
R 시각화 3 부록 1
서울 지하철 2호선 지도 시각화
Dr.Kevin 5/18/2018
지난 포스팅에서는 Google Map Api를 활용하여 주소 정보로 위경도 좌표를 받고, 해당 좌표를 중심으로 지도를 불러온 후 지도 위에 몇 가지 이미지를 추가하는 방법에 대해 살펴보았습니다. 그 결과로 정적인 지도 이미지를 생성하였습니다만, leaflet 패키지를 활용하여 동적인 지도 이미지(HTML)를 생성할 수 있습니다.
이번 포스팅은 R 시각화 3의 첫 번째 부록입니다. 서울 지하철 2호선의 승하차 데이터를 활용하여 지난 포스팅에서 배운 것을 복습하겠습니다.
정적 지도 이미지 만들기 (서울 지하철 2호선 시각화)
이번 포스팅에서 사용할 데이터를 먼저 준비해야 되겠죠? 티머니 대중교통 통계자료 웹페이지에서는 매월 교통카드 통계자료를 제공하고 있습니다. 웹페이지에 접속하여 왼쪽 아래를 살펴보면 대중교통 통계자료라는 항목이 있습니다. 이 항목을 클릭하면 월별 교통카드 통계자료를 엑셀 파일로 내려받을 수 있습니다. 가장 최근 자료인 2018년 04월 교통카드 통계자료.xlsx를 선택한 후 적당한 위치에 옮겨놓습니다. 그리고 해당 데이터를 불러옵니다.
# 필요 패키지를 불러옵니다.
library(readxl)
library(stringr)
# 2018년 04월 교통카드 통계자료를 불러옵니다.
# "지하철 노선별 역별 이용현황"은 두 번째 sheet에 저장되어 있습니다.
subway <- read_excel(path = './data/2018년 04월 교통카드 통계자료.xls', sheet = 2)
# 데이터의 구조를 확인합니다.
str(object = subway)
## Classes 'tbl_df', 'tbl' and 'data.frame': 590 obs. of 7 variables:
## $ 사용월 : chr "2018-04" "2018-04" "2018-04" "2018-04" ...
## $ 호선명 : chr "1호선" "1호선" "1호선" "1호선" ...
## $ 역ID : chr "0150" "0151" "0152" "0153" ...
## $ 지하철역 : chr "서울역" "시청" "종각" "종로3가" ...
## $ 승차승객수: chr "1,651,619" "741,509" "1,301,853" "1,028,466" ...
## $ 하차승객수: chr "1,610,635" "732,573" "1,230,820" "950,657" ...
## $ 작업일시 : chr "2018-05-03 13:29:05" "2018-05-03 13:29:05" "2018-05-03 13:29:05" "2018-05-03 13:29:05" ...
# 데이터를 미리보기 합니다.
head(x = subway, n = 10L)
## # A tibble: 10 x 7
## 사용월 호선명 역ID 지하철역 승차승객수 하차승객수 작업일시
## <chr> <chr> <chr> <chr> <chr> <chr> <chr>
## 1 2018-04 1호선 0150 서울역 1,651,619 1,610,635 2018-05-03 …
## 2 2018-04 1호선 0151 시청 741,509 732,573 2018-05-03 …
## 3 2018-04 1호선 0152 종각 1,301,853 1,230,820 2018-05-03 …
## 4 2018-04 1호선 0153 종로3가 1,028,466 950,657 2018-05-03 …
## 5 2018-04 1호선 0154 종로5가 803,826 800,890 2018-05-03 …
## 6 2018-04 1호선 0155 동대문 470,080 522,941 2018-05-03 …
## 7 2018-04 1호선 0156 신설동 496,660 486,292 2018-05-03 …
## 8 2018-04 1호선 0157 제기동 635,064 652,045 2018-05-03 …
## 9 2018-04 1호선 0158 청량리(서울시립대입구)… 818,519 845,491 2018-05-03 …
## 10 2018-04 1호선 0159 동묘앞 328,171 342,327 2018-05-03 …
subway 객체는 서울 지하철 590개 역에 대해 사용월, 호선명, 역ID, 지하철역, 승차승객수, 하차승객수, 작업일시 등 7개 컬럼으로 구성된 tbl_df, tbl, data.frame인 것을 확인할 수 있습니다. 승차승객수와 하차승객수는 숫자 벡터이어야 하는데 문자 벡터로 되어 있습니다. 왜 그럴까요? 그건 숫자 사이에 콤마(,)가 있기 때문입니다. 이 컬럼들로 사칙연산을 하려면 미리 숫자 벡터로 변환해두어야 합니다.
