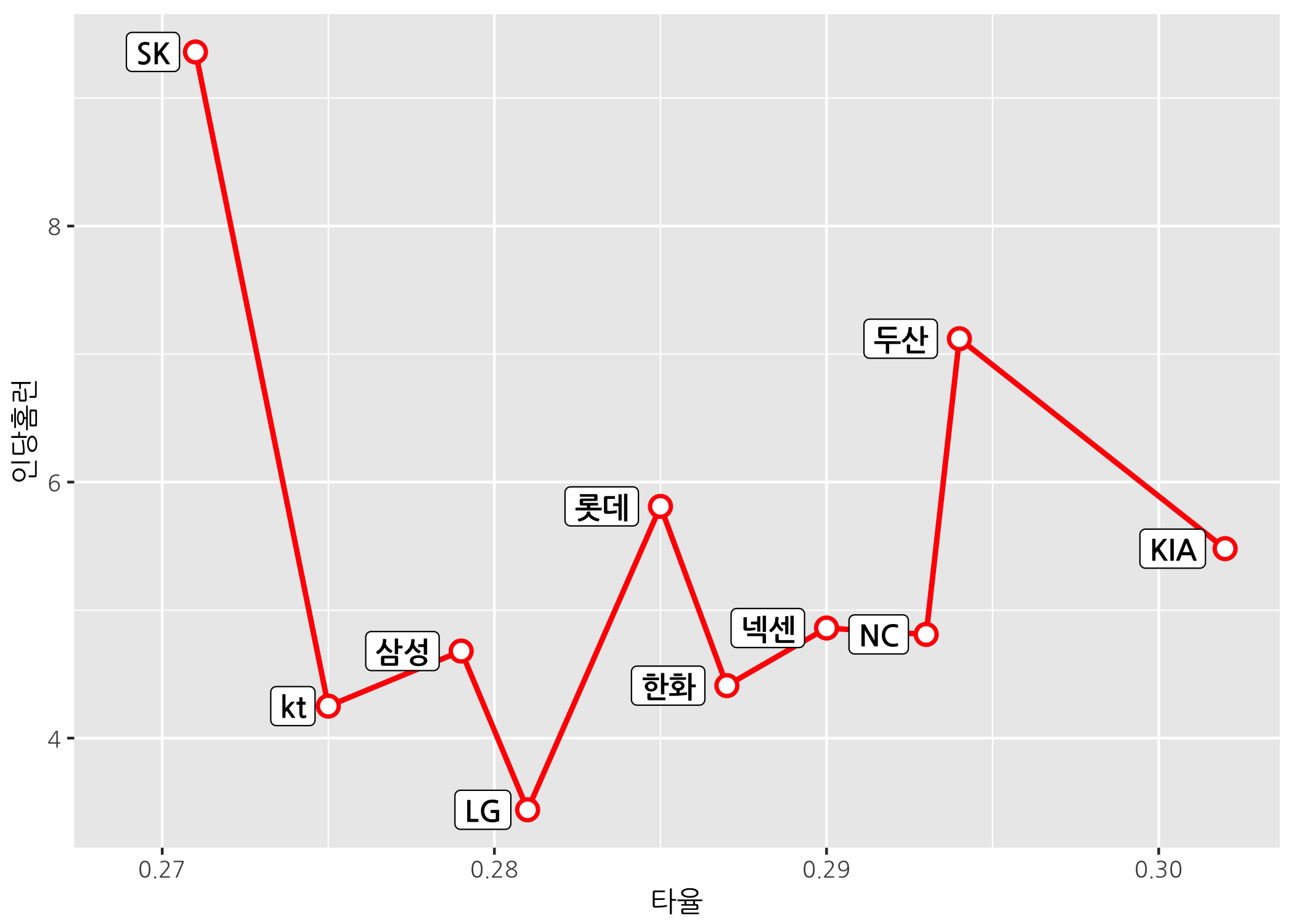
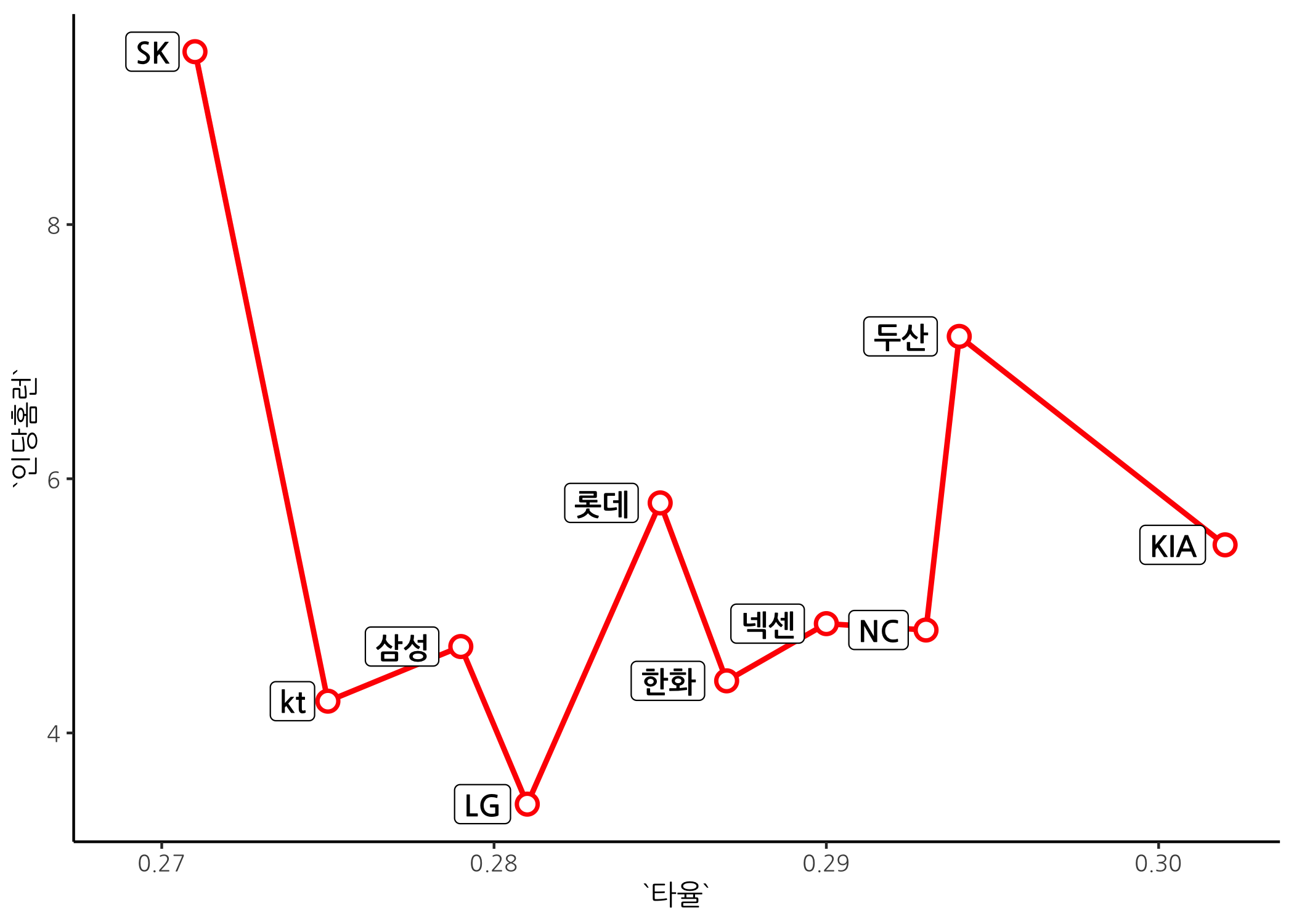
geom_label() 함수는 텍스트를 라벨처럼 꾸며주는 기능이 있습니다. 보기 좋네요. scale_x_continuous() 함수는 점 왼쪽에 텍스트나 라벨을 추가함에 따라 팀명이 잘리는 걸 방지해주기 위해 x축 범위를 조금 넓혀주기 위해 사용된 것입니다.
이제 선그래프를 마무래 해야죠. 마무리는 역시 테마를 적용하는 것입니다. theme_classic() 테마는 윗쪽과 오른쪽 테두리를 없앤 고전적인 그래프 양식이군요!!
