
R 시각화 4
ggplot2 패키지를 활용한 지도 시각화
Dr.Kevin 5/25/2018
이전 포스팅에서는 ggmap 패키지를 활용한 지도 시각화에 대해서 알아보았는데요. 제 생각이지만 실제 지도 이미지 위에 시각화를 하는 것만으로는 생각보다 할 일이 많지 않는 것 같습니다. 업무에 활용해야 한다면 더더욱 그럴 것 같네요. 그래서 이번 포스팅에서는 ggplot2 패키지를 활용하여 지도 경계 데이터를 수집하고, 지역별로 다각형을 만들어 채우기 색상을 지정하는 등의 지도 시각화에 대해서 알아보도록 하겠습니다.
ggplot2 패키지를 활용한 지도 시각화
본격적인 지도 시각화에 앞서 가볍게 몸풀기를 하도록 하겠습니다. ggplot2 패키지의 map_data() 함수를 이용하면 간단하게나마 원하는 지역의 지도 경계 데이터를 가져올 수 있습니다. 그렇다면 map_data() 함수의 주요 인자를 알아봐야 하겠죠?
- map : maps 패키지에서 제공되는 지도 이름을 지정합니다. ‘county’, ‘france’, ‘italy’, ‘nz’, ‘state’, ‘usa’, ‘world’, ‘world2’ 중에서 하나를 지정하면 됩니다. 우리는 ‘world’ 지도를 이용할 예정입니다.
- region : 국가명을 지정합니다. 예를 들어 ‘South Korea’, ‘North Korea’ 등으로 지정하면 됩니다. 기본값은
.이고 전체 국가명을 의미합니다.
map_data() 함수를 실행하면 6개의 컬럼을 갖는 데이터프레임이 생성됩니다. 각 컬럼은 다음과 같습니다.
- long : 경도(longitude)를 의미합니다. 경도는 x축 좌표입니다.
- lat : 위도(latitude)를 의미합니다. 위도는 y축 좌표입니다.
- group : 한 권역은 같은 값을 갖습니다. 이 값을 기준으로 polygon(다각형)을 만들 수 있습니다.
- order : 좌표의 순번 개념으로 생각하면 됩니다. 순번으로 정렬되어 있어야 제대로 된 다각형을 만들 수 있습니다! (중요)
- region :
map_data()함수의region인자에 지정한 값입니다. - subregion : ‘region’의 하위 세부 지역을 의미하는 데
NA인 값도 상당히 많습니다.
이 정도로 map_data() 함수에 대한 설명을 마무리 짓고 실습으로 넘어가도록 하겠습니다.
# 필요 패키지를 불러옵니다.
library(ggplot2)
# 세계 지도를 불러옵니다.
world <- map_data(map = 'world', region = '.')
# 세계 지도에 포함된 국가명만 오름차순으로 정렬 후 출력합니다.
world$region %>% unique() %>% sort()
위 코드를 직접 실행하면 모두 252개의 국가명이 출력될 것입니다. 이 중에서 동북아시아 국가명만 골라서 주변 지도를 만들어 보겠습니다.
# 동북아시아 지도 데이터를 만듭니다.
neAsia <- map_data(map = 'world',
region = c('South Korea', 'North Korea', 'China',
'Japan', 'Mongolia', 'Taiwan'))
# 지도 데이터 미리보기 합니다.
head(x = neAsia, n = 10L)
## long lat group order region subregion
## 1 110.8888 19.99194 1 1 China 1
## 2 110.9383 19.94756 1 2 China 1
## 3 110.9707 19.88330 1 3 China 1
## 4 110.9977 19.76470 1 4 China 1
## 5 111.0137 19.65547 1 5 China 1
## 6 110.9127 19.58608 1 6 China 1
## 7 110.8223 19.55791 1 7 China 1
## 8 110.6409 19.29121 1 8 China 1
## 9 110.6031 19.20703 1 9 China 1
## 10 110.5722 19.17188 1 10 China 1
ggplot() 함수를 이용하여 지도를 그려보겠습니다.
# x축에 경도, y축에 위도를 지정하여 지도를 그릴 수 있습니다.
# geom_polygon() 함수를 이용하여 국가별로 다각형을 만들 수 있고,
# 다각형별로 채우기 및 테두리 색을 변경할 수 있습니다.
neAsiaMap <-
ggplot(data = neAsia,
mapping = aes(x = long,
y = lat,
group = group)) +
geom_polygon(fill = 'white',
color = 'black')
# 지도를 그립니다.
neAsiaMap
지도를 그렸는데 왠지 비율이 맞지 않는 것 같고 어색합니다. 이런 문제를 해결하려면 아래와 같이 좌표계를 적용해주어야 합니다.
# 좌표계를 적용하면 좀 더 지도처럼 출력할 수 있습니다.
# 아래 옵션 중에서 하나를 선택할 수 있습니다.
# 'mercator'(기본값), 'polyconic', 'cylindrical', 'azequalarea'
neAsiaMap + coord_map()
이제 한결 나아졌습니다. 국가별로 채우기 색을 적용해보도록 하죠. 대한민국은 파란색, 북한은 빨간색으로 채우는 것입니다.
# 한반도에만 채우기와 테두리 색을 지정합니다.
# 대한민국은 파란색, 북한은 빨간색으로 채우기 합니다.
southKorea <- map_data(map = 'world', region = 'South Korea')
northKorea <- map_data(map = 'world', region = 'North Korea')
# 기존 지도 이미지에 한반도 국가들을 추가로 덧붙입니다.
neAsiaMap +
coord_map() +
geom_polygon(data = southKorea,
mapping = aes(x = long,
y = lat,
group = group),
fill = 'blue',
color = 'blue') +
geom_polygon(data = northKorea,
mapping = aes(x = long,
y = lat,
group = group),
fill = 'red',
color = 'red')
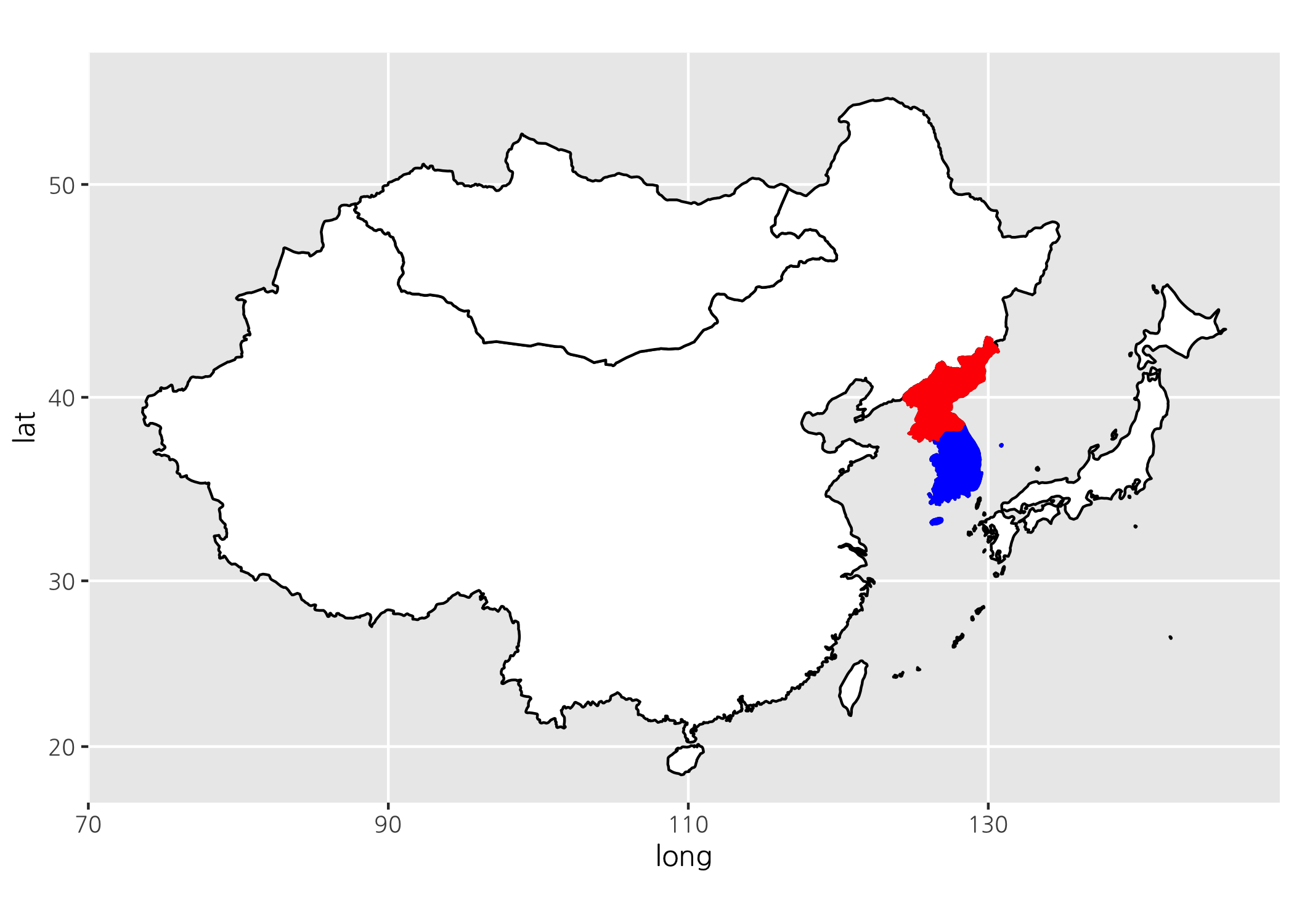
그런데 최근 남북정상회담이 있었고, 평화의 무드가 조성되고 있는 이 즈음에 맞게 통일한국을 표현해보는 것도 의미가 있을 것 같습니다. 한반도를 ‘하늘색’으로 채워보도록 하겠습니다.