# 승하차 승객수 컬럼들을 숫자 벡터로로 변환합니다.
# [주의!] 숫자 사이의 콤마(,)를 먼저 제거해야 숫자로 변환할 수 있습니다.
subway[ , c('승차승객수', '하차승객수')] <-
subway[ , c('승차승객수', '하차승객수')] %>%
sapply(FUN = str_remove_all, pattern = ',') %>%
as.numeric()
미리보기에서 지하철역을 보면 9번째 행에 ‘청량리(서울시립대입구)’로 되어 있는 걸 확인할 수 있습니다. 나중에 지도에 지하철역명을 출력해줘야 하는데 일부 역명이 아주 길게 되어 있는 것 같습니다. 지하철역 글자 길이를 확인하고 적절한 조치를 취해야 할 것 같습니다.
# 지하철역의 글자 길이를 확인합니다.
nchar(x = subway$지하철역) %>% table()
## .
## 2 3 4 5 6 7 8 9 10 11 12 13 14 16
## 313 112 48 28 9 10 24 12 14 13 3 2 1 1
대부분이 2~3글자로 되어 있는데 최대 16글자로 되어 있는 지하철역도 있군요. 지하철역의 길이가 6 이상인 항목들을 확인해보겠습니다.
# 지하철역의 글자 길이가 6 이상인 항목을 출력합니다.
subway$지하철역[nchar(x = subway$지하철역) >= 6]
## [1] "청량리(서울시립대입구)" "동대문역사문화공원"
## [3] "왕십리(성동구청)" "구의(광진구청)"
## [5] "강변(동서울터미널)" "잠실(송파구청)"
## [7] "삼성(무역센터)" "교대(법원.검찰청)"
## [9] "서울대입구(관악구청)" "구로디지털단지"
## [11] "대림(구로구청)" "충정로(경기대입구)"
## [13] "용두(동대문구청)" "경복궁(정부서울청사)"
## [15] "교대(법원.검찰청)" "남부터미널(예술의전당)"
## [17] "양재(서초구청)" "수유(강북구청)"
## [19] "미아(서울사이버대학)" "성신여대입구(돈암)"
## [21] "한성대입구(삼선교)" "동대문역사문화공원"
## [23] "회현(남대문시장)" "숙대입구(갈월)"
## [25] "이촌(국립중앙박물관)" "동작(현충원)"
## [27] "총신대입구(이수)" "가산디지털단지"
## [29] "온수(성공회대입구)" "이촌(국립중앙박물관)"
## [31] "왕십리(성동구청)" "청량리(서울시립대입구)"
## [33] "정부과천청사" "압구정로데오"
## [35] "상봉(시외버스터미널)" "쌍용(나사렛대)"
## [37] "신창(순천향대)" "디지털미디어시티"
## [39] "디지털미디어시티" "남동인더스파크"
## [41] "신정(은행정)" "오목교(목동운동장앞)"
## [43] "충정로(경기대입구)" "광화문(세종문화회관)"
## [45] "동대문역사문화공원" "왕십리(성동구청)"
## [47] "군자(능동)" "아차산(어린이대공원후문)"
## [49] "광나루(장신대)" "천호(풍납토성)"
## [51] "굽은다리(강동구민회관앞)" "올림픽공원(한국체대)"
## [53] "새절(신사)" "증산(명지대앞)"
## [55] "디지털미디어시티" "월드컵경기장(성산)"
## [57] "광흥창(서강)" "대흥(서강대앞)"
## [59] "녹사평(용산구청)" "안암(고대병원앞)"
## [61] "고려대(종암)" "월곡(동덕여대)"
## [63] "상월곡(한국과학기술연구원)" "화랑대(서울여대입구)"
## [65] "봉화산(서울의료원)" "공릉(서울과학기술대)"
## [67] "상봉(시외버스터미널)" "군자(능동)"
## [69] "어린이대공원(세종대)" "숭실대입구(살피재)"
## [71] "신대방삼거리" "대림(구로구청)"
## [73] "가산디지털단지" "온수(성공회대입구)"
## [75] "부천종합운동장" "천호(풍납토성)"
## [77] "몽촌토성(평화의문)" "잠실(송파구청)"
## [79] "남한산성입구(성남법원.