# theme_classic() 테마를 추가합니다.
ggline +
geom_line(size = 1,
color = 'red') +
geom_point(shape = 21,
size = 3,
stroke = 1.2,
color = 'red',
fill = 'white') +
geom_label(mapping = aes(label = 팀명),
hjust = 1.3,
size = 4,
family = 'NanumGothic',
fontface = 'bold') +
scale_x_continuous(limits = c(0.269, 0.302)) +
theme_classic(base_family = 'NanumGothic')
추가사항
지금까지 ggplot2 패키지로 여러 가지 그래프를 그릴 때 필수적인 요소를 중심으로 소개해드렸는데요. 부가적인 요소를 3가지만 추가로 알려드릴까 합니다.
- 축 변환 :
coord_flip() - 축 분할 :
facet_grid() - 주석 달기 :
annotate()
그럼 하나씩 살펴보도록 하죠.
축 변환
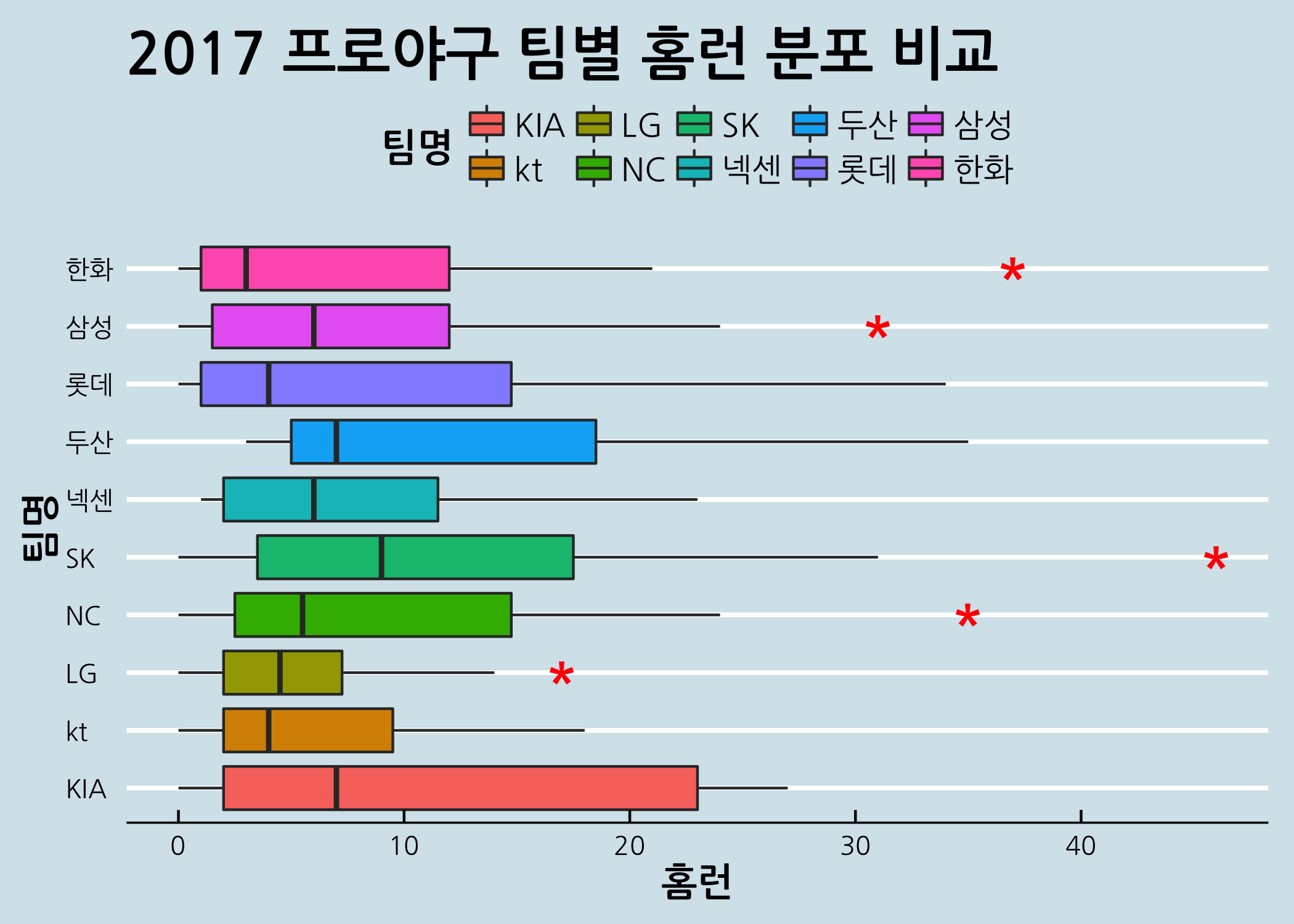
우리가 마지막으로 그린 상자수염그림에서 x-y축을 바꿔 그려보면 어떨까요? 아주 간단하게 기존 코드에다 coord_flip()만 추가해주면 됩니다. 아주 쉽죠?
