
R Crawler 1
GET 함수로 수집하기
Dr.Kevin 1/18/2018
R을 활용하여 웹데이터를 수집하는 크롤링에 대해서 몇 번에 걸쳐 소개해드리겠습니다. 먼저 우리가 인터넷 페이지를 검색하는 방식을 떠올려봅시다. 괜찮은 이미지가 있어 이걸로 대신하겠습니다.[1]
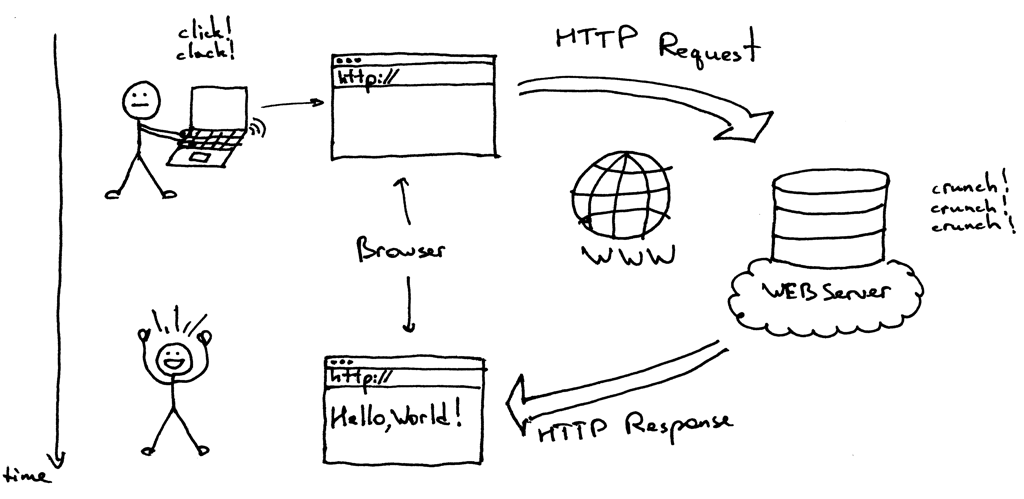
위와 같이 웹브라우저에 url을 입력하는 행위를 통해 HTTP Request를 던지면 웹서버로부터 HTTP Response를 받아 웹브라우저에 HTML을 Rendering 해줍니다. Web Crawler의 기본 과정은 원하는 사이트에 요청을 보내고 응답을 받은 후, html로부터 필요한 데이터를 정리하는 것입니다. 웹페이지를 “요청(Request)”하는 방법으로는 GET, POST 함수 등을 사용할 수 있습니다. 이번에는 GET 함수 사용법을 알아보겠습니다.
# 필요 패키지를 설치합니다.
install.packages(c("httr", "rvest", "dplyr", "magrittr"))
# 필요 패키지를 불러옵니다.
library(httr)
library(rvest)
library(dplyr)
library(magrittr)
html을 가져오는 순서
네이버에서 제공되고 있는 실시간 검색어를 가져오는 간단한 예로 시작을 해보겠습니다.
- 네이버에 접속해서 url을 확인합니다.
- httr 패키지의 GET 함수 인자로 url을 할당해줍니다.
- 위 과정에서 가져온 response의 상태와 html의 구조를 텍스트로 확인합니다.
- 상태를 확인하려면 status_code 함수를 사용합니다. (200이면 정상!)
- html의 구조를 출력하려면 content 함수를 사용합니다.
# 요청하려는 웹페이지 url을 지정합니다.
url <- "https://www.naver.com"
# HTML을 요청(Request) 합니다.
resp <- GET(url)
# HTML을 응답(Response) 상태코드를 확인합니다.
status_code(resp)
## [1] 200
# html을 텍스트 형태로 출력해서 육안으로 확인합니다.
content(x = resp, as = 'text')
상태코드가 200이라 정상적으로 응답(Response) 하였습니다. 그리고 html이 어지럽게 출력이 되었네요. 아래 그림에서 html element의 기본적인 형태를 확인해보겠습니다.[2]

HTML element를 다루는 기본 함수들
- read_html(x, encoding) :
resp에 있는html을 읽습니다. 이 때encoding = "UTF-8"을 추가합니다. - html_node(x, css, xpath) : 괄호 안에 할당된 키워드에 맞는
element중 맨 처음 1개만 가져옵니다. - html_nodes(x, css, xpath) : 위에 해당하는 모든
element들을 가져옵니다. - html_text(x) :
>와<사이에 있는 텍스트만 가져옵니다. - html_table(x) :
html에서table에 속한 데이터를 그대로 가져올 수 있습니다.
우리가 원하는 데이터인 실시간 검색어와 관련된 tag를 확인하는 방법을 알려드리겠습니다. 웹브라우저로 크롬을 사용하신다면 원하는 부분으로 마우스를 옮긴 후, 오른쪽 버튼을 클릭하고 검사(Inspect)를 선택합니다. 그러면 <ul class="ah_l" data-list="1to10" style="display: block;">와 같은 element를 확인할 수 있을 것입니다. 그리고 이 element 아래에 <li class="ah_item" ... >라는 하위 element들이 아래로 붙어있는 것이 보일 겁니다.
html에서 특정 부분을 찾으려면 해당 element에서 xpath나 CSS Selector를 확인한 후, 위에 보여드린 함수의 xpath 또는 css 인자에 할당해주어야 합니다.