검찰청)" "흑석(중앙대입구)"
## [81] "동작(현충원)" "디지털미디어시티"
## [83] "청라국제도시" "공항화물청사"
## [85] "인천공항1터미널" "인천공항2터미널"
## [87] "4.19민주묘지" "북한산보국문"
## [89] "성신여대입구(돈암)"
원래 이름이 긴 지하철역도 있지만 대부분이 괄호로 추가 지명이 붙어 있음을 알 수 있습니다. 괄호 부분을 모두 삭제하면 길이를 크게 줄일 수 있을 것 같습니다. 아울러 지하철역이 ‘역’으로 끝나지 않은 경우 ‘역’을 붙이겠습니다. ‘역’을 붙이는 이유는 지명으로 위경도 좌표를 불러올 경우, 엉뚱한 곳의 좌표를 가져울 수 있기 때문입니다.
# 지하철역 컬럼 데이터를 정리합니다.
# str_remove() 함수를 이용하여 괄호 부분을 없앱니다.
# 맨 뒤에 '역'으로 끝나지 않으면 '역'을 붙입니다.
subway$지하철역s <-
subway$지하철역 %>%
str_remove(pattern = '\\(.+\\)') %>%
str_remove(pattern = '역$') %>%
str_c('역')
# 미리보기 합니다.
head(x = subway, n = 10L)
## # A tibble: 10 x 8
## 사용월 호선명 역ID 지하철역 승차승객수 하차승객수 작업일시 지하철역s
## <chr> <chr> <chr> <chr> <dbl> <dbl> <chr> <chr>
## 1 2018-04 1호선 0150 서울역 1651619. 1610635. 2018-05… 서울역
## 2 2018-04 1호선 0151 시청 741509. 732573. 2018-05… 시청역
## 3 2018-04 1호선 0152 종각 1301853. 1230820. 2018-05… 종각역
## 4 2018-04 1호선 0153 종로3가 1028466. 950657. 2018-05… 종로3가역
## 5 2018-04 1호선 0154 종로5가 803826. 800890. 2018-05… 종로5가역
## 6 2018-04 1호선 0155 동대문 470080. 522941. 2018-05… 동대문역
## 7 2018-04 1호선 0156 신설동 496660. 486292. 2018-05… 신설동역
## 8 2018-04 1호선 0157 제기동 635064. 652045. 2018-05… 제기동역
## 9 2018-04 1호선 0158 청량리(서울시립… 818519. 845491. 2018-05… 청량리역
## 10 2018-04 1호선 0159 동묘앞 328171. 342327. 2018-05… 동묘앞역
새로 만든 지하철역s 컬럼이 잘 저장되어 있습니다. 이 컬럼의 데이터로 위경도 좌표를 수집하도록 하겠습니다. ggmap 패키지를 불러오고 Google Map Api 인증키를 등록하는 것부터 해야 되겠죠?
# 필요 패키지를 불러옵니다.
library(ggmap)
# 구글 지도 API 인증키를 등록합니다.
register_google(key = '자신의 구글 지도 API 인증키를 입력하세요')
인증키가 제대로 등록되었으면 Google Map API 일별 한도를 확인해보죠.
# Google Map API 일별 한도를 확인합니다.
geocodeQueryCheck()
## 2500 geocoding queries remaining.
2,500번 남아 있습니다. 이제 위경도 좌표를 수집합니다. 여기서 잠깐! geocode() 및 mutate_geocode() 함수는 location 인자에 UTF-8 인코딩 방식의 텍스트를 지정해야 제대로 작동합니다. 따라서 Window 사용자는 개별 텍스트를 입력할 때에는 enc2utf8() 함수를 이용하든가 아니면 iconv() 함수를 이용하여 인코딩 방식을 UTF-8로 변경해주어야 합니다.