# x-y축을 서로 바꿉니다.
ggbox +
geom_boxplot(mapping = aes(fill = 팀명),
outlier.shape = '*',
outlier.color = 'red',
outlier.size = 10) +
ggtitle(label = '2017 프로야구 팀별 홈런 분포 비교') +
labs(x = '팀명',
y = '홈런') +
theme_economist() +
theme(title = element_text(size = 15,
face = 'bold',
family = 'NanumGothic')) +
coord_flip()
축 분할
축 분할을 설명하기 위해 먼저 산점도를 하나 그려보겠습니다.
# 작년 한국시리즈 진출팀만 선택합니다.
finalists <- hitters50[hitters50$팀명 %in% c('KIA', '두산'), ]
# 양팀만으로 안타와 삼진을 두 축으로 하는 데이터를 지정합니다.
ggpnt <- ggplot(data = finalists,
mapping = aes(x = 안타,
y = 삼진))
# 산점도를 그리고 점 위에 선수명을 출력합니다.
ggpnt +
geom_point(mapping = aes(color = 팀명)) +
geom_text(mapping = aes(label = 선수명),
size = 3,
vjust = -1,
family = 'NanumGothic')
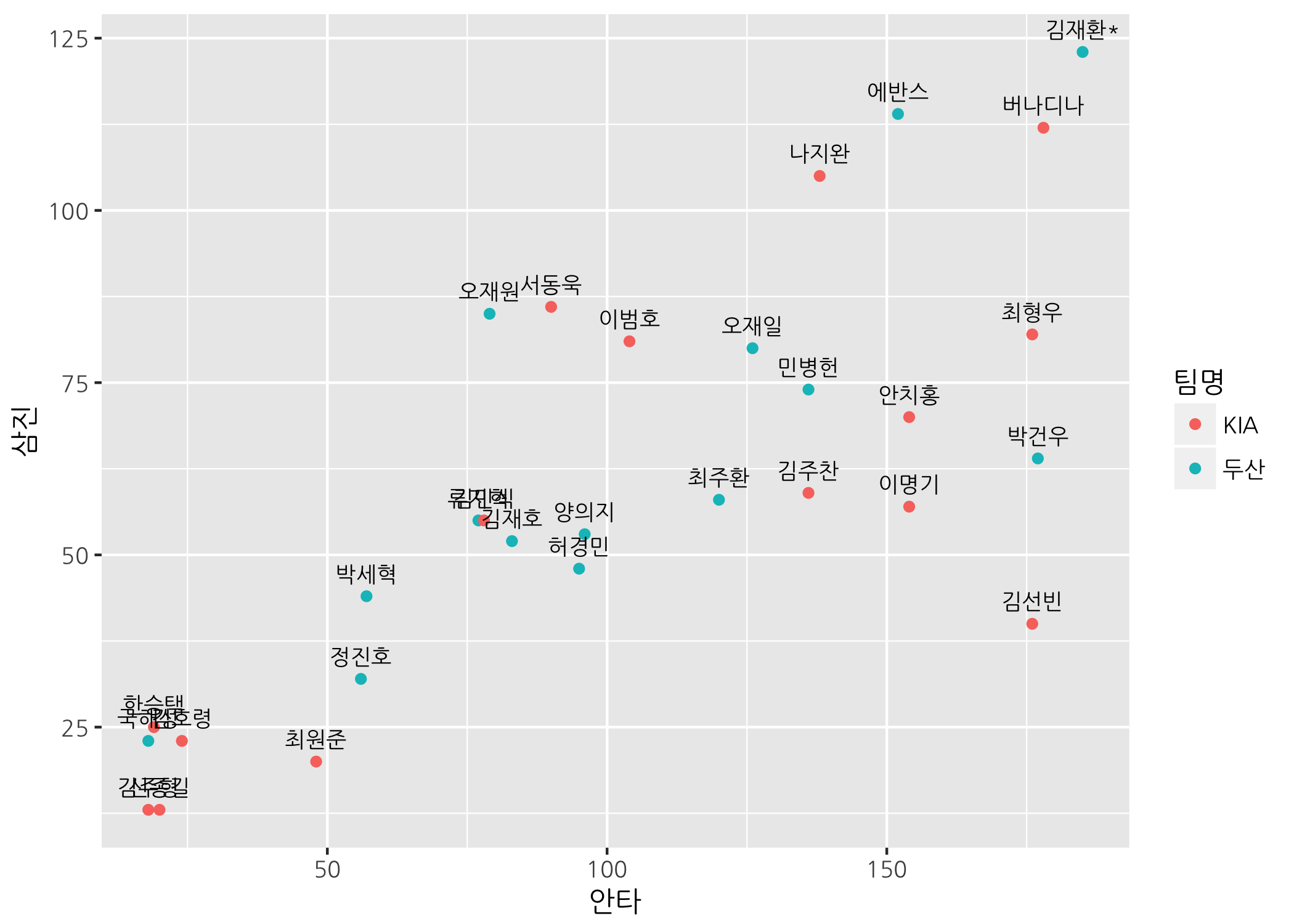
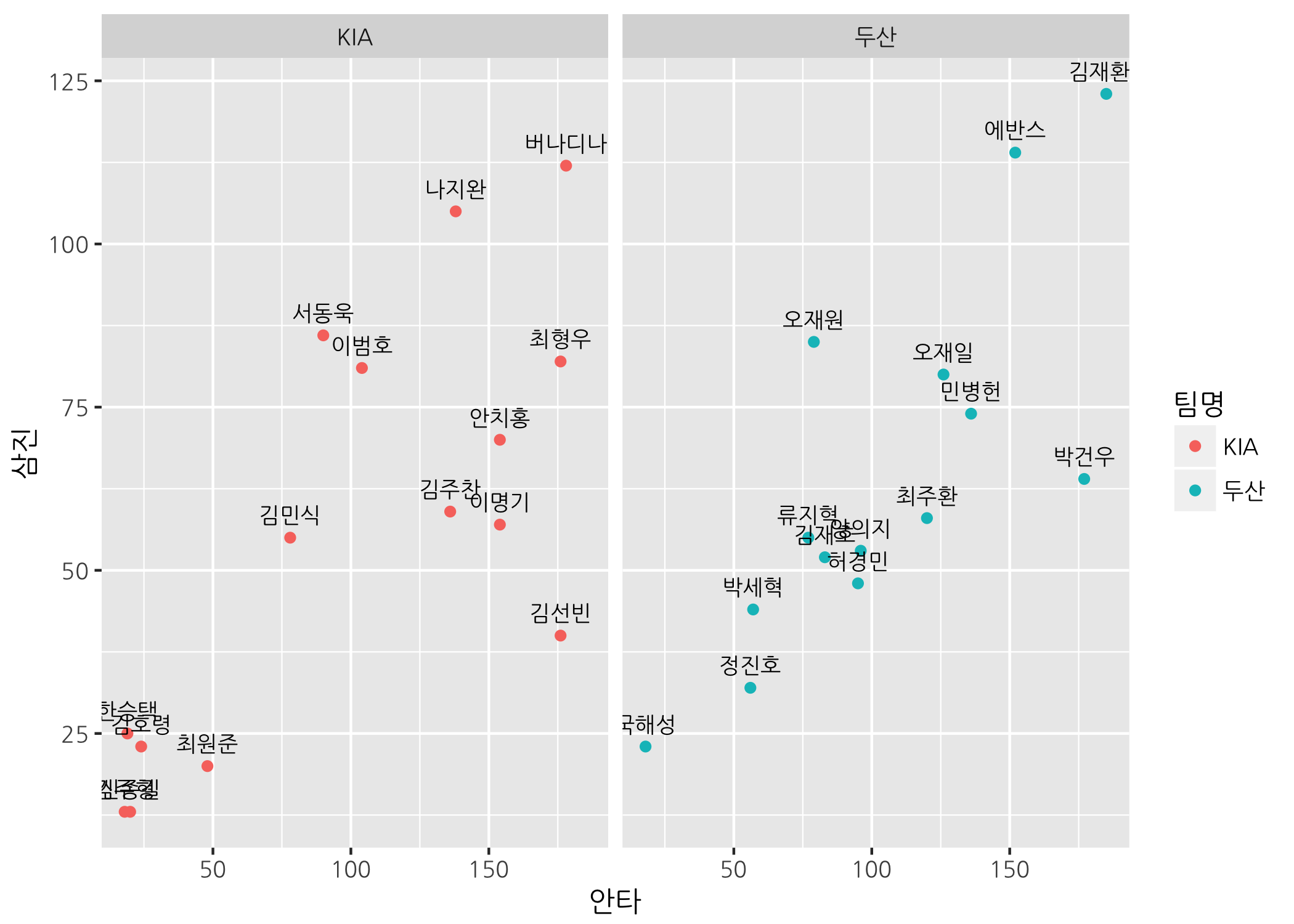