# 한반도를 하늘색으로 채웁니다.
neAsiaMap +
coord_map() +
geom_polygon(data = southKorea,
mapping = aes(x = long,
y = lat,
group = group),
fill = 'skyblue',
color = 'skyblue') +
geom_polygon(data = northKorea,
mapping = aes(x = long,
y = lat,
group = group),
fill = 'skyblue',
color = 'skyblue')
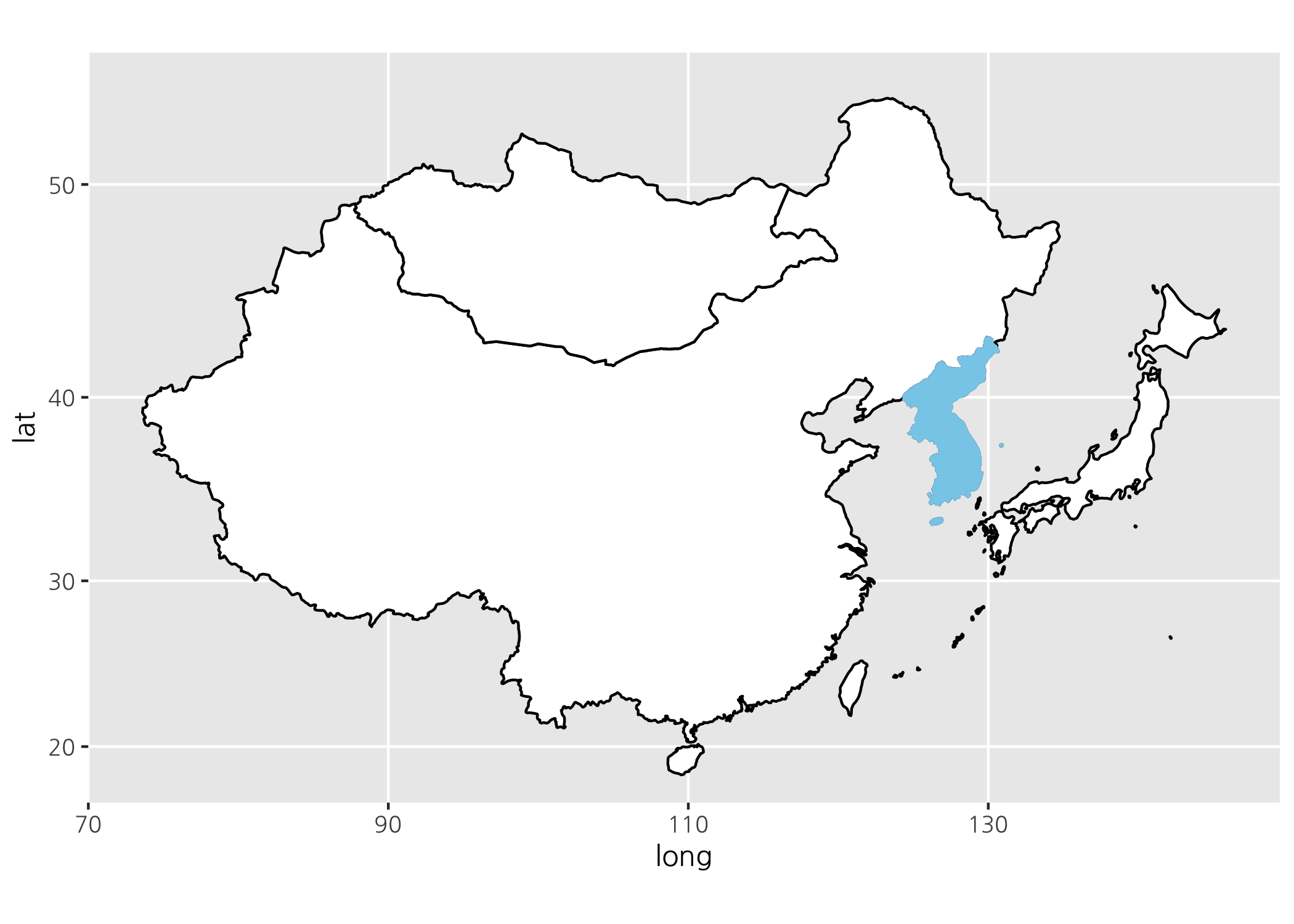
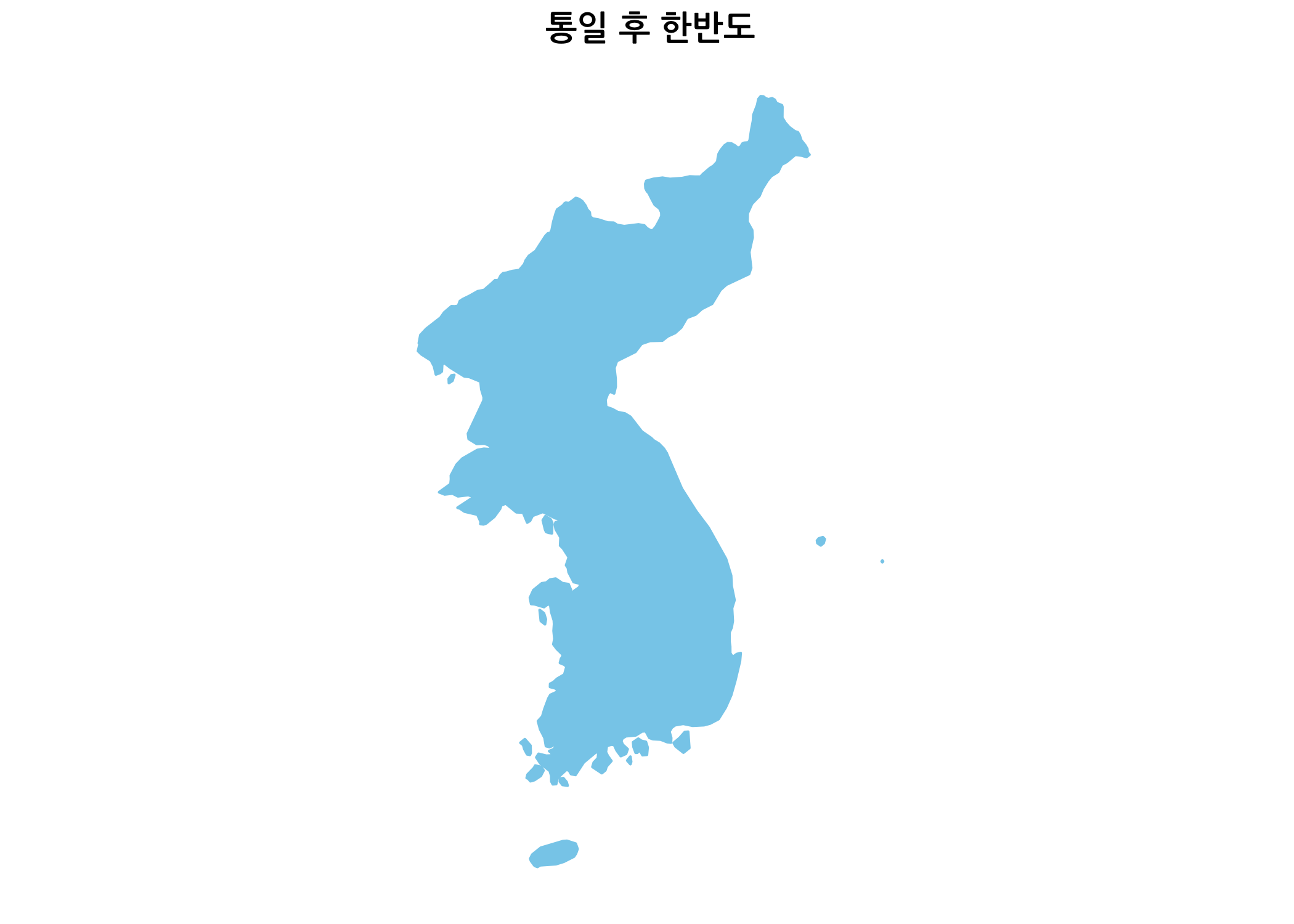
통일한국의 모습이 보기에 아주 좋습니다. 흐뭇하네요. 기왕에 하는 김에 한반도만 추려서 큰 이미지로 그려보도록 하죠. (임의로 정한 것이지만) 통일 전 한반도 / 통일 후 한반도라는 타이틀을 넣은 두 개의 지도 이미지를 병렬로 나란히 그리는 것입니다.
# 대한민국과 북한 지도 경계 데이터만 수집합니다.
twoKoreas <- map_data(map = 'world',
region = c('South Korea', 'North Korea'))
# 지도를 깔끔하게 정리하기 위해 나만의 테마를 만듭니다.
my_theme <- theme(panel.background = element_blank(),
axis.title = element_blank(),
axis.text = element_blank(),
axis.ticks = element_blank(),
plot.title = element_text(hjust = 0.5,
face = 'bold'))
먼저 통일 전 한반도 / 통일 후 한반도 이미지를 각각 그려보겠습니다.
# 통일 전 한반도 지도 이미지를 생성합니다.
before <-
ggplot(data = twoKoreas,
mapping = aes(x = long,
y = lat,
group = group)) +
coord_map() +
geom_polygon(data = southKorea,
aes(x = long,
y = lat,
group = group),
fill = 'blue',
color = 'blue') +
geom_polygon(data = northKorea,
aes(x = long,
y = lat,
group = group),
fill = 'red',
color = 'red') +
ggtitle(label = '통일 전 한반도') +
my_theme
# 통일 전 한반도 지도 이미지를 그립니다.
before
# 통일 후 한반도 지도 이미지를 생성합니다.
after <-
ggplot(data = twoKoreas,
mapping = aes(x = long,
y = lat,
group = group)) +
coord_map() +
geom_polygon(data = southKorea,
aes(x = long,
y = lat,
group = group),
fill = 'skyblue',
color = 'skyblue') +
geom_polygon(data = northKorea,
aes(x = long,
y = lat,
group = group),
fill = 'skyblue',
color = 'skyblue') +
ggtitle(label = '통일 후 한반도') +
my_theme
# 통일 후 한반도 지도 이미지를 그립니다.
after
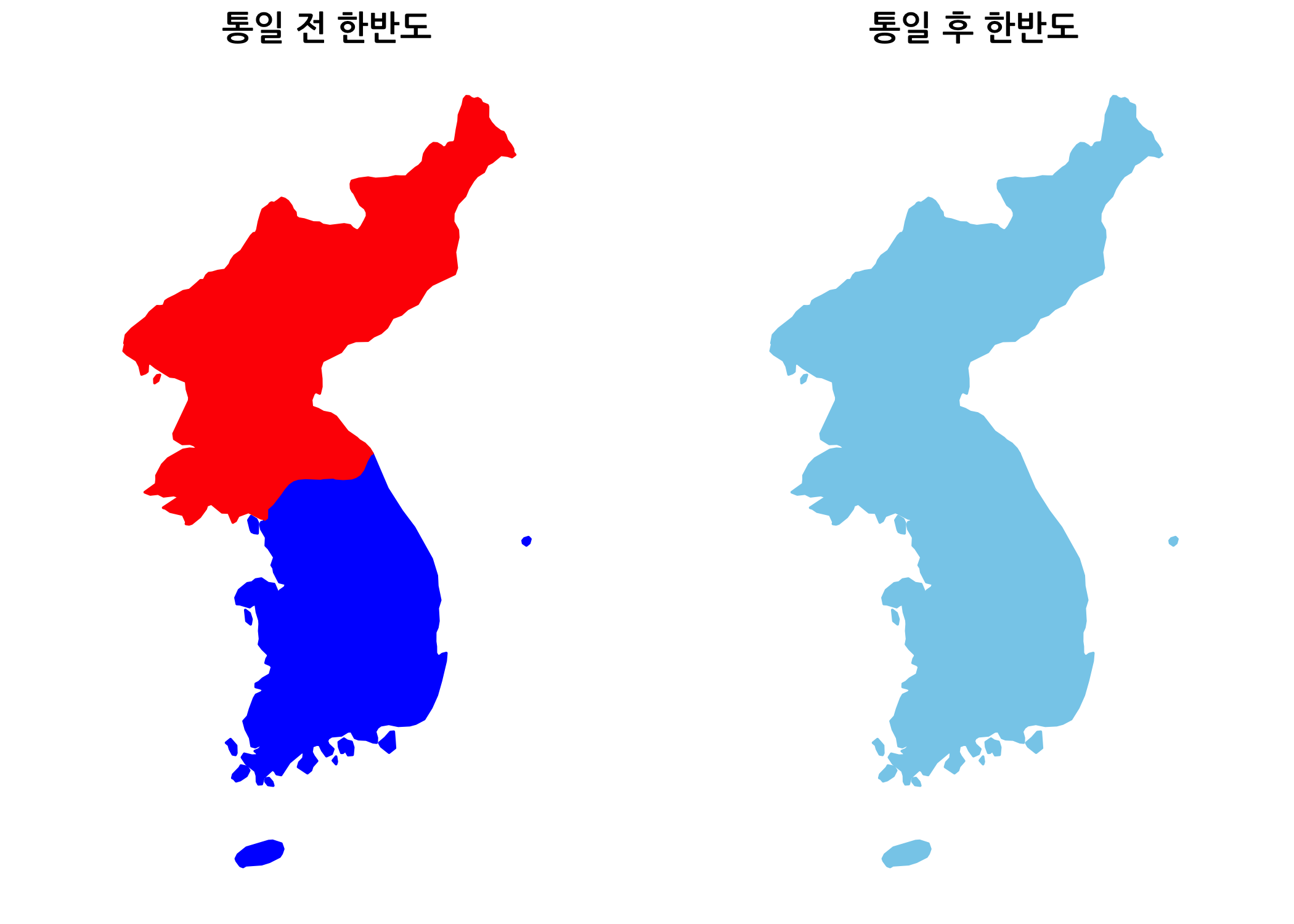
두 개의 지도 이미지를 옆으로 나란히 그려보겠습니다. gridExtra 패키지의 grid.arrange() 함수를 이용하면 간단하게 해결될 수 있습니다.
