
R 지도 시각화 2
행정경계구역 데이터 전처리 및 단계구분도 그리기
Dr.Kevin 8/1/2018
지난 포스팅에서 19대 대통령 선거 결과 데이터 정제하는 방법에 대해서 살펴봤습니다. 두 번째 포스팅은 이 데이터로 단계구분도를 그리는 것입니다.
단계구분도를 그리려면 통계청에서 행정경계구역 데이터를 내려받아야 합니다. 이 부분에 대해서도 역시 저의 블로그에 정리해놨으니 살펴보시기 바랍니다.
오늘 소개할 단계구분도는 우리나라 250개 지방자치단체 시/군/구에서 후보자별로 득표율을 시각화한 것입니다. 한 후보에 대해서 그릴 수 있으면 다른 후보 역시 그릴 수 있을 것이므로 이번 포스팅에서는 당시 문재인 후보의 지역별 득표율을 단계구분도로 나타내보겠습니다.
먼저 지난 포스팅에서 RDS로 저장한 데이터를 불러오겠습니다.
# 데이터가 저장된 폴더로 작업경로를 변경합니다.
setwd(dir = 'RDS가 저장된 폴더를 지정하세요')
# RDS 파일을 읽습니다.
result <- readRDS(file = '2017_Presidential_Election_Result.RDS')
행정경계구역 데이터에서 가장 중요한 파일은 shp 확장자로 된 것입니다. 파일명에서 bnd는 boundary를 의미하는 것 같고 sido는 광역시도, sigungu는 시/군/구, 그리고 dong는 법정동을 의미합니다. 그 뒤에 나오는 00은 무슨 의미인지 모르겠습니다. 마지막 2016은 연도입니다.
우리는 시/군/구 단위로 단계구분도를 그릴 것입니다만, 아마 해보시면 알게 되겠으나 광역시도의 shp 파일도 함께 불러와야 합니다. 일단 하나씩 하면서 더 설명을 드리도록 하겠습니다.
# 필요 패키지를 불러옵니다.
library(ggplot2)
library(rgdal)
shp 파일을 불러오려면 rgdal 패키지의 readOGR() 함수를 사용해야 합니다. dsn 인자에는 shp 파일이 저장되어 있는 폴더를 지정하고, layer 인자에는 확장자를 제외한 layer 이름을 할당합니다. 통계청에서 제공하는 데이터는 폴더명과 파일명이 같습니다.
# 단계구분도를 그릴 때 사용할 시/군/구 행정경계구역 데이터를 불러옵니다.
sigg <-
readOGR(
dsn = 'bnd_sigungu_00_2016',
layer = 'bnd_sigungu_00_2016',
encoding = 'CP949')
행경경계구역 데이터를 불러왔으면, ggplot2 패키지의 fortify() 함수를 이용하여 데이터 프레임으로 변환하여 siggDf 객체를 생성합니다. 그리고 id 컬럼을 생성해야 하는데 그 이유는 siggDf에는 지방자치단체명이 없기 때문입니다. 그리고 지방자치단체명은 sigg 객체 중 data라는 요소에 포함되어 있습니다. 따라서 id를 기준으로 병합(merge)할 수 있습니다.
# sigg 객체를 데이터프레임으로 변환합니다.
siggDf <- fortify(model = sigg)
## Regions defined for each Polygons
# sigg@data에서 행번호를 id 컬럼으로 만듭니다.
sigg@data$id <- rownames(x = sigg@data)
# 이제 두 데이터프레임을 병합니다.
siggDf <-
merge(
x = siggDf,
y = sigg@data[, c('id', 'BASE_YEAR', 'SIGUNGU_CD', 'SIGUNGU_NM')],
by = 'id',
all.x = TRUE)
매우 중요한 것을 말씀드립니다. siggDf를 다른 객체와 병합을 했다면 반드시 id와 order 기준으로 오름차순 정렬을 해주어야 합니다. 그렇게 하지 않으면 다각형(polygon)으로 그렸을 때 무시무시한 그림이 그려집니다. ^^
# id와 order 기준으로 오름차순 정렬합니다.
siggDf <- siggDf[order(siggDf$id, siggDf$order), ]