# 지하철역s 컬럼의 인코딩 방식을 확인합니다.
Encoding(x = subway$지하철역s) %>% unique()
## [1] "UTF-8"
# 서울 지하철 2호선만 따로 추출합니다.
subwayNo2 <- subway[subway$호선명 == '2호선', ]
서울 지하철 2호선에 해당하는 역만 추출하니 총 50건으로 줄어들었습니다. 이 데이터로 위경도 좌표를 얻도록 하겠습니다.
# 지하철역으로 위경도 좌표 얻기
subwayNo2 <- mutate_geocode(data = subwayNo2,
location = 지하철역s,
source = 'google')
이제 지도 위에 출력할 준비가 완료되었습니다. 나중에 따로 사용하기 위해 RDS 파일로 저장합니다.
# RDS 파일로 저장합니다.
saveRDS(object = subwayNo2, file = './data/Seoul_Subway_Line_No2.RDS')
지금까지 만든 subwayNo2 데이터를 이용하여 roadmap 지도 위에 서울 지하철 2호선(순환) 지하철역을 표시하고 다각형을 지정한 후 테두리만 어두운 녹색으로 출력해보겠습니다.
# 서울 지하철 2호선 중 지선은 제외합니다. (용답~신설동, 도림천~까치산)
df <- subwayNo2[1:43, ]
# 중심 계산
center <- c(median(x = df$lon), median(x = df$lat))
# 지도 위에 지하철 2호선 역을 표시합니다.
qmap(location = center,
zoom = 12,
maptype = 'roadmap',
source = 'google',
color = 'color') +
geom_polygon(data = df,
mapping = aes(x = lon,
y = lat,
group = 호선명),
color = 'darkgreen',
fill = 'white',
size = 2,
alpha = 0) +
geom_point(data = df,