# 필요 패키지를 불러옵니다.
library(gridExtra)
# 두 개의 이미지를 옆으로 나란히 그립니다.
grid.arrange(before, after, ncol = 2)
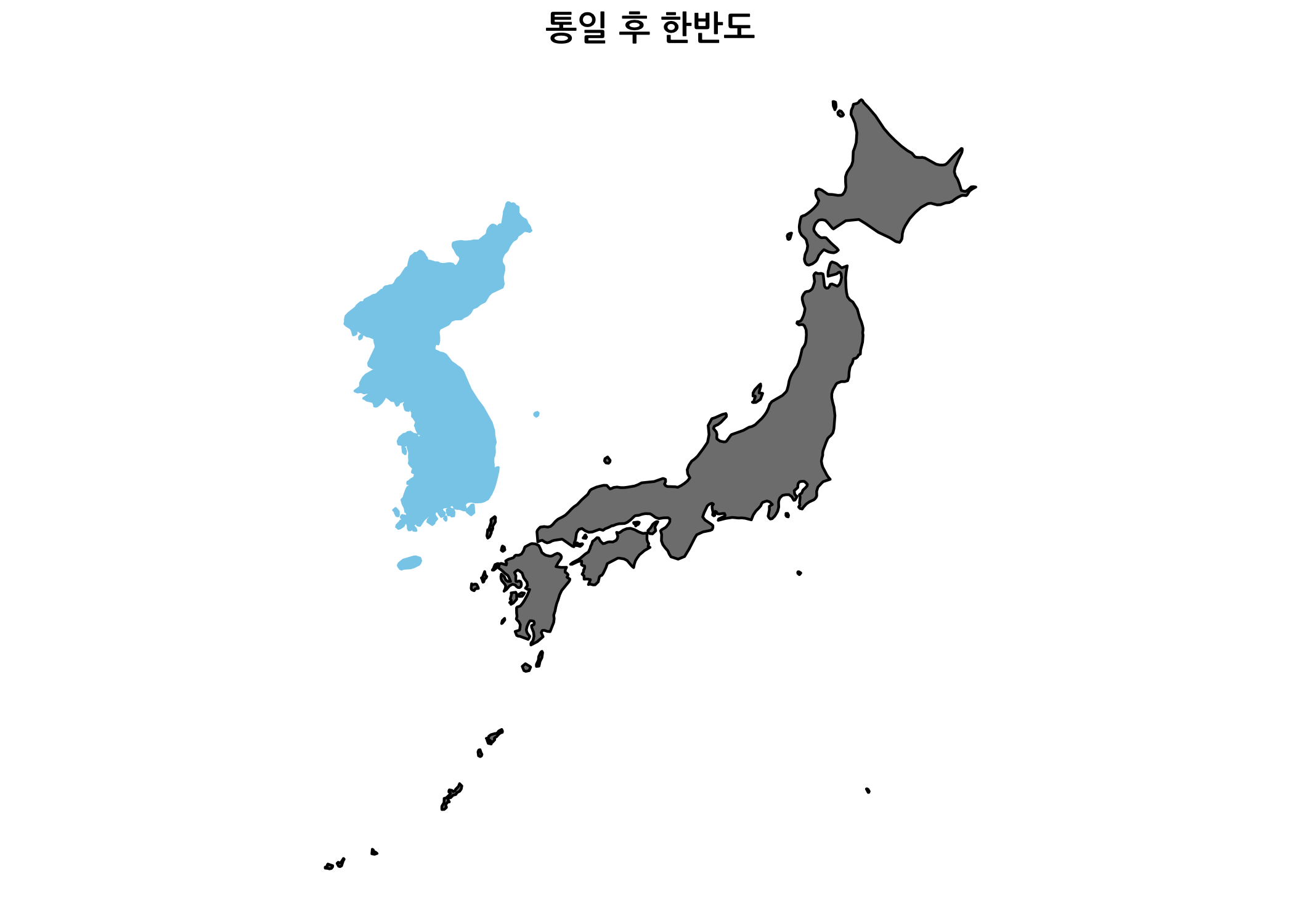
한 가지 아쉬운 점은 독도가 지도에 포함되어 있지 않다는 것입니다. 혹시나 해서 일본 지도 경계 데이터로 지도를 그려봤지만 독도는 일본 지도에도 포함되어 있지 않았습니다.
# 일본 지도 경계 데이터를 수집합니다.
japan <- map_data(map = 'world', region = 'Japan')
# 통일 후 한반도 이미지에 일본 지도를 추가합니다.
after +
geom_polygon(data = japan,
mapping = aes(x = long,
y = lat,
group = group),
fill = 'gray50',
color = 'black')
그래서 제가 독도를 만들어 추가했습니다. 내용이 조금 복잡하긴 합니다만 천천히 따라하면 누구나 할 수 있습니다. 먼저 ggmap 패키지의 geocode() 함수로 독도의 위경도 좌표를 얻은 후 다이아몬드 형태로 변형을 해주어 map_data() 함수를 실행한 결과 데이터프레임처럼 만들어주면 됩니다. 별로 어렵지 않죠?
# 필요 패키지를 불러옵니다.
library(ggmap)
# 구글 지도 API 인증키를 등록합니다. 매번 하려니 귀찮네요.
register_google(key = '자신의 구글 지도 API 인증키를 입력하세요')
# 독도의 위경도 좌표를 얻습니다.
dd <- geocode(location = "dokdo")
# 독도의 위경도 좌표를 중심으로 다이아몬드 형태로 만들기 위해
# 위경도 좌표 4개를 임의로 만듭니다.
# 그리고 map_data() 함수를 실행한 결과 데이터프레임처럼 만듭니다.
dokdo <-
data.frame(
long = c(dd[[1]]-0.01, dd[[1]], dd[[1]]+0.01, dd[[1]]),
lat = c(dd[[2]], dd[[2]]+0.01, dd[[2]], dd[[2]]-0.01),
group = 1,
order = 1:4,
region = 'South Korea',
subregion = 'Dok Do'
)
# 통일 후 한반도 지도 이미지에 독도를 추가합니다.
after +
geom_polygon(data = dokdo,
aes(x = long,
y = lat,
group = group),
fill = 'skyblue',
color = 'skyblue')
아주 작아서 잘 보이지 않지만 울릉도에서 4시 방향으로 조그마한 점이 하나 생겼습니다. 이쯤 해놓고 보니 더욱 보기 좋네요. 더 크게 만들면 보기에는 편할 것 같지만 과장된 이미지일 것 같아 이 정도 크기로 만족할까 합니다.
단계구분도(choropleth) 그리기
단계구분도는 지역별로 산출한 요약 정보량을 이용하여 시각화하는 것을 말합니다. 예를 들어, 선거가 끝나면 신문이나 방송에서 지도 하나 그려놓고 그 위에 특정 기준에 따라 권역별 색깔을 달리해놓은 것을 많이 보셨죠? 그렇게 그린 것이 단계구분도입니다. 이 포스팅을 끝까지 따라하다 보면 여러분도 단계구분도를 그릴 줄 아는 사람이 되는 것입니다. ^^
그런데 이제까지 배운 것만으로도 국가별 단계구분도를 그릴 수 있을 것 같다는 막연한 생각이 들지 않나요? 우리는 지도 경계 데이터를 수집해서 국가별로 다각형을 만들었고, 그 국가별 다각형에 채우기 색을 지정하는 것도 배웠습니다. 그러니 만약 국가별 요약 통계량, 예컨데 국가별 GDP 또는 인당GDP 컬럼을 만들어서 ‘aes(fill=GDP)’처럼 지정하면 국가별 단계구분도도 가능할 것입니다.
# 동북아시아 국가 및 지역별 GDP와 인당GDP 컬럼을 만듭니다.
# Nomial GDP와 Per Capita nomial GDP는 2017년 IMF 자료를 참고하였습니다.
# 북한 데이터만 2016년 UN 데이터를 사용했습니다.
# GDP : https://en.wikipedia.org/wiki/List_of_countries_by_GDP_(nominal)
# Per Capita GDP : https://en.wikipedia.org/wiki/List_of_countries_by_GDP_(nominal)_per_capita
# 위 데이터를 하나의 데이터프레임으로 만듭니다.
neAsiaStat <-
data.frame(
region = c('China', 'Japan', 'South Korea', 'North Korea', 'Taiwan', 'Mongolia'),
gdp = c(12014610, 4872135, 1538030, 17396, 579302, 10869),
perGdp = c(8643, 38440, 29891, 665, 24577, 3640))
이제 merge() 함수를 사용하여 두 개의 데이터프레임을 하나로 병합하겠습니다.
# 두 개의 데이터프레임을 하나로 병합합니다.
neAsia <- merge(x = neAsia,
y = neAsiaStat,
by = 'region',
all.x = TRUE)
# region 및 order 기준으로 오름차순 정렬합니다.
# 이 작업을 하지 않으면 다각형이 이상하게 그려질 수 있습니다!
neAsia <- neAsia[order(neAsia$region, neAsia$order), ]
# 데이터 미리보기 합니다.
head(x = neAsia, n = 10L)
## region long lat group order subregion gdp perGdp
## 1 China 110.8888 19.99194 1 1 1 12014610 8643
## 2 China 110.9383 19.94756 1 2 1 12014610 8643
## 3 China 110.9707 19.88330 1 3 1 12014610 8643
## 4 China 110.9977 19.76470 1 4 1 12014610 8643
## 5 China 111.0137 19.65547 1 5 1 12014610 8643
## 6 China 110.9127 19.58608 1 6 1 12014610 8643
## 7 China 110.8223 19.55791 1 7 1 12014610 8643
## 8 China 110.6409 19.29121 1 8 1 12014610 8643
## 9 China 110.6031 19.20703 1 9 1 12014610 8643
## 10 China 110.5722 19.17188 1 10 1 12014610 8643
10줄 미리보기한 결과를 보니 잘 들어가 있는 것으로 보입니다. 이제 단계구분도를 그려볼까요?
# 동북아시아 지도 데이터로 단계구분도를 그립니다. (명목 GDP 기준)
ggplot(data = neAsia,
mapping = aes(x = long,
y = lat,
group = group)) +
coord_map() +
geom_polygon(mapping = aes(fill = gdp),
color = 'black') +
my_theme +
ggtitle(label = '동북아시아 국가별 명목 GDP') +
theme(legend.position = c(0.9, 0.1),
legend.text = element_text(size = 8, face = 'bold'),
legend.title = element_text(size = 10, face = 'bold'))
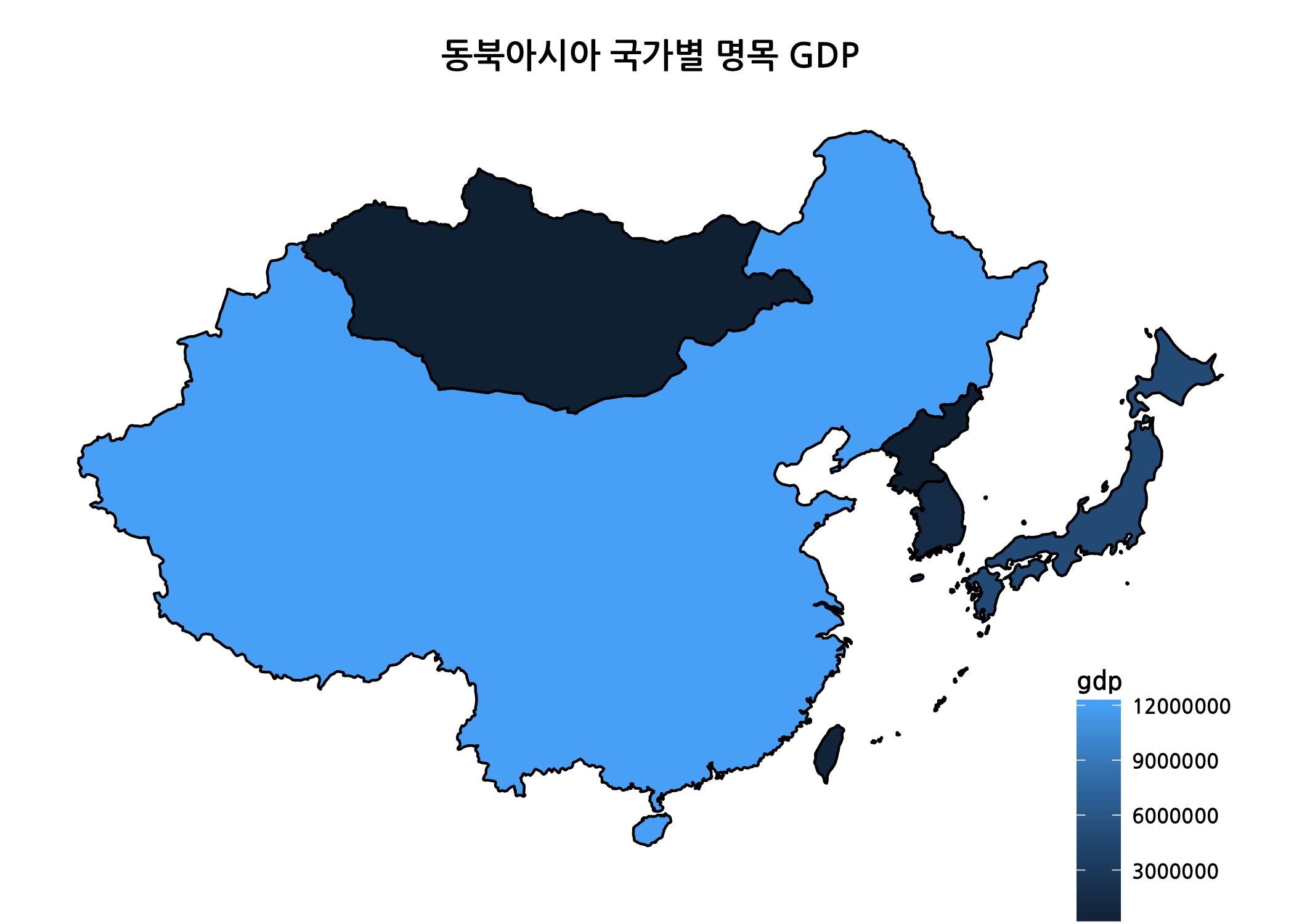
명목 GDP를 기준으로 단계구분도를 그려보니 세계 11위인 대한민국도 중국의 규모 앞에서는 어두컴컴한 지역이 되어 버렸습니다. 이번에는 인당 명목 GDP 기준으로도 단계구분도를 그려보겠습니다.