# 미리보기 합니다.
head(x = siggDf, n = 10L)
## id long lat order hole piece group BASE_YEAR SIGUNGU_CD
## 1 0 953683.8 1959210 1 FALSE 1 0.1 2016 11010
## 2 0 953647.3 1959057 2 FALSE 1 0.1 2016 11010
## 3 0 953672.0 1958971 3 FALSE 1 0.1 2016 11010
## 4 0 953780.2 1958977 4 FALSE 1 0.1 2016 11010
## 5 0 953976.8 1958998 5 FALSE 1 0.1 2016 11010
## 6 0 953977.1 1958998 6 FALSE 1 0.1 2016 11010
## 7 0 953994.1 1958990 7 FALSE 1 0.1 2016 11010
## 8 0 954025.5 1958974 8 FALSE 1 0.1 2016 11010
## 9 0 954040.2 1958968 9 FALSE 1 0.1 2016 11010
## 10 0 954074.5 1958954 10 FALSE 1 0.1 2016 11010
## SIGUNGU_NM
## 1 종로구
## 2 종로구
## 3 종로구
## 4 종로구
## 5 종로구
## 6 종로구
## 7 종로구
## 8 종로구
## 9 종로구
## 10 종로구
# 새로 붙인 컬럼들의 이름을 변경합니다.
colnames(x = siggDf)[8:10] <- c('year', 'siggCd', 'siggNm')
미리보기를 통해 알게 되었겠지만 지방자치단체명에는 광역시도명이 없습니다. 그렇기 때문에 광역시도 shp 파일도 따로 불러와야 합니다.
# 광역시도명 코드와 이름을 얻기 위해 시도 행정경계구역 데이터를 불러옵니다.
sido <-
readOGR(
dsn = 'bnd_sido_00_2016',
layer = 'bnd_sido_00_2016',
encoding = 'CP949')
# 광역시도명만 추출합니다.
sidoGb <- sido@data[, c('SIDO_CD', 'SIDO_NM')]
colnames(x = sidoGb) <- c('sidoCd', 'sidoNm')
광역시도 경계 데이터를 불러왔으면 SIDO_CD와 SIDO_NM만 남깁니다. 컬럼명 바꾸는 것은 기호에 따라 하시면 됩니다. 저는 낙타등 방식을 선호하기 때문에 위와 같이 바꿨습니다.
자, 이제 sidoCd에 대응할 코드를 siggDf에서 찾아야 하는데요. 우리나라 정부에서 제공하는 공공데이터를 다뤄본 경험이 있으시면 행정표준코드를 보신 적이 있을 것입니다. 네이버나 지리 데이터에서도 곧잘 나오곤 하는데요. 저는 총 10자리 데이터 중에서 맨 앞 2자리는 광역시도, 다음 2자리는 시/군/구, 그 다음 4자리는 법정동을 의미하는 것으로 알고 있습니다. 따라서 siggDf의 siggCd에서 앞 두자리수를 추출하며 sidoCd라는 새로운 컬럼을 만들어 주어야 합니다. 그리고 나서 이 컬럼을 기준으로 sidoGb 객체와 병합할 수 있습니다.
# siggCd에서 앞 두 글자만 추출하여 광역시도명을 붙입니다.
siggDf$sidoCd <- str_sub(string = siggDf$siggCd, start = 1, end = 2)
# siggDf에 sidoGb를 병합합니다.
siggDf <-
merge(x = siggDf,
y = sidoGb,
by = 'sidoCd',
all.x = TRUE)
# 컬럼 순서를 변경합니다.
siggDf <- siggDf[, c(2:11, 1, 12)]
새로운 데이터와 병합을 했으니 다시 오름차순 정렬해야 합니다! 매우 중요합니다. 왜 중요한지 궁금하신 분은 이 과정을 생략하고 한 번 그려보세요. ^^
# id와 order 기준으로 오름차순 정렬합니다.
siggDf <- siggDf[order(siggDf$id, siggDf$order), ]
이제 선거 결과 데이터 정제할 때 지역명이라는 새로운 컬럼을 만든 것처럼 sidoNm과 siggNm을 합친 areaNm을 새로 만듭니다. 그리고 이제 intersect() 함수를 이용하여 지역명과 정확하게 일치하는 교집합의 원소 개수가 몇 개인지 확인합니다. 만약 250이 나온다면 모든 원소가 정확하게 겹치다는 것을 의미합니다. 참고로 identical() 함수를 사용할 수도 있겠지만 이 경우는 순서까지 같아야 하므로 정렬이 되어 있다면 사용할 수 있습니다.