타수가 50 이상인 선수로 했음에도 불구하고 하나의 산점도에 출력하려니 상당히 복잡하고 겹치는 점들이 부분적으로 있어 알아보기 힘듭니다. 이럴 때 같은 그래프를 팀별로 나누어 그릴 수 있습니다. 축 분할은 x축 또는 y축으로 나눌 수 있습니다. 물론 x-y축 동시에 분할할 수도 있지만 이 포스팅에서는 다루지 않습니다.
# x축(열) 기준으로 축을 나눕니다.
ggpnt +
geom_point(mapping = aes(color = 팀명)) +
geom_text(mapping = aes(label = 선수명),
size = 3,
vjust = -1,
family = 'NanumGothic') +
facet_grid(facets = . ~ 팀명)
# y축(행) 기준으로 축을 나눕니다.
ggpnt +
geom_point(mapping = aes(color = 팀명)) +
geom_text(mapping = aes(label = 선수명),
size = 3,
vjust = -1,
family = 'NanumGothic') +
facet_grid(facets = 팀명 ~ .)
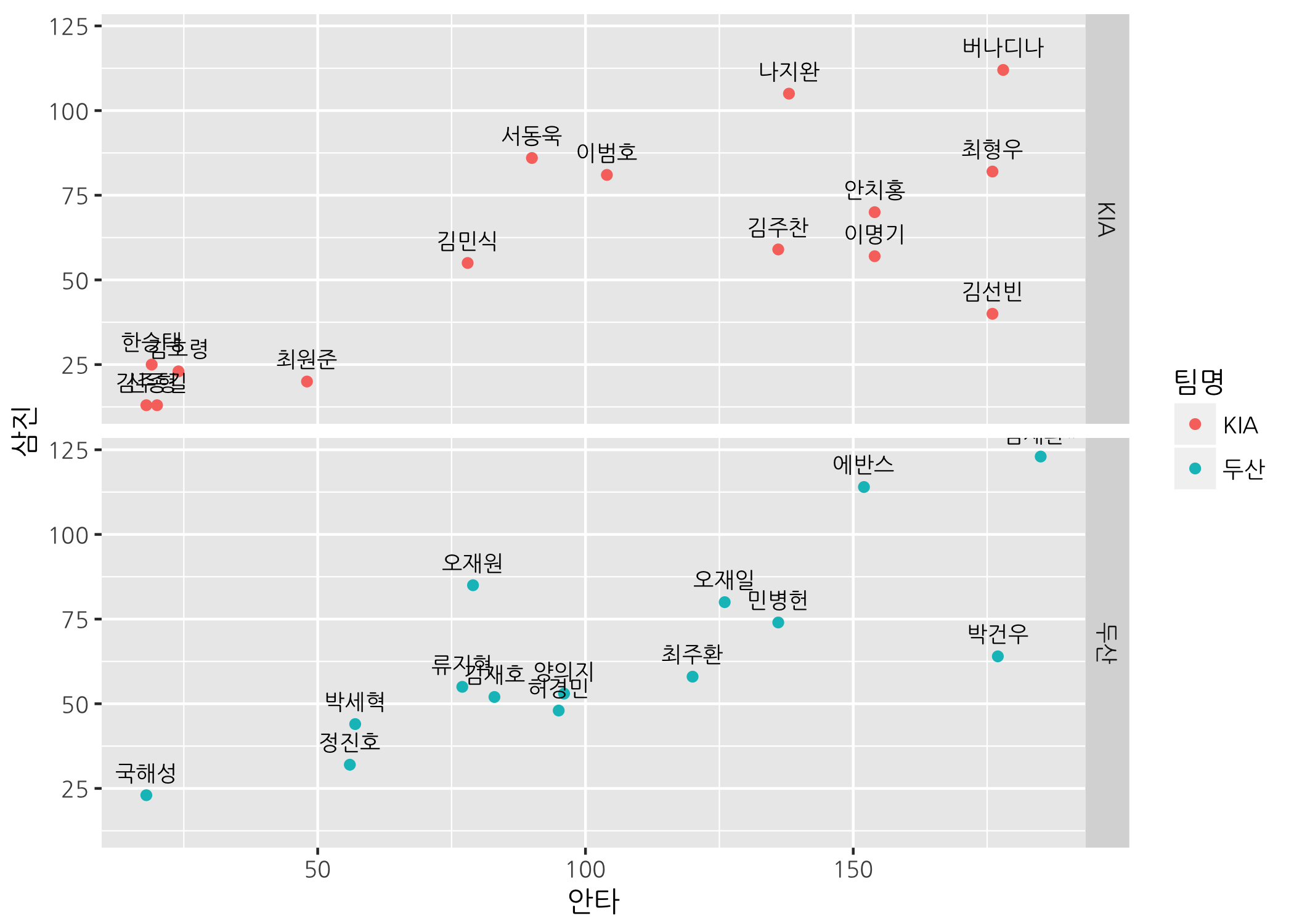
이것도 생각보다 어렵지 않죠? 주의해야 할 점은 축 분할을 할 때 기준이 되는 벡터가 가능한 범주형 또는 문자형이어야 한다는 것입니다. 사실 숫자형으로 지정해도 그래프를 그릴 수는 있지만, 아마 엄청 이상한 그래프를 마주하게 될 겁니다. 실험정신이 강한 분이라면 한 번 시도해보기 바랍니다.
주석 달기
annotate() 함수를 사용하면 데이터에 없는 텍스트를 추가할 수 있습니다. 말 그대로 그래프 안에 주석을 다는 것입니다. 조금 전에 그렸던 지난해 한국시리즈 진출팀 산점도에 수직선과 수평선을 추가하고 수직선과 수평선의 설명을 주석으로 달아보겠습니다.