# 동북아시아 지도 데이터로 단계구분도를 그립니다. (인당 명목 GDP 기준)
ggplot(data = neAsia,
mapping = aes(x = long,
y = lat,
group = group)) +
coord_map() +
geom_polygon(mapping = aes(fill = perGdp),
color = 'black') +
my_theme +
ggtitle(label = '동북아시아 국가별 인당 명목 GDP') +
theme(legend.position = c(0.9, 0.1),
legend.text = element_text(size = 8, face = 'bold'),
legend.title = element_text(size = 10, face = 'bold'))
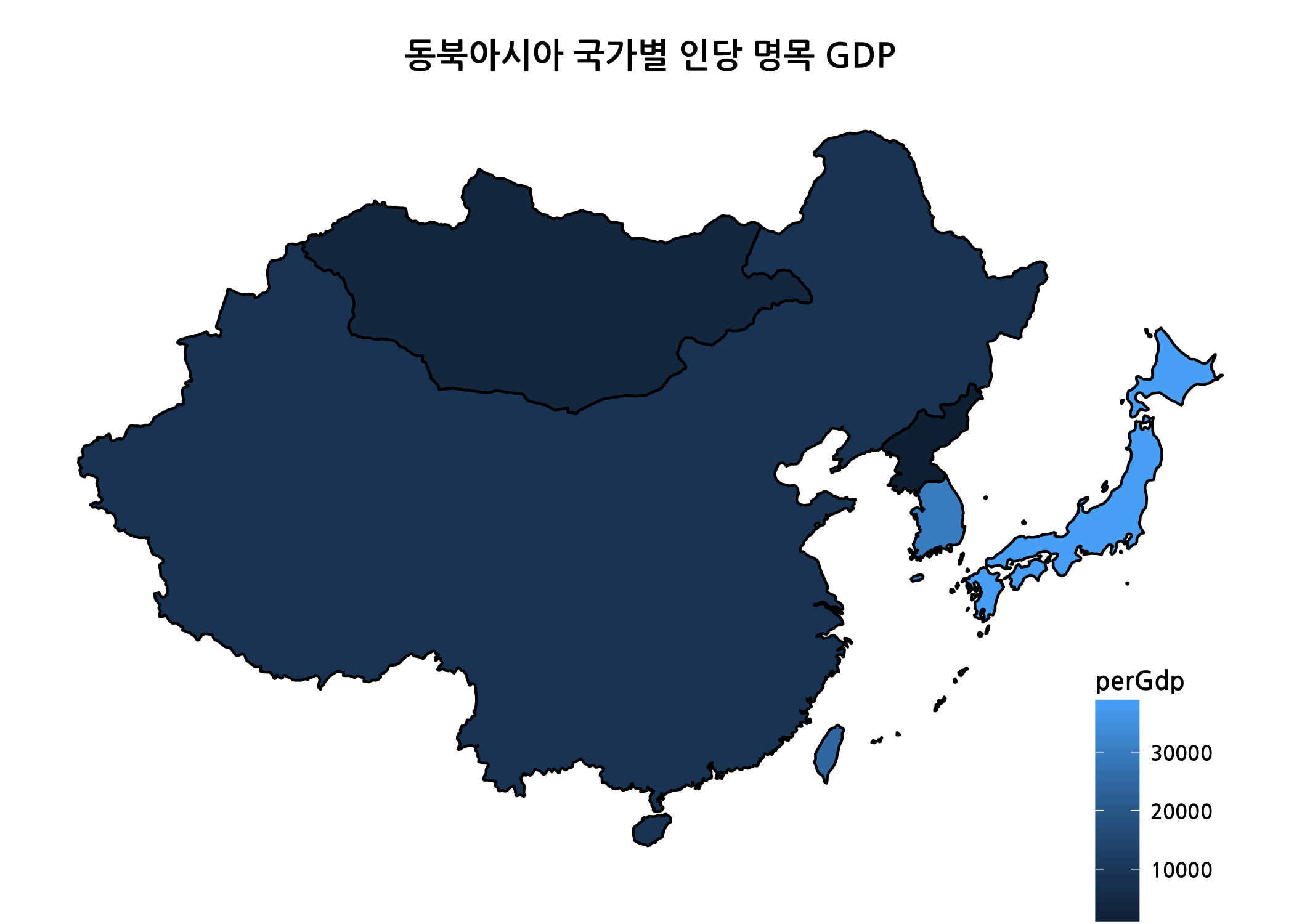
인당 명목 GDP 기준으로 단계구분도를 그려보니 상황이 역전되었습니다. 이제 우리나라 지역별로 단계구분도를 그려보도록 하겠습니다.
우리나라 행정경계 데이터로 단계구분도 그리기
통계청의 통계지리정보서비스 웹사이트에서 대한민국 센서스 행정경계구역 데이터를 내려받을 수 있습니다. 2018년 5월 현재, 2016년도 데이터가 제공되고 있습니다. 행경경계구역 데이터를 찾아서 신청하고 내려받는 방법을 설명하도록 하겠습니다.
통계청 행정경계구역 데이터 내려받기
통계지리정보서비스 웹사이트를 방문하면 아래와 같은 이미지가 열립니다. 우측 하단에 있는 자료제공목록 메뉴를 클릭합니다.
자료제공목록 화면을 아래로 내리면 통계지역경계에 센서스용 행정구역경계(전체) 데이터가 보입니다. 기준년도가 여러 개 있지만 가장 최근인 2016년을 사용하면 됩니다. 이 상태에서 가장 오른쪽에 있는 무료를 클릭하면 자료신청화면으로 넘어갑니다.
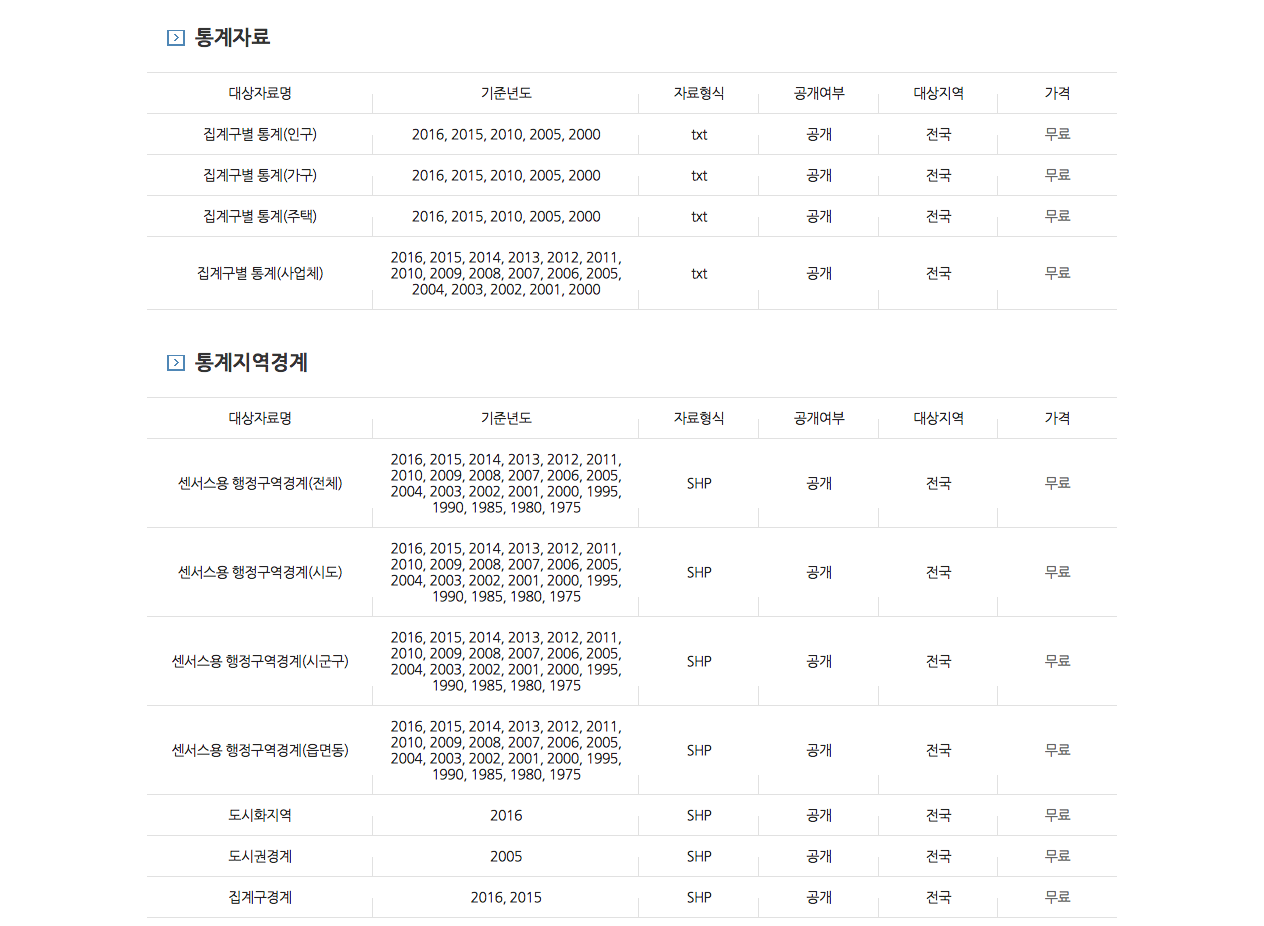
자료신청을 하려면 통계청 ONE-ID로 로그인을 해야 합니다. 아직 회원가입하지 않았다면 이번 기회에 통합회원가입하기 바랍니다.
로그인을 하면 아래와 같은 신청 화면이 열립니다. 제가 쓴 내용은 참고만 하고 본인의 의사에 맞도록 작성한 후 신청을 클릭하면 신청이 완료됩니다. 주의할 점은 중간에 자료선택 항목을 기입한 후 오른쪽 끝에 있는 추가를 클릭해야 한다는 것입니다.
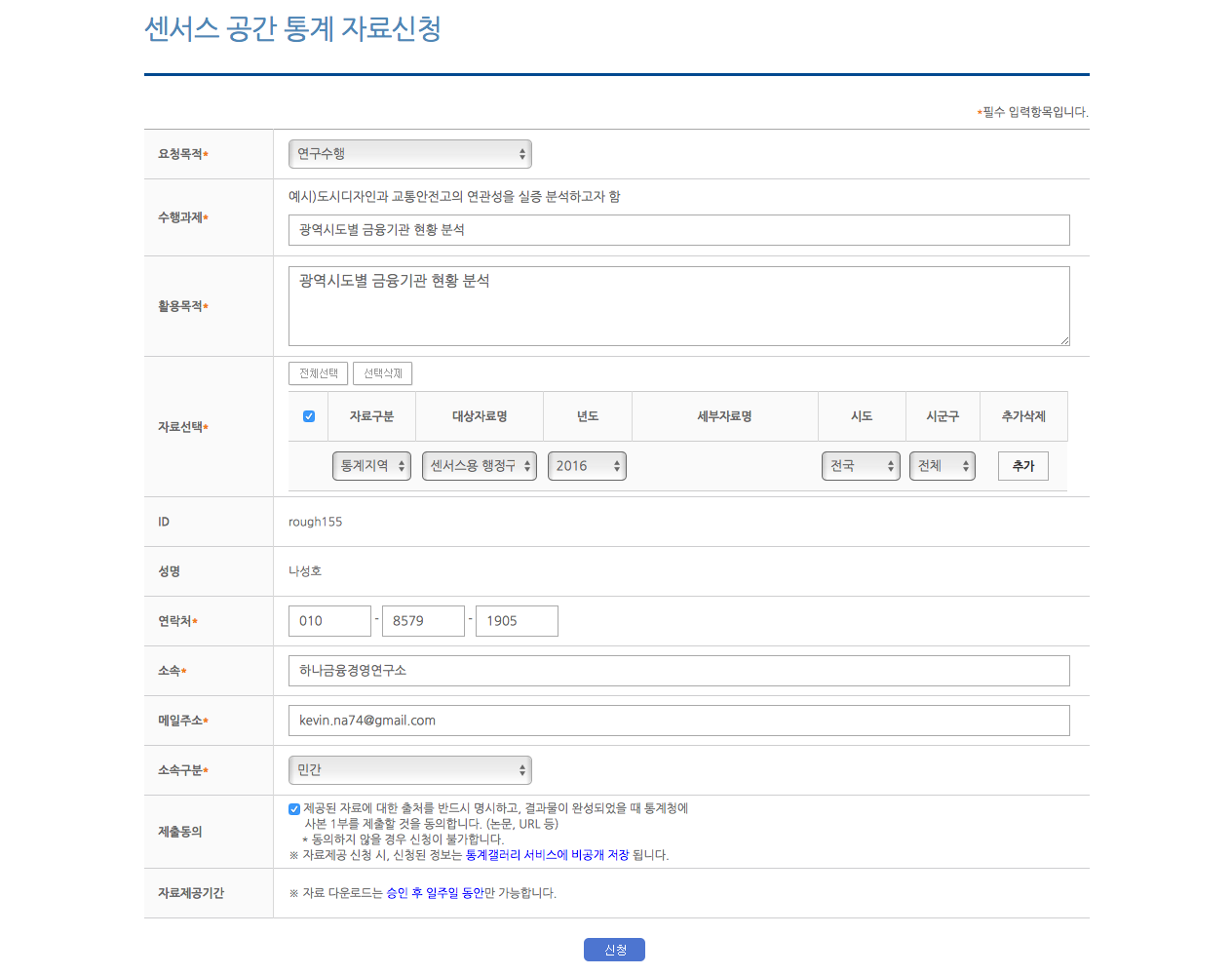
자료신청이 완료되면 과거 자료신청 이력 화면으로 넘어갑니다. 공교롭게도 저는 딱 1년 만에 다시 자료 신청을 하는 군요. 내년 5월 4일에 다시 만나요.