# sidoNm과 siggNm을 합친 areaNm 컬럼을 생성합니다.
siggDf$areaNm <- str_c(siggDf$sidoNm, siggDf$siggNm, sep = ' ')
# 선거결과 지역명과 경계데이터 areaNm이 서로 같은지 확인합니다.
intersect(x = result$지역명, y = siggDf$areaNm %>% unique() %>% sort()) %>% length()
## [1] 250
결과가 250이므로 이제 다음을 진행합니다.
현재 우리가 다루고 있는 행정경계구역 데이터의 건수는 약 590만 행을 가진 데이터 프레임입니다. 이 데이터로 단계구분도를 그린다고 하면 아마도 개인 노트북이나 데스크탑에서는 그림이 나타나지 않을 것입니다. 그러므로 이 데이터를 크게 줄여주어야 하는데요. 가능한 방법이 여러 가지가 있겠지만 저는 두 가지만 알고 있습니다.
- 순서를 의미하는
order를 줄이고 싶은 규모로 나눈 후 (이번 예제에서는 10) 나머지가 1인 행만 남긴다. - mapshaper webpage에 가서 가지고 있는 shp 파일을 축소시킨 새로운 shp 파일을 내려받는다.
이번 포스팅에서는 첫 번째 방법을 사용하려고 합니다. 두 번째 방법은 추후 알려드리겠습니다. 왜냐하면 현재 우리가 다루고 있는 행정경계구역 데이터는 GRS80 좌표계를 사용하고 있는데, 이 좌표계로는 구글 지도와 함께 사용할 수 없습니다. 그러므로 구글 지도와 같은 좌표계인 WGS84로 변환해주어야 하는데, 첫 번째 방법을 쓰면 leaflet 패키지에서 제대로 구현되지 않습니다.
지금은 무슨 소리인지 잘 이해도 안 되고, 사실 이해할 필요도 없습니다. 아무튼 이 포스팅에서는 두 가지 방법 모두 가능하지만 첫 번째 방법이 더 편리하니 첫 번째 방법을 사용하고, 두 번째 방법은 나중에 알려드리겠습니다.[1]
첫 번째 방법을 사용하여 전체 행을 1/10 규모로 줄입니다. 그리고 부속지역을 제외합니다. 부속지역이란 몸통이 아니라는 것인데요. 예컨데 바닷가를 끼고 있는 지역에는 무수히 많은 섬이 있습니다. 광역시도 행정경계구역 데이터에서 부속지역을 없애면 섬들이 다 날아갑니다. 제주도를 빼놓구요. 시/군/구 데이터에서는 작은 섬들이 다 날아갑니다. 따라서 백령도와 울릉도, 거제도 정도 살아남습니다.
# order를 10으로 나누었을 때 나머지가 1인 행만 남깁니다.
siggDf <- siggDf[siggDf$order %% 10 == 1, ]
# 부속지역을 제외합니다.
siggDf <- subset(x = siggDf, subset = siggDf$piece == 1)
# 건수를 확인합니다.
nrow(x = siggDf)
## [1] 220303
전체 행 수가 22만 건이 되면서 원래 크기보다 약 1/20 규모로 줄었습니다. 이제는 부담없이 단계구분도를 그릴 수 있게 되었습니다. 행정경계구역 데이터 전처리는 이 정도로 마무리 하고 이제 본격적으로 그림을 그리기에 앞서 깔끔한 지도 데이터를 위한 나만의 테마를 theme() 함수로 설정하겠습니다.
아래 코드를 보시면 축을 없애고, 제목을 가운데에 오도록 하고, 범례를 우측 아래로 내려서 수평으로 보이도록 한 것입니다. 범례 부분은 이번 단계구분도를 보로 임의로 정한 것이니 참고하시기 바랍니다.