- 속성명이
id나class인 경우에는 아래와 같이 기호로 대체할 수 있습니다. id대신#(예,div#post_title)class대신.(예,div.content)
# 응답받은 resp 객체를 html로 읽어옵니다.
html <- read_html(x = resp, encoding = "UTF-8")
# 전체 html 중에서 "실시간 검색어" 관련 element만 추출합니다.
items <- html_nodes(x = html, css = "ul.ah_l li a span.ah_k")
# html을 출력합니다.
print(items)
## {xml_nodeset (40)}
## [1] <span class="ah_k">한채아</span>
## [2] <span class="ah_k">췌장암 초기증상</span>
## [3] <span class="ah_k">차세찌</span>
## [4] <span class="ah_k">수목드라마</span>
## [5] <span class="ah_k">추리의 여왕 시즌2</span>
## [6] <span class="ah_k">위너</span>
## [7] <span class="ah_k">나의 아저씨</span>
## [8] <span class="ah_k">오타니</span>
## [9] <span class="ah_k">라디오스타</span>
## [10] <span class="ah_k">기아타이거즈</span>
## [11] <span class="ah_k">한끼줍쇼</span>
## [12] <span class="ah_k">롤챔스</span>
## [13] <span class="ah_k">청년통장</span>
## [14] <span class="ah_k">kbs온에어</span>
## [15] <span class="ah_k">연금복권</span>
## [16] <span class="ah_k">나의 아저씨 ost</span>
## [17] <span class="ah_k">프로야구</span>
## [18] <span class="ah_k">한화이글스</span>
## [19] <span class="ah_k">유홍준</span>
## [20] <span class="ah_k">리그오브레전드</span>
## ...
# element에서 텍스트만 추출합니다.
searchWords <- html_text(x = items)
# 텍스트를 출력합니다.
print(searchWords)
## [1] "한채아" "췌장암 초기증상" "차세찌"
## [4] "수목드라마" "추리의 여왕 시즌2" "위너"
## [7] "나의 아저씨" "오타니" "라디오스타"
## [10] "기아타이거즈" "한끼줍쇼" "롤챔스"
## [13] "청년통장" "kbs온에어" "연금복권"
## [16] "나의 아저씨 ost" "프로야구" "한화이글스"
## [19] "유홍준" "리그오브레전드" "한채아"
## [22] "췌장암 초기증상" "차세찌" "수목드라마"
## [25] "추리의 여왕 시즌2" "위너" "나의 아저씨"
## [28] "오타니" "라디오스타" "기아타이거즈"
## [31] "한끼줍쇼" "롤챔스" "청년통장"
## [34] "kbs온에어" "연금복권" "나의 아저씨 ost"
## [37] "프로야구" "한화이글스" "유홍준"
## [40] "리그오브레전드"
# 실시간 검색어가 2번 반복되고 있으므로 상위 20개만 추출하여
# 데이터프레임으로 저장합니다.
searchWords <- data.frame(searchWords = searchWords[1:20])
그런데 위와 같이 하는 것보다 dplyr 패키지의 파이프 연산자(%>%)를 사용하면 가독성 높은 코드로 만들 수 있습니다. 파이프 연산자는 앞에서 반환된 객체를 뒤에 오는 함수의 첫 번째 인자로 자동 할당을 해주는 기능을 합니다. 따라서 불필요한 객체들을 만들지 않아도 되는 효과가 있습니다.
# 파이프 연산자를 사용하여 실시간 검색어를 수집한 후
# 데이터프레임으로 저장합니다.
read_html(x = resp, encoding = "UTF-8") %>%
html_nodes(css = "ul.ah_l li a span.ah_k") %>%
html_text() %>%
head(n = 20) %>%
data.frame() %>%
set_colnames("searchWords")
## searchWords
## 1 한채아
## 2 췌장암 초기증상
## 3 차세찌
## 4 수목드라마
## 5 추리의 여왕 시즌2
## 6 위너
## 7 나의 아저씨
## 8 오타니
## 9 라디오스타
## 10 기아타이거즈
## 11 한끼줍쇼
## 12 롤챔스
## 13 청년통장
## 14 kbs온에어
## 15 연금복권
## 16 나의 아저씨 ost
## 17 프로야구
## 18 한화이글스
## 19 유홍준
## 20 리그오브레전드
위 코드에서 마지막에 오는 set_colnames() 함수는 magrittr 패키지에 속합니다. 이 함수를 추가하지 않으면 새로 생성된 데이터 프레임의 열이름에 .으로 설정됩니다.
이상 GET() 함수를 이용하여 네이버 실시간 검색어를 수집하는 방법을 알아보았습니다. 다음 포스팅에서는 url이 바뀌지 않아 원하는 웹페이지로 HTML 요청을 하기 어려울 때 사용하는 POST() 함수에 대해서 알아보겠습니다.