자료 승인은 시간이 조금 소요됩니다. 사람이 직접 확인을 하는 것 같습니다. 그래도 신청 당일에 완료되니 조금 기다렸다가 다시 확인해보기 바랍니다.
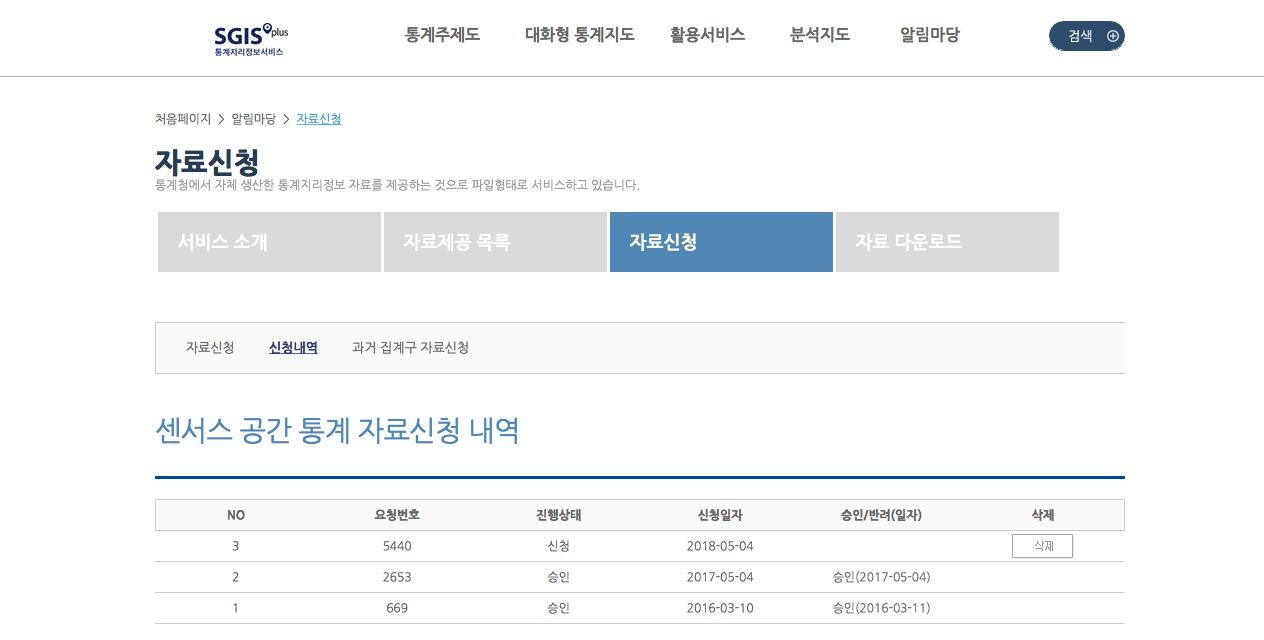
한 시간쯤 후에 다시 확인해보니 승인되었습니다.
상단 메뉴에서 오른쪽 끝에 자료 다운로드를 클릭하면 해당화면으로 이동합니다. 화면을 아래로 쭈욱 내리면 아래 표에 사용신청했던 통계지역경계 데이터가 보입니다. 표의 맨 오른쪽에 있는 다운로드 컬럼값 **bnd_all_))_2016 …**을 클릭하면 압축파일을 다운로드할 수 있습니다.
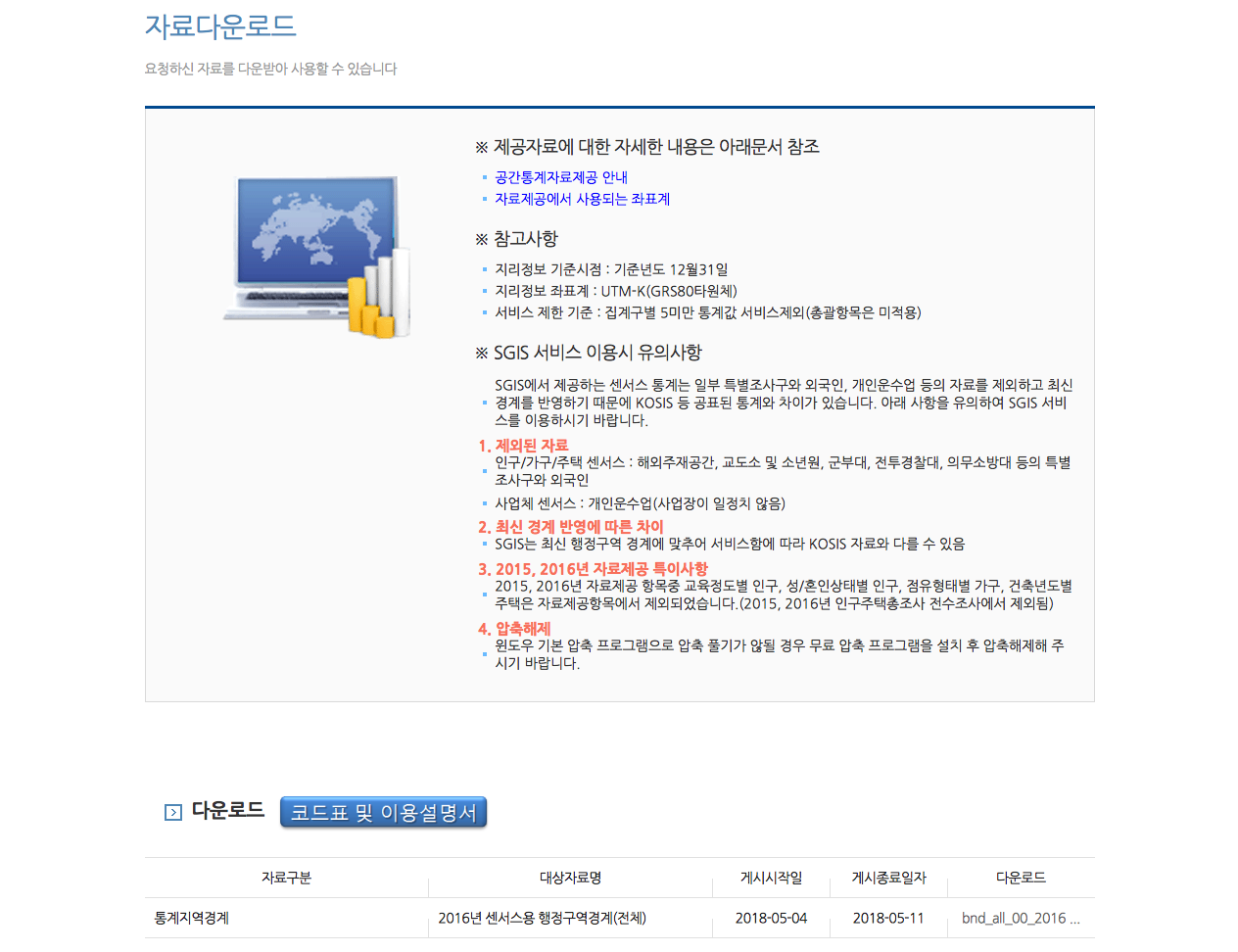
참고로, 제가 내려받은 파일은 ‘파일명.zip.html’형태로 되어 있었습니다. 따라서 파일명에서 맨 마지막에 있는 ‘.html’를 지우니 zip 파일로 변환되었었고, 이 상태에서 압축을 해제할 수 있었습니다.
압축파일을 풀면 그 안에 3개의 압축파일이 들어있습니다. bnd_sido_00_2016.zip은 17개 광역시도 단위 행정경계구역 데이터이고, bnd_sigungu_00_2016.zip은 시군구 단위 단위 행정경계구역 데이터입니다. 아울러 bnd_dong_00_2016.zip은 읍면동 단위 행정경계구역 데이터입니다. 이 세개의 압축파일을 적당한 곳에 저장한 압축을 해제합니다. 폴더를 유지한 상태로 압축을 해제하면 관리하기 편리합니다.
행정경계구역 데이터 불러오기
우리는 이번 예제에서 광역시도 단위로 된 단계구분도를 만들 예정이므로 bnd_sido_00_2016.zip만 압축을 해제하도록 하겠습니다. 압축을 해제하니 이번에는 4개의 파일이 생겼습니다. 우리는 이 중에서 shp 확장자 파일과 dbf 확장자 파일을 가지고 행정경계구역 데이터를 얻을 것입니다. 두 개의 데이터가 같은 폴더에 들어있어야 됩니다.
# 데이터가 제대로 들어있는지 확인합니다.
list.dirs(path = './data')
## [1] "./data" "./data/bnd_sido_00_2015"
## [3] "./data/bnd_sido_00_2016"
list.files(path = './data/bnd_sido_00_2016')
## [1] "bnd_sido_00_2016.dbf" "bnd_sido_00_2016.prj" "bnd_sido_00_2016.shp"
## [4] "bnd_sido_00_2016.shx"
현재 작업경로에서 /data/bnd_sido_00_2016 폴더 안에 shx 및 dbf 파일이 저장되어 있는 것을 확인했으니 이제 불러오겠습니다. rgdal 패키지의 readOGR() 함수를 사용하면 됩니다. dsn 인자에는 행정경계구역 데이터가 들어있는 폴더를 지정해주면 되고, layer 인자에는 공통의 파일명을 확장자 없이 지정해주면 됩니다. 코드를 보면 쉽게 이해할 수 있습니다.
# shp 파일을 불러옵니다. (광역시도 데이터)
sido <-
rgdal::readOGR(
dsn = './data/bnd_sido_00_2016',
layer = 'bnd_sido_00_2016',
encoding = 'CP949')
## OGR data source with driver: ESRI Shapefile
## Source: "/Users/drkevin/Documents/GitHub/MrKevinNa.github.io/rmds/data/bnd_sido_00_2016", layer: "bnd_sido_00_2016"
## with 17 features
## It has 6 fields
## Integer64 fields read as strings: OBJECTID
# sido 객체의 클래스를 확인합니다.
class(x = sido)
## [1] "SpatialPolygonsDataFrame"
## attr(,"package")
## [1] "sp"
sido 객체의 클래스는 SpatitalPloygonsDataFrame입니다. 이것을 데이터프레임 형태로 변환해주어야 합니다. 이 때 사용하는 함수로는 ggplot2 패키지의 fortify() 함수입니다.
# sido 객체를 데이터프레임으로 변환합니다.
sidoDf <- fortify(model = sido)
## Regions defined for each Polygons
# sidoDF의 구조를 확인합니다.
str(object = sidoDf)
## 'data.frame': 5346636 obs. of 7 variables:
## $ long : num 957671 957875 957985 957985 957985 ...
## $ lat : num 1966937 1966792 1966830 1966830 1966830 ...
## $ order: int 1 2 3 4 5 6 7 8 9 10 ...
## $ hole : logi FALSE FALSE FALSE FALSE FALSE FALSE ...
## $ piece: Factor w/ 4207 levels "1","2","3","4",..: 1 1 1 1 1 1 1 1 1 1 ...
## $ id : chr "0" "0" "0" "0" ...
## $ group: Factor w/ 13781 levels "0.1","1.1","1.2",..: 1 1 1 1 1 1 1 1 1 1 ...
# 미리보기 합니다.
head(x = sidoDf, n = 10L)
## long lat order hole piece id group
## 1 957671.4 1966937 1 FALSE 1 0 0.1
## 2 957875.3 1966792 2 FALSE 1 0 0.1
## 3 957984.8 1966830 3 FALSE 1 0 0.1
## 4 957984.8 1966830 4 FALSE 1 0 0.1
## 5 957984.8 1966830 5 FALSE 1 0 0.1
## 6 958154.4 1966775 6 FALSE 1 0 0.1
## 7 958154.4 1966775 7 FALSE 1 0 0.1
## 8 958294.3 1966848 8 FALSE 1 0 0.1
## 9 958305.7 1966944 9 FALSE 1 0 0.1
## 10 958364.3 1966924 10 FALSE 1 0 0.1
sidoDf 객체는 데이터프레임이고 5,346,636행 7열이라는 것을 알 수 있습니다. 첫 10행만 미리보기 하니 7개 열은 long(경도), lat(위도), order(순번), hole, piece, id, group이었습니다. 경도와 위도의 숫자가 구글 지도 API에서 봤던 것과 다르죠? 바로 좌표계가 달라서 그렇습니다. 구글 지도 API에서 제공되는 좌표계는 UTM (WGS84 타원체) 좌표 기준이고, 행정경계구역 데이터는 UTM-K (GRS80 타원체) 좌표 기준입니다.