# 지도를 깔끔하게 정리하기 위해 나만의 테마를 만듭니다.
my_theme <-
theme(
panel.background = element_blank(),
axis.title = element_blank(),
axis.text = element_blank(),
axis.ticks = element_blank(),
plot.title = element_text(hjust = 0.5, face = 'bold'),
legend.direction = 'horizontal',
legend.position = c(0.8, 0.1),
legend.text = element_text(family = 'NanumGothic', size = 8, face = 'bold'),
legend.title = element_text(family = 'NanumGothic', size = 10, face = 'bold')
)
그럼 이제 행경경계구역만 표시되도록 그려보겠습니다. 데이터 사이즈를 크게 줄이긴 했지만 여전히 오래 걸리네요. 참고로 맨 마지막 줄에 있는 coord_fixed()를 추가해야 지도가 지도처럼 보일 것입니다. 그렇지 않으면 Plots 패널 크기에 맞게 지도가 홀쭉하거나 뚱뚱하게 그려질 수 있습니다.
# siggDf 데이터로 지도 이미지를 생성합니다.
ggplot(data = siggDf,
mapping = aes(x = long,
y = lat,
group = group)) +
geom_polygon(fill = 'white',
color = 'black') +
ggtitle(label = '행경경계구역 데이터로 그린 지도') +
my_theme +
coord_fixed()
단계구분도는 지금과 같은 지도에서 시/군/구별로 색상을 다르게 표시한 것입니다. 그러므로 지난 번 포스팅에서 작업한 선거 결과 데이터인 result 객체에서 후보자별 득표율, 최대R 및 색상 컬럼을 siggDf에 병합합니다. siggDf의 areaNm 컬럼과 result의 지역명 컬럼을 기준으로 병합하면 됩니다. 병합 후에는 정렬해주시는 것 잊지 마시구요!