# 산점도에 안타 평균 기준으로 수직선을, 삼진 평균 기준으로 수평선을 추가합니다.
# annotate() 함수로 수직선과 수평선을 설명하는 주석을 추가합니다.
ggpnt +
geom_point(mapping = aes(color = 팀명)) +
geom_text(mapping = aes(label = 선수명),
size = 3,
vjust = -1,
family = 'NanumGothic') +
geom_vline(xintercept = mean(finalists$안타),
color = 'red',
linetype = 2) +
geom_hline(yintercept = mean(finalists$삼진),
color = 'red',
linetype = 2) +
annotate(geom = 'text',
x = mean(finalists$안타),
y = max(finalists$삼진) * 0.95,
label = '안타 평균',
color = 'red',
size = 3,
fontface = 'bold',
family = 'NanumGothic',
hjust = 1.2) +
annotate(geom = 'text',
x = min(finalists$안타) * 1.05,
y = mean(finalists$삼진),
label = '삼진 평균',
color = 'red',
size = 3,
fontface = 'bold',
family = 'NanumGothic',
vjust = -1.2)
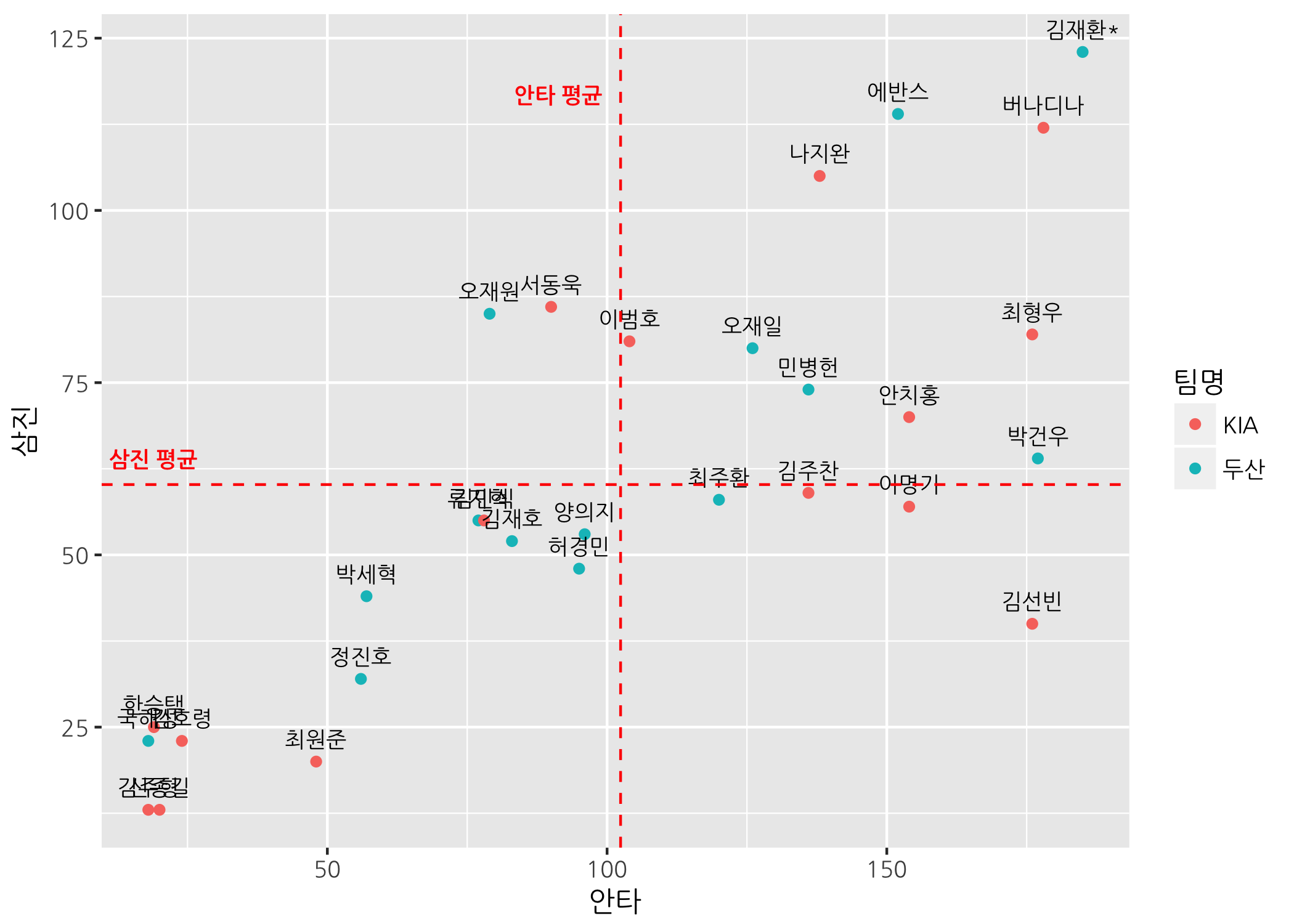
우리가 여기에서 ggplot2 패키지에 관하여 다룬 내용은 빙산의 일각입니다. 더 나은 그래프를 얼마든지 그릴 수 있으니 스스로 심화학습을 해보기 바랍니다.