너무 당연한 말이겠지만 좌표계가 다른 데이터를 하나의 지도로 출력할 수 없습니다. 그리고 제가 아는 바로는 우리나라 정부기관에서 제공하는 좌표계의 대부분이 UTM-K 좌표 기준으로 작성된 것입니다. 이런 점에서 공공데이터를 사용할 때 은근 스트레스를 받게 됩니다. 어렵게 구한 데이터의 좌표계가 서로 다르니 융합해서 사용할 수 없기 때문입니다.
아울러 UTM-K 좌표로 ggplot()으로 지도 경계 이미지를 그릴 때 coord_map() 함수를 사용할 수 없습니다. 그러므로 UTM-K 좌표를 UTM 좌표로 변환해주는 작업이 필요합니다. 이번 포스팅을 작성하면서 관련 자료를 찾았습니다. 아래에 좌표를 변환하는 함수를 소개하였으니 참고하기 바랍니다.
다시 진도를 나가겠습니다. 이번 지도 시각화 예제에 sidoDf 데이터 컬럼 거의 모두 다 사용합니다. 다만 ‘서울, 경기’와 같은 광역시도명이 없는데요. 이걸 만들어 붙이는 작업을 하도록 하겠습니다.
# sido 객체의 data 요소를 확인합니다.
# sido 데이터는 S4 클래스이므로 '@' 기호를 사용해야 합니다.
sido@data
## OBJECTID BASE_YEAR SIDO_CD SIDO_NM SHAPE_LENG SHAPE_AREA
## 0 1 2016 11 서울특별시 189478.1 605248658
## 1 2 2016 21 부산광역시 526479.3 783988125
## 2 3 2016 22 대구광역시 215638.4 879585938
## 3 4 2016 23 인천광역시 1227623.2 1099356702
## 4 5 2016 24 광주광역시 141014.9 498003505
## 5 6 2016 25 대전광역시 157059.7 539472081
## 6 7 2016 26 울산광역시 322752.3 1061392666
## 7 8 2016 29 세종특별자치시 149141.4 464844343
## 8 9 2016 31 경기도 1374254.7 10250080212
## 9 10 2016 32 강원도 1152337.6 16809249077
## 10 11 2016 33 충청북도 796054.9 7408394601
## 11 12 2016 34 충청남도 1917052.6 8263089497
## 12 13 2016 35 전라북도 1295413.9 8090368561
## 13 14 2016 36 전라남도 7643275.8 12421378360
## 14 15 2016 37 경상북도 1427854.7 19029174085
## 15 16 2016 38 경상남도 3138760.6 10553277187
## 16 17 2016 39 제주특별자치도 705159.4 1864750932
S4 클래스! 모르는 단어가 하나 나왔습니다. 사실 저도 거의 모르는 분야라 설명을 드리기는 어렵습니다만, R에는 3가지 객체지향 프로그래밍 시스템이 있는데 S3, S4, 그리고 R5입니다. S3와 S4 클래스의 차이로는 객체지향 구현 방식에 있다고 합니다. 우리가 그동안 마주쳤던 클래스는 S3입니다. 객체와 그 객체의 멤버를 연결하는 기호로 $를 사용합니다. 꽤 익숙하죠? 반면, S4 클래스는 방금 위에서 살펴본 것처럼 @ 기호를 사용합니다.
우리는 사용자 입장에서 R을 잘 쓰면 되잖아요. 물론 객체지향 프로그래밍이 어떤 것인지 이해하면 정말 좋겠지만 일단 R에서는 일반적으로 S3 클래스로 객체가 만들어지고 사용되고, 특별한 경우에 S4 클래스 객체를 만난다 정도로 마무리 하도록 하겠습니다.[1]
아무튼 sido@data를 출력해보니 sidoDf 데이터에 필요한 광역시도명을 갖고 있는 것으로 보입니다. 한 가지 반가운 사실은 sido@data가 데이터프레임이라는 것입니다.
# sido@data 클래스를 확인합니다.
class(x = sido@data)
## [1] "data.frame"
# sido@data 구조를 확인합니다.
str(object = sido@data)
## 'data.frame': 17 obs. of 6 variables:
## $ OBJECTID : chr "1" "2" "3" "4" ...
## $ BASE_YEAR : chr "2016" "2016" "2016" "2016" ...
## $ SIDO_CD : chr "11" "21" "22" "23" ...
## $ SIDO_NM : chr "서울특별시" "부산광역시" "대구광역시" "인천광역시" ...
## $ SHAPE_LENG: num 189478 526479 215638 1227623 141015 ...
## $ SHAPE_AREA: num 605248658 783988125 879585938 1099356702 498003505 ...
sido@data를 확인해보니 17행, 6열의 데이터프레임이었습니다. 17개 광역시도별 요약 데이터인 것으로 이해하면 될 것입니다. sido@data에서 BASE_YEAR, SIDO_CD 및 SIDO_NM 컬럼을 sidoDf 객체에 병합하면 문제가 해결될 것 같습니다. 그러면 두 개의 데이터프레임으로 병합할 때 어떤 컬럼을 기준으로 해야 할까요? sidoDf에는 id가 있습니다. 그래서 sido@data에서 id로 대체할만한 컬럼을 찾아보니, 행번호로 id를 만들면 될 것 같습니다.
# sido@data에서 행번호를 id 컬럼으로 만듭니다.
sido@data$id <- rownames(x = sido@data)
# 이제 두 데이터프레임을 병합니다.
sidoDf <- merge(x = sidoDf,
y = sido@data[, c('id', 'BASE_YEAR', 'SIDO_CD', 'SIDO_NM')],
by = 'id',
all.x = TRUE)
# id와 order 기준으로 오름차순 정렬합니다.
sidoDf <- sidoDf[order(sidoDf$id, sidoDf$order), ]
# 미리보기 합니다.
head(x = sidoDf, n = 10L)
## id long lat order hole piece group BASE_YEAR SIDO_CD
## 1 0 957671.4 1966937 1 FALSE 1 0.1 2016 11
## 2 0 957875.3 1966792 2 FALSE 1 0.1 2016 11
## 3 0 957984.8 1966830 3 FALSE 1 0.1 2016 11
## 4 0 957984.8 1966830 4 FALSE 1 0.1 2016 11
## 5 0 957984.8 1966830 5 FALSE 1 0.1 2016 11
## 6 0 958154.4 1966775 6 FALSE 1 0.1 2016 11
## 7 0 958154.4 1966775 7 FALSE 1 0.1 2016 11
## 8 0 958294.3 1966848 8 FALSE 1 0.1 2016 11
## 9 0 958305.7 1966944 9 FALSE 1 0.1 2016 11
## 10 0 958364.3 1966924 10 FALSE 1 0.1 2016 11
## SIDO_NM
## 1 서울특별시
## 2 서울특별시
## 3 서울특별시
## 4 서울특별시
## 5 서울특별시
## 6 서울특별시
## 7 서울특별시
## 8 서울특별시
## 9 서울특별시
## 10 서울특별시
5백만 건이 넘는 데이터라 그런지 시간이 조금 걸립니다. 병합한 다음 반드시 id와 order 기준으로 오름차순 정렬을 해야 합니다. 그렇지 않으면 다각형을 그릴 때 정상적인 다각형이 만들어지지 않습니다.
처음 10행을 미리보기 해보니 SIDO_CD와 SIDO_NM이 잘 들어가 있습니다. 컬럼명을 바꿔주면 보기 좋을 것 같습니다.
# 새로 붙인 컬럼들의 이름을 변경합니다.
colnames(x = sidoDf)[8:10] <- c('year', 'sidoCd', 'sidoNm')
광역시도명을 두 글자로 변환하면 좋겠습니다. 어떻게 하면 좋을까요? 서울특별시와 6대 광역시도, 세종특별자치시, 제주특별자치도 및 경기도와 강원도는 앞 두 글자만 따오면 될 것입니다. 그리고 나머지 지방도의 경우는 첫 번째 글자와 세 번째 글자인 ‘남/북’만 가져와서 붙이면 해결되겠죠?
# 광역시도명을 두 글자로 줄입니다.
sidoDf$sidoNm2 <-
ifelse(test = str_detect(string = sidoDf$sidoNm, pattern = '(남|북)도'),
yes = str_c(str_sub(string = sidoDf$sidoNm, start = 1, end = 1),
str_sub(string = sidoDf$sidoNm, start = 3, end = 3)),
no = str_sub(string = sidoDf$sidoNm, start = 1, end = 2))
# 광역시도명의 빈도수를 확인합니다.
table(sidoDf$sidoNm2) %>% sort()
##
## 대전 세종 대구 광주 서울 충북 울산 경기 부산
## 4641 5609 5866 7423 10801 20454 74041 91129 107653
## 강원 경북 인천 제주 전북 충남 경남 전남
## 124080 176249 237123 258939 408359 427135 814653 2572481
광역시도별로 빈도수를 구하고 오름차순으로 정렬하니 전남 지역의 행 수가 가장 많습니다. 왜 그럴까요? 제 생각에는 전남 지역의 면적이 넓은 이유도 있겠지만 신안군에 섬들이 많아서 그런 것 같습니다.
이로써 단계구분도에 필요한 데이터 준비는 다 됐습니다. 이제 ggplot() 함수로 기본형 지도를 그려볼 차례입니다. 그런데 한 가지 문제가 있습니다. 2016년 행정경계구역 데이터가 5,346,636건으로 2015년 733,766 건에 비해 7배 이상 많습니다. 갑자기 왜 이렇게 많아졌는지 통계청만 알고 있을테지만 이대로는 지도를 그리기 어려울 것입니다.
썩 내키는 방법은 아니지만, 데이터를 조금 잘라보도록 하겠습니다. 예를 들어, order를 4로 나누었을 때 나머지가 1인 행만 남도록 하여 원래 데이터를 1/4로 줄이는 것입니다.
# order를 4로 나누었을 때 나머지가 1인 행만 남깁니다.
sidoDf1 <- sidoDf[sidoDf$order %% 4 == 1, ]
# 새로 만든 데이터프레임의 건수를 확인합니다.
nrow(x = sidoDf1)
## [1] 1336668
5백만 건이 넘는 데이터가 약 134만 건으로 줄었습니다. 이제 ggplot() 함수를 이용하여 지도 이미지를 생성해보겠습니다.