# siggDf에 선거 결과 데이터를 붙입니다.
siggDf <-
merge(x = siggDf,
y = result[, c(1, 22:28)],
by.x = 'areaNm',
by.y = '지역명',
all.x = TRUE)
# id와 order 기준으로 오름차순 정렬합니다.
siggDf <- siggDf[order(siggDf$id, siggDf$order), ]
데이터 준비는 모두 끝났습니다. 이제 마지막으로 단계구분도를 그려보겠습니다. 문재인 후보의 득표율 컬럼인 문재인R을 aes(fill=문재인R)처럼 할당해주면 지역별 득표율에 따라 색상이 다르게 채워질 것입니다. 아래 코드에서 맨 마지막을 보시면 숫자가 낮을수록 흰색에 가깝고, 숫자가 높을수록 빨간색에 가깝게 채워지도록 설정되어 있습니다.
# 나만의 팔레트도 만들어서 적용해보겠습니다.
library(RColorBrewer)
myPal <- brewer.pal(n = 9, name = 'Reds')
# 문재인 후보의 득표율로 단계구분도를 그립니다.
ggplot(data = siggDf,
mapping = aes(x = long,
y = lat,
group = group)) +
geom_polygon(mapping = aes(fill = 문재인R),
color = 'black') +
ggtitle(label = '문재인 후보의 지역별 득표율 현황') +
my_theme +
coord_fixed() +
scale_fill_gradient(low = 'white', high = 'red')
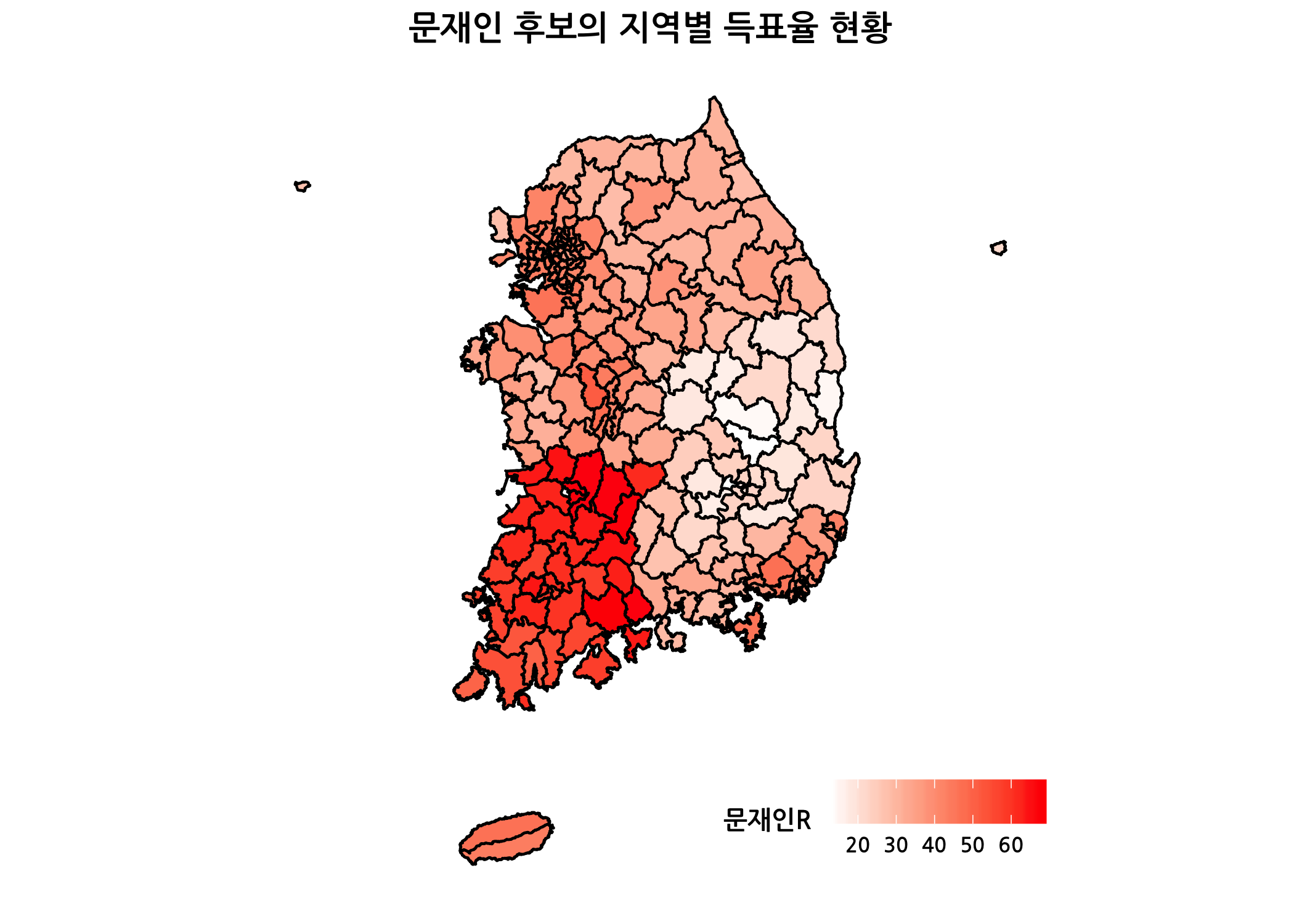
마지막으로 각 지역별로 최대 득표율 후보의 정당 컬러로 채운 단계구분도를 그려보겠습니다. fill 인자에 최대R을 할당하고, 맨 마지막에 추가한 라인을 확인하시기 바랍니다. 현재 최대R이 숫자형 벡터이므로 범주형으로 먼저 변경한 뒤에 단계구분도를 그려보겠습니다.
# `최대R` 컬럼을 범주형으로 변경합니다.
siggDf$최대R <- as.factor(x = siggDf$최대R)