mapping = aes(x = lon,
y = lat),
pch = 21,
fill = 'darkgreen',
color = 'black',
size = 4,
stroke = 2) +
geom_label(data = df,
mapping = aes(x = lon,
y = lat,
label = 지하철역s),
family = 'NanumGothic',
fontface = 'bold',
size = 3,
alpha = 0.5,
nudge_y = 0.004)
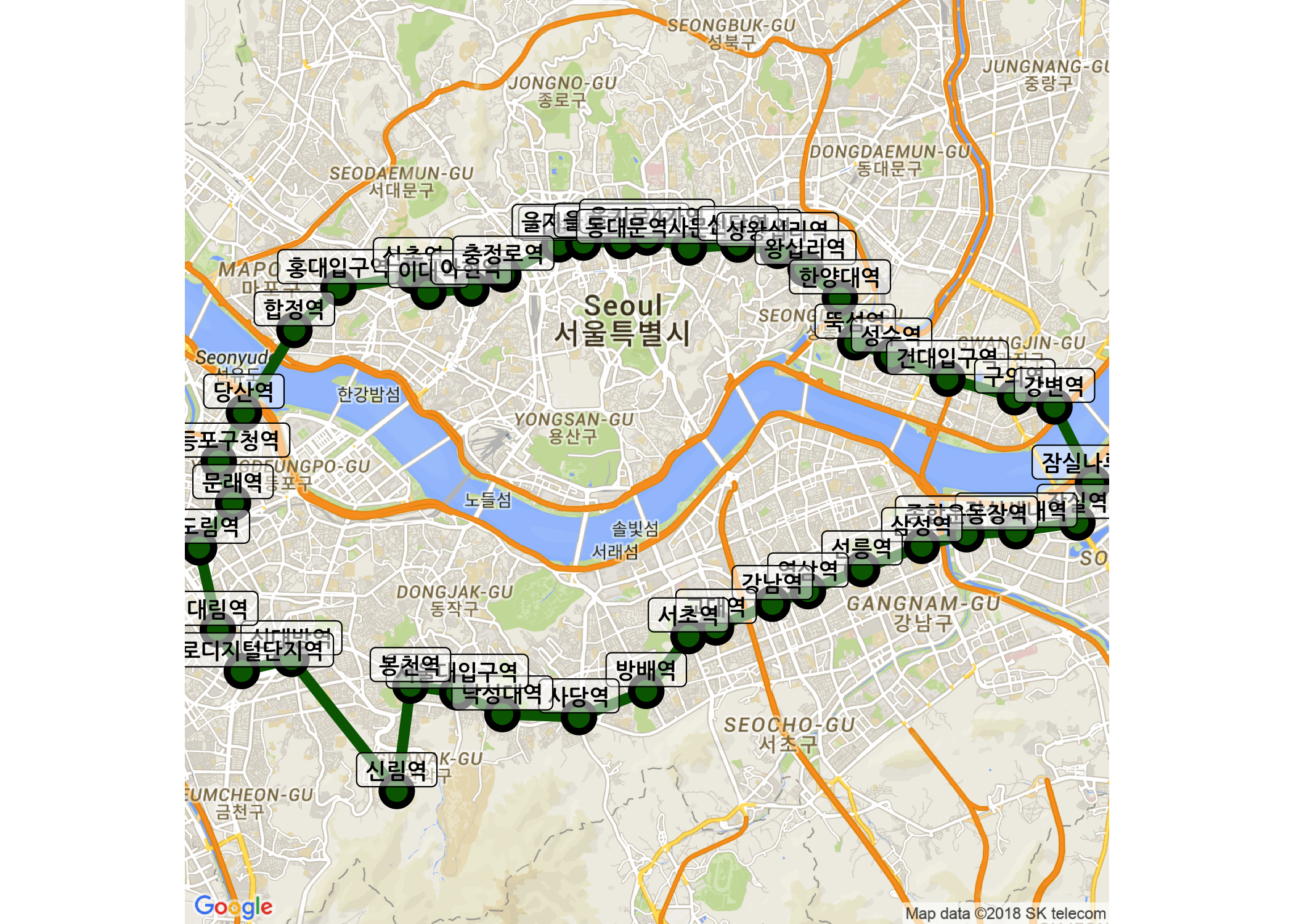
뭔가 좀 이상하죠? 신림역이 엉뚱한 곳에 출력되었습니다. 이런 경우, 번거롭더라도 해당 지명의 주소지를 검색하여 수정해주어야 합니다. 신림역의 주소는 ‘서울특별시 관악구 남부순환로 1614’입니다. 이 주소로 다시 위경도 좌표를 구하고, 기존 좌표와 교체하겠습니다.
# 신림역 위경도 좌표를 다시 얻습니다.
newCoords <- geocode(location = enc2utf8('서울특별시 관악구 남부순환로 1614'),
output = 'latlona',
source = 'google')
# 신림역 위경도 좌표를 변경합니다.
subwayNo2[subwayNo2$지하철역s == '신림역', c('lon', 'lat')] <- newCoords[, c('lon', 'lat')]
# 데이터가 변경되었으니 RDS 파일을 다시 저장합니다.
saveRDS(object = subwayNo2, file = './data/Seoul_Subway_Line_No2.RDS')
지도 위에 서울 지하철 2호선 시각화 작업을 다시 해보겠습니다.
# 서울 지하철 2호선 중 지선은 제외합니다. (용답~신설동, 도림천~까치산)
df <- subwayNo2[1:43, ]
# 중심을 중위값으로 지정합니다.
center <- c(median(x = df$lon), median(x = df$lat))