# sidoDf1 데이터로 지도 이미지를 생성합니다.
sidoMap <-
ggplot(data = sidoDf1,
mapping = aes(x = long,
y = lat,
group = group)) +
geom_polygon(fill = 'white',
color = 'black') +
my_theme
# sidoMap을 그립니다.
sidoMap
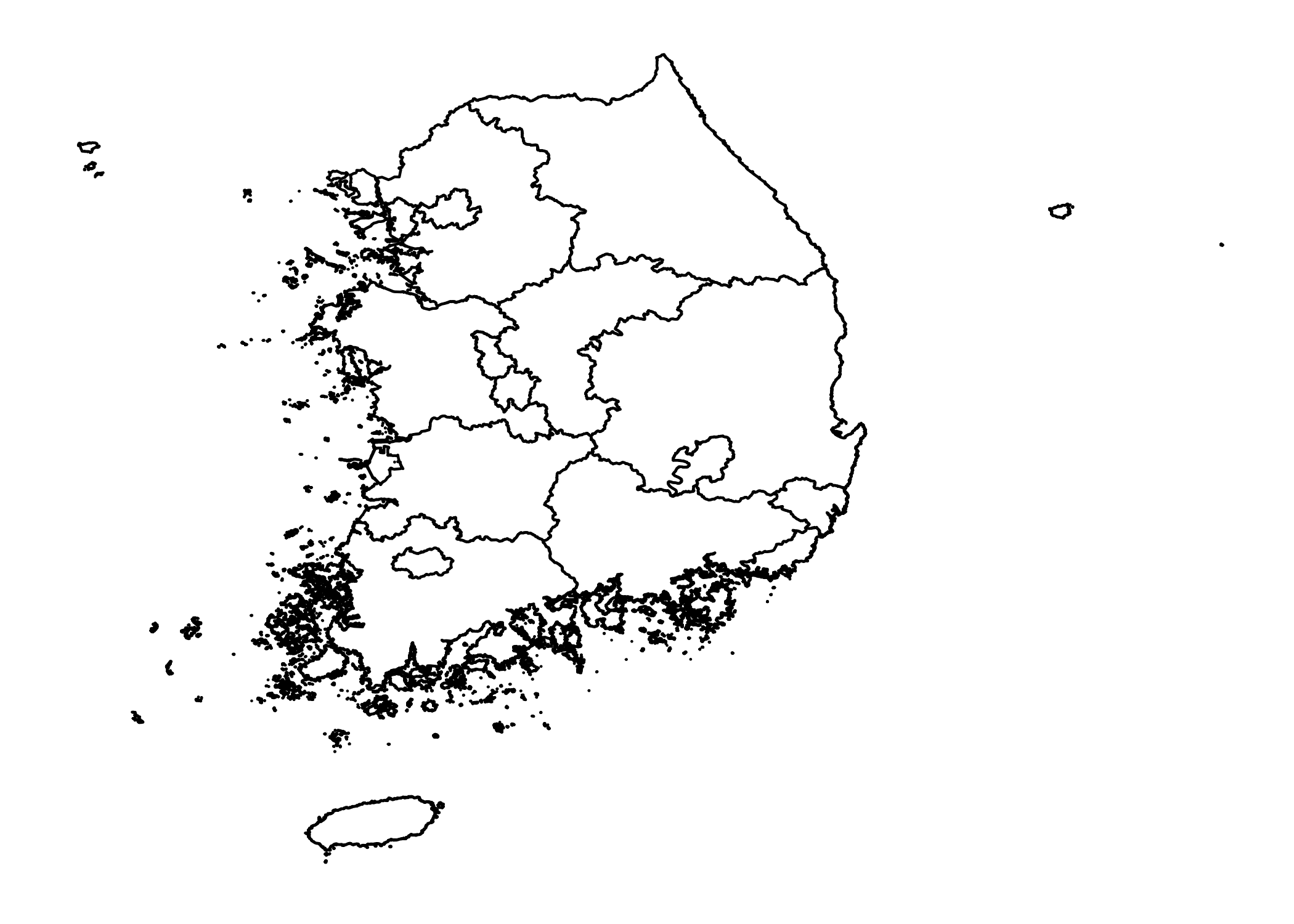
서해안과 남해안을 중심으로 섬들이 많습니다. 깔끔한 지도를 얻으려먼 섬과 같은 부속지역을 제외해야 합니다. sidoDf1$piece == 1인 조건을 만족하는 건만 남기면 됩니다.
# 부속지역을 제외합니다.
sidoDf2 <- subset(x = sidoDf1, subset = sidoDf1$piece == 1)
# 건수를 확인합니다.
nrow(x = sidoDf2)
## [1] 321777
부속지역을 제외하니 다시 32만여 건으로 크게 줄었습니다. 그런데 이 데이터로 지도를 그려기 전에 고려해야 할 사항이 하나 있습니다. ggplot() 함수가 x, y 축의 범위를 자동으로 지정해주기 때문에 앞서 그린 지도가 가로로 퍼진 모양이 되었습니다. map_data() 함수로 받은 지도 데이터는 WGS84 좌표계라 그런지 coord_map() 함수가 적용되었는데, 통계청 행정경계구역 데이터는 GRS80 좌표계라 coord_map() 함수를 사용해 봐도 지도가 그려지지 않았습니다.
WGS84 좌표를 GRS80 좌표로 변환해주는 함수를 인터넷에서 찾아보니 괜찮은 블로그가 있었습니다. 그 블로그 내용을 참고하여 아래와 같이 변형해 보았습니다[2]. 이제 이 함수를 이용하여 sidoDf2의 위경도 좌표를 변환하겠습니다.
# 필요 패키지를 불러옵니다.
library(sp)
library(rgdal)
library(magrittr)
# 좌표계를 변환하는 함수를 생성합니다. (GRS80 -> WGS84)
convertCoords <- function(lon, lat) {
# 2개의 벡터를 입력 받아 데이터프레임으로 만들고
# SpatialPoints 타입으로 변환합니다.
xy <- data.frame(lon = lon, lat = lat)
coordinates(obj = xy) <- ~ lon + lat
# CRS(Coordinate Reference System)을 설정합니다.
fmCRS <- CRS('+proj=tmerc +lat_0=38 +lon_0=127.5 +k=0.9996 +x_0=1000000 +y_0=2000000 +ellps=GRS80 +units=m +no_defs')
toCRS <- CRS('+proj=longlat +ellps=WGS84 +datum=WGS84 +no_defs')
# GRS80 좌표를 WGS84 좌표로 변환하여 반환합니다.
xy %>%
SpatialPoints(proj4string = fmCRS) %>%
spTransform(CRSobj = toCRS) %>%
SpatialPoints() %>%
as.data.frame() %>%
set_colnames(c('lonWGS84', 'latWGS84')) %>%
return()
}
# sidoDf 위경도 좌표를 변환합니다.
changedCoords <- convertCoords(lon = sidoDf2$long, lat = sidoDf2$lat)
# 변환된 자표를 sidoDf에 열 기준으로 추가합니다.
sidoDf2 <- cbind(sidoDf2, changedCoords)
coord_map()을 추가하여 WGS84 위경도 좌표로 지도를 그려보겠습니다.
# 부속지역을 제외한 데이터로 지도 이미지를 생성합니다.
sidoMap <-
ggplot(data = sidoDf2,
mapping = aes(x = lonWGS84,
y = latWGS84,
group = group)) +
geom_polygon(fill = 'white',
color = 'black') +
my_theme +
coord_map()
# sidoMap을 그립니다.
sidoMap
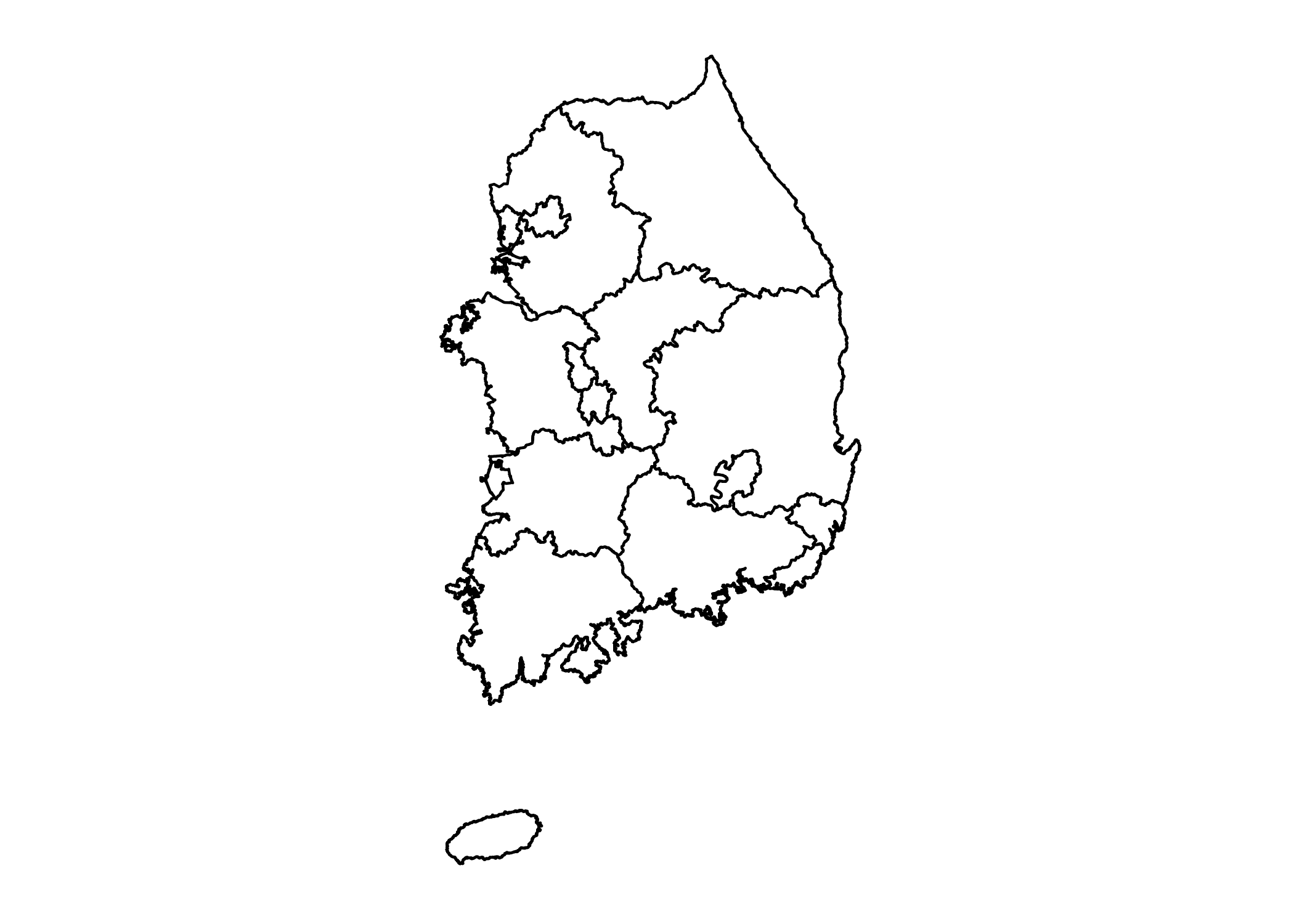
예상했던 것보다 더 예쁘게 잘 그려졌습니다. 이제 이 지도 위에 특정 지역의 채우기 색을 지정해보겠습니다. 예를 들어, 광주광역시는 빨간색으로 채우고 대구광역시는 파란색으로 채우는 것입니다.
# 광주광역시의 채우기 색을 "red", 대구광역시 채우기 색을 "blue"로 변경합니다.
sidoMap +
geom_polygon(data = sidoDf2[sidoDf2$sidoNm2 == '광주', ],
mapping = aes(x = lonWGS84,
y = latWGS84,
group = group),
fill = 'red') +
geom_polygon(data = sidoDf2[sidoDf2$sidoNm2 == '대구', ],
mapping = aes(x = lonWGS84,
y = latWGS84,
group = group),
fill = 'blue')
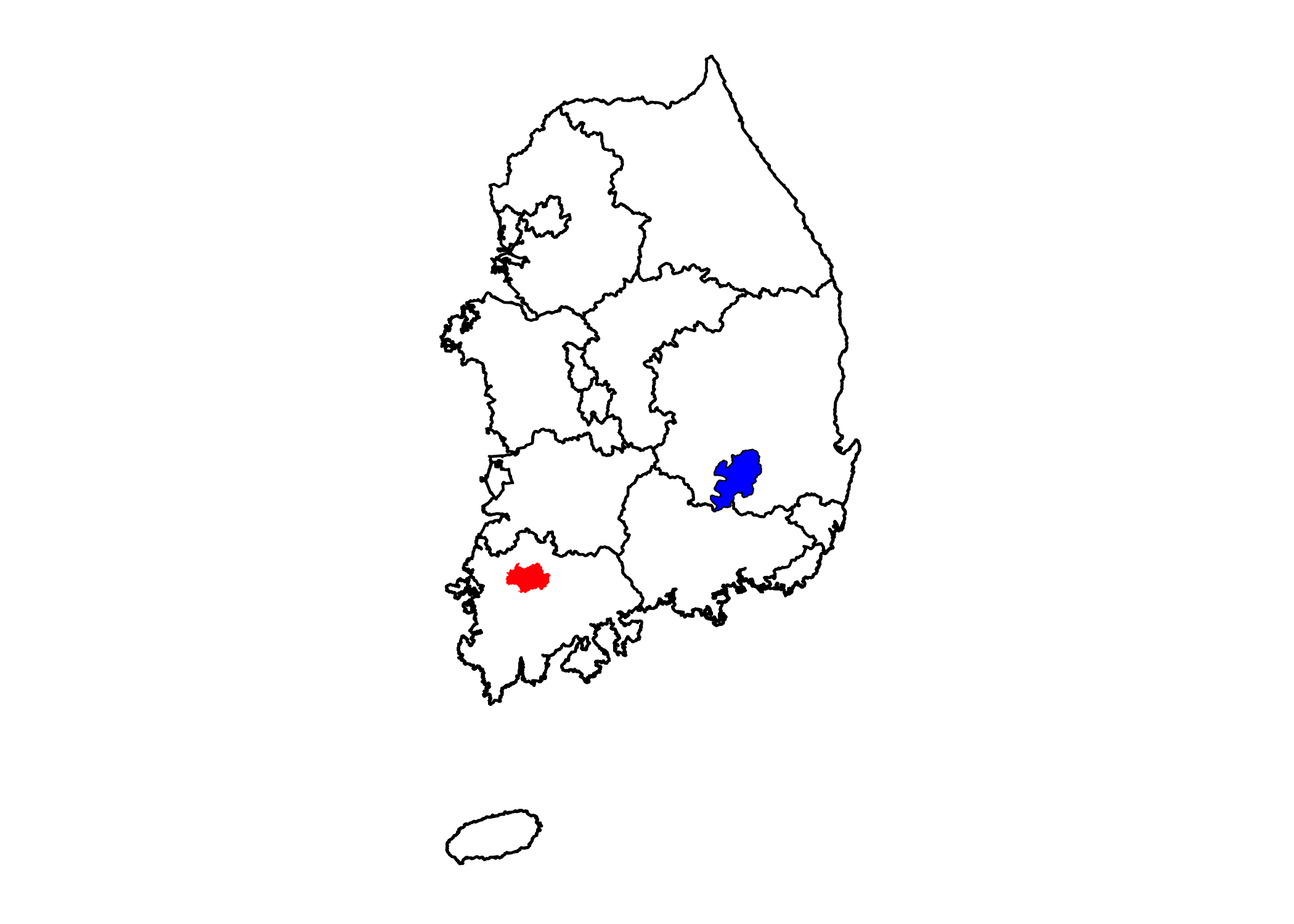
광역시도별로 채우기 색을 지정할 수 있다는 것은 요약 통계량을 활용하여 단계구분도를 그릴 수 있다는 것을 의미합니다. 통계청에서 행정구역(시도)별 1인당 지역내총생산, 지역총소득, 개인소득 민간소비 데이터를 제공하고 있습니다. 링크를 클릭하여 통계청으로 이동한 후 자료를 엑셀 파일로 내려받은 후 적당한 폴더로 옮겨놓습니다. 이 엑셀 파일을 읽어 sidoStat이라는 새 객체에 할당합니다.