# 각 지역별 최대 득표율 후보의 정당 색상으로 채우기 합니다.
# 더불어민주당은 빨간색, 자유한국당은 파란색입니다.
ggplot(data = siggDf,
mapping = aes(x = long,
y = lat,
group = group)) +
geom_polygon(mapping = aes(fill = 최대R),
color = 'black') +
ggtitle(label = '시군구별 최대 득표 정당 현황') +
my_theme +
coord_fixed() +
scale_fill_manual(labels = c('더불어민주당', '자유한국당'),
values = c('blue', 'red'))
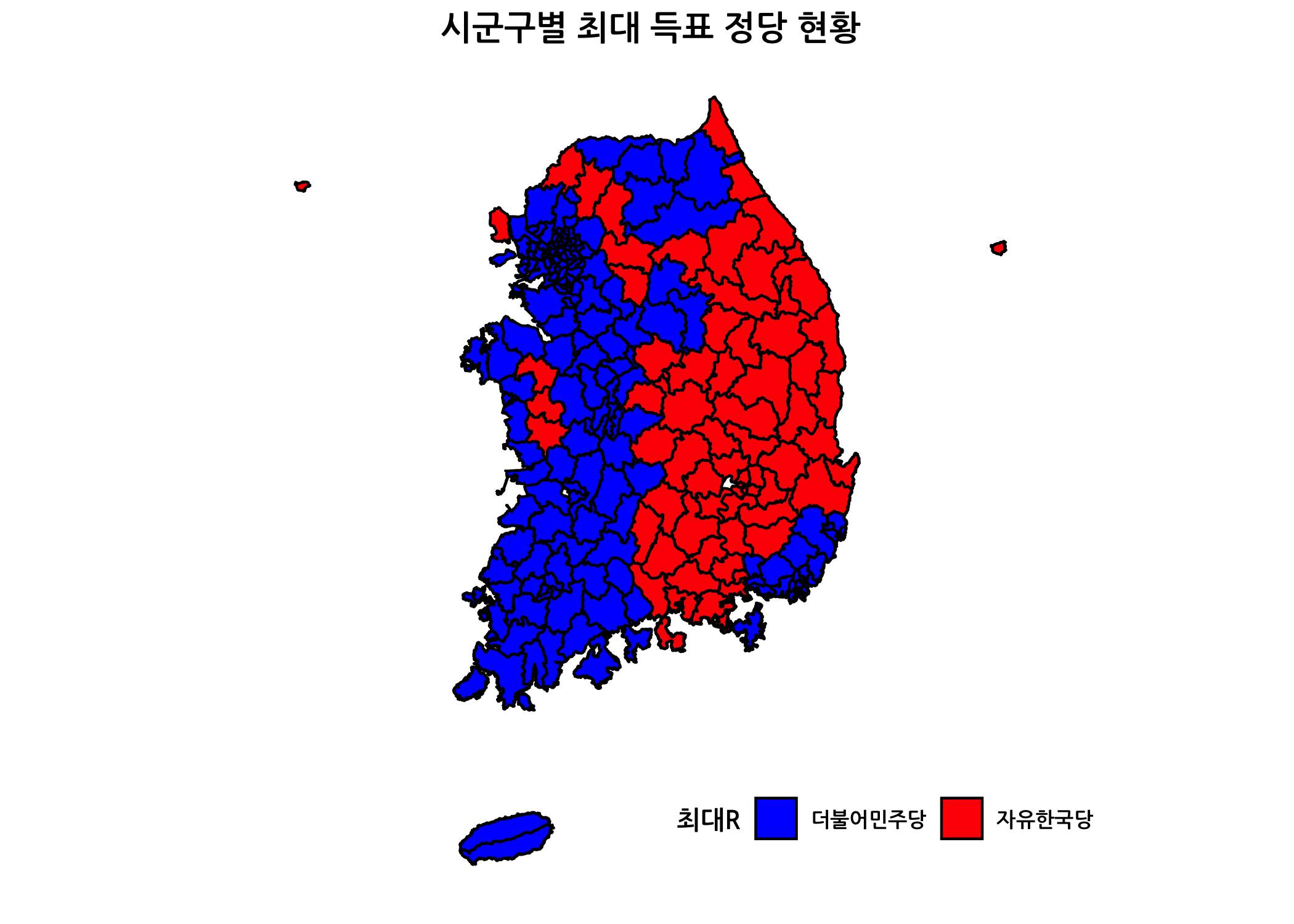
이상으로 행정경계구역 데이터의 전처리 방법과 단계구분도 그리는 방법에 대해서 살펴보았습니다. 다음 포스팅에서는 leaflet 패키지를 활용하여 움직이는 지도 위에 단계구분도를 표현해보도록 하겠습니다.
[1] 사실 두 번째 방법은 문건웅 교수님의 책 웹에서 클릭만으로 하는 R 통계분석 429 ~ 431p에서 설명이 잘 되어 있으니 만약 책이 있으신 분은 그 내용을 참조하시기 바랍니다.