# 지도 위에 지하철 2호선 역을 표시합니다.
qmap(location = center,
zoom = 12,
maptype = 'roadmap',
source = 'google',
color = 'color') +
geom_polygon(data = df,
mapping = aes(x = lon,
y = lat,
group = 호선명),
color = 'darkgreen',
fill = 'white',
size = 2,
alpha = 0) +
geom_point(data = df,
mapping = aes(x = lon,
y = lat),
pch = 21,
fill = 'darkgreen',
color = 'black',
size = 4,
stroke = 2) +
geom_label(data = df,
mapping = aes(x = lon,
y = lat,
label = 지하철역s),
family = 'NanumGothic',
fontface = 'bold',
size = 3,
alpha = 0.5,
nudge_y = 0.004)
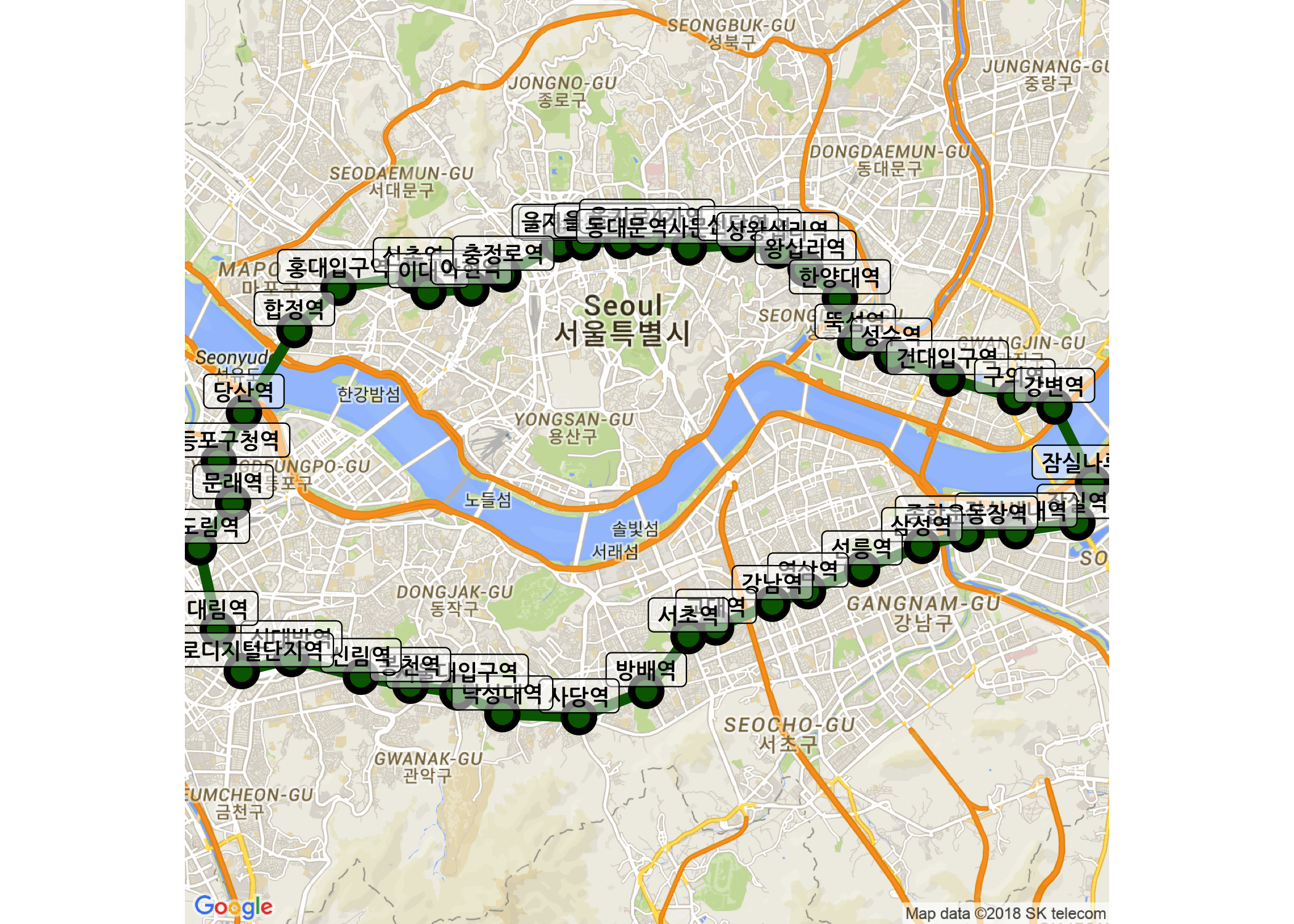
이제 제대로 출력되었습니다. 여기까지는 지난 포스팅에서 했던 복습이라고 할 수 있습니다. 두 번째 부록에서는 leaflet 패키지를 활용한 동적인 지도 이미지 생성을 다루어보도록 하겠습니다.