# 저장된 통계청 파일명을 지정합니다.
statFile <- list.files(path = './data', pattern = '행정구역')
# 통계청 데이터를 불러옵니다.
sidoStat <- xlsx::read.xlsx(file = str_c('./data/', statFile),
sheetName = '데이터',
startRow = 2)
# 컬럼명을 변경합니다.
colnames(sidoStat) <- c('광역시도명', '인당지역총생산', '인당지역총소득', '인당개인소득', '인당민간소비')
# 광역시도명을 두 글자로 줄입니다.
sidoStat$sidoNm2 <-
ifelse(test = str_detect(string = sidoStat$광역시도명, pattern = '(남|북)도'),
yes = str_c(str_sub(string = sidoStat$광역시도명, start = 1, end = 1),
str_sub(string = sidoStat$광역시도명, start = 3, end = 3)),
no = str_sub(string = sidoStat$광역시도명, start = 1, end = 2))
# sidoDf2에 광역시도명으로 병합합니다.
sidoDf2 <- merge(x = sidoDf2,
y = sidoStat[, 2:6],
by = 'sidoNm2',
all.x = TRUE)
# id와 order 기준으로 오름차순 정렬합니다.
sidoDf2 <- sidoDf2[order(sidoDf2$id, sidoDf2$order), ]
이제 모든 준비가 다 완료되었습니다. 단계구분도를 여러 개 그리기 위해 함수로 만든 후 하나씩 그려보겠습니다.
# 나만의 팔레트도 만들어서 적용해보겠습니다.
library(RColorBrewer)
myPal <- brewer.pal(n = 9, name = 'YlOrRd')
# 단계구분도를 그리는 함수를 생성합니다.
drawChoropleth <- function(var) {
# 채우기 기준 변수명을 지정합니다.
varNm <- str_c('sidoDf2', var, sep = '$') %>%
parse(text = .) %>%
eval()
# 단계구분도를 그립니다.
ggplot(data = sidoDf2,
mapping = aes(x = lonWGS84,
y = latWGS84,
group = group,
fill = varNm)) +
geom_polygon(color = 'gray30') +
coord_map() +
ggtitle(label = str_c('광역시도별', var, sep = ' ')) +
my_theme +
theme(legend.position = c(0.9, 0.1),
legend.text = element_text(size = 8, face = 'bold'),
legend.title = element_text(size = 10, face = 'bold')) +
scale_fill_gradient(low = myPal[3],
high = myPal[7])
}
# 단계구분도를 그립니다.
drawChoropleth(var = '인당개인소득')
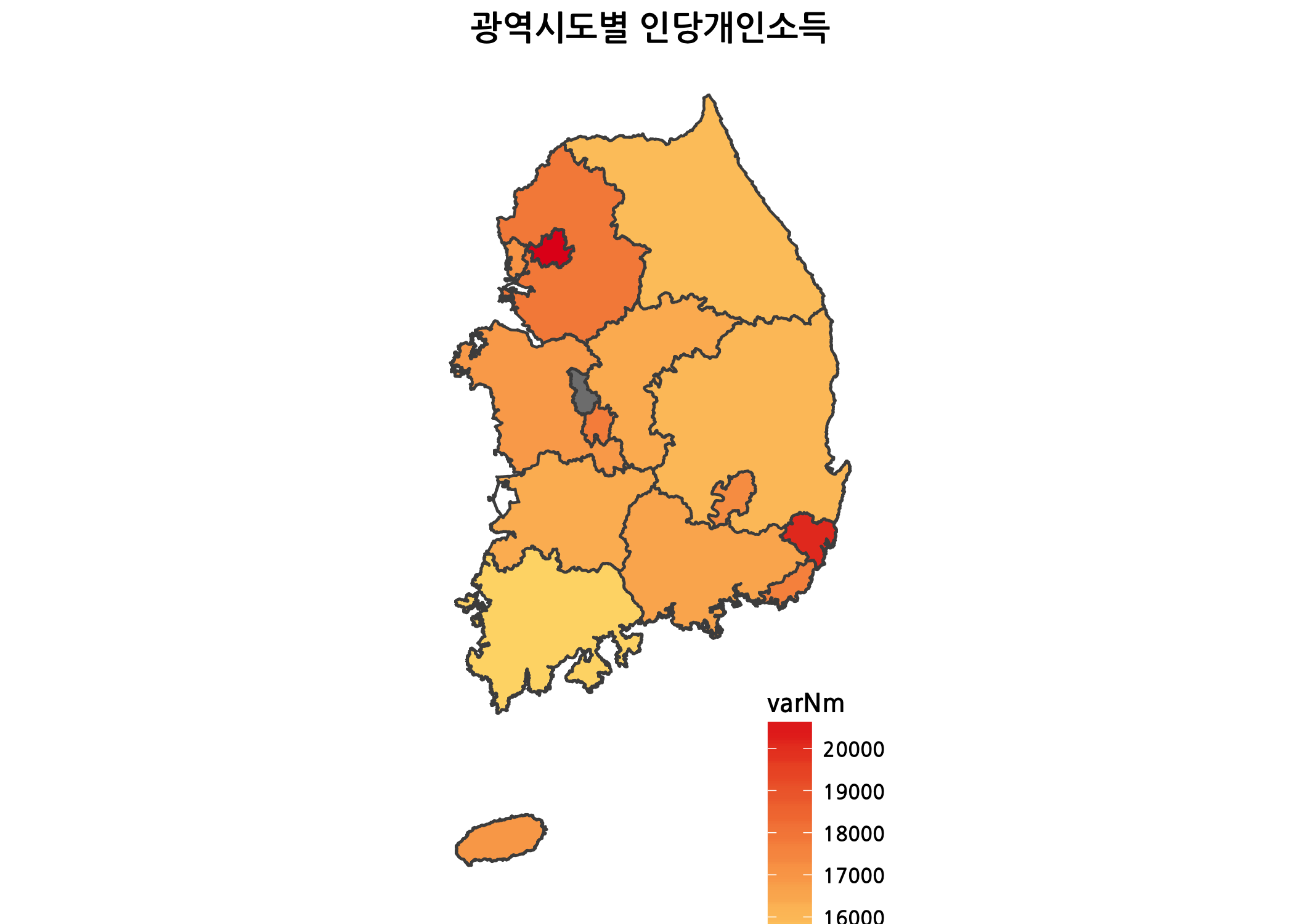
drawChoropleth(var = '인당민간소비')
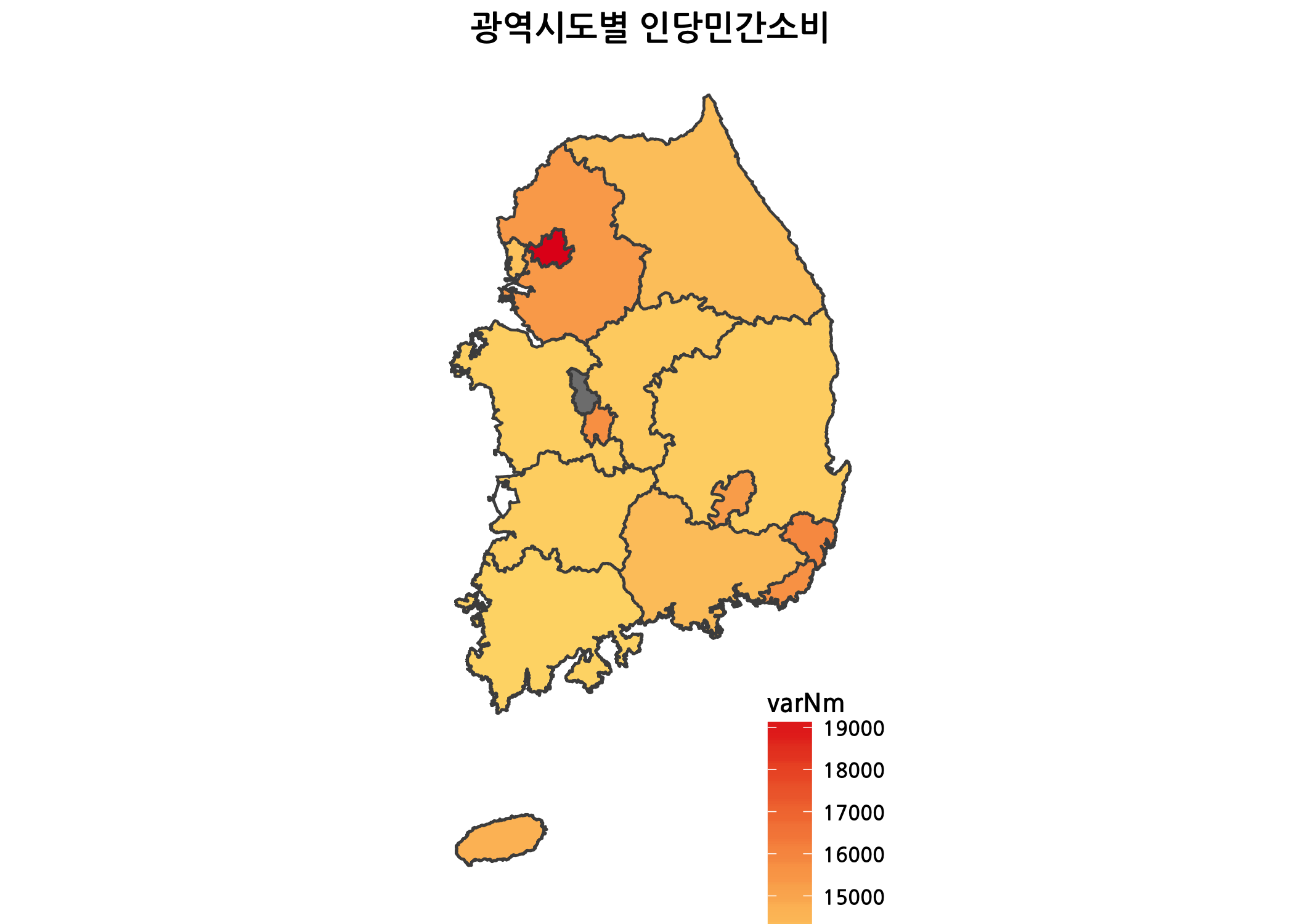
이번 포스팅에서는 우리나라 광역시도 단위 단계구분도를 만들어 보았습니다. 이로써 시각화를 모두 마칩니다.
[1] 객체지향 프로그래밍에 대해 더 자세한 내용이 궁금한 분들은 여러 자료를 찾아보기 바랍니다. 이 블로그도 좋습니다.
[2] 좌표계 변환 함수는 이 블로그를 참고하였습니다.