
R Crawler 2
POST 함수로 수집하기
Dr.Kevin 1/19/2018
인터넷에서 페이지를 이동할 때마다 URL이 바뀌는 경험을 하셨을 것입니다. 하지만 그렇지 않은 웹페이지도 많습니다. URL은 uniform resource locator의 머릿글자로 웹페이지의 주소라고 할 수 있습니다. 그렇기에 GET 함수로 수집하기에서는 HTTP Request할 때 URL만으로도 가능했습니다.
이번에는 화면이 바뀌어도 URL이 고정되어 있는 사이트의 정보를 수집할 때 POST() 함수를 이용하는 방법을 알아보도록 하겠습니다. 패키지는 지난 번과 동일하게 불러오기 하면 됩니다.
# 필요 패키지를 불러옵니다.
library(httr)
library(rvest)
library(dplyr)
library(magrittr)
이번에 한국 전화번호부(http://www.isuperpage.co.kr) 웹페이지에서 추천맛집 주소와 전화번호를 수집하는 예제를 실행해보도록 하겠습니다. 웹페이지에 들어가서 원하는 조건을 선택해봐도 URL이 바뀌지 않는 것을 알 수 있습니다. 이럴 때 GET() 함수로 웹페이지를 가져와도 메인 페이지의 html만 수집될 것입니다.
메인페이지 중앙에 있는 업종 메뉴에서 음식/주점 > 추천맛집을 선택한 후, 우측 상단에 있는 지역 선택 메뉴에서 여의도동을 입력하면 서울 영등포구 여의도동이 선택됩니다. 이 상태에서 10개의 추천맛집 리스트가 노출되는 것을 확인할 수 있습니다.
화면 아무 곳에서나 오른쪽 클릭을 한 후 검사(Inspect)를 선택하면 개발자도구가 열립니다. 개발자도구 맨 상단 메뉴 중 Network로 이동합니다.
그 상태에서 개발자도구 왼쪽 상단에서 clear와 recording network log를 클릭합니다. clear는 빈 원에 직선이 사선으로 그어저 있는 모양이고, recording network log는 회색의 원 모양입니다. recording 중일 때 빨간색으로 바뀝니다.
이제 새로고침(F5) 합니다. 그러면 뭔가 바쁘게 움직이는 걸 볼 수 있습니다. 하단에 새로 생긴 목록에서 맨 처음 나오는 search.asp에 주목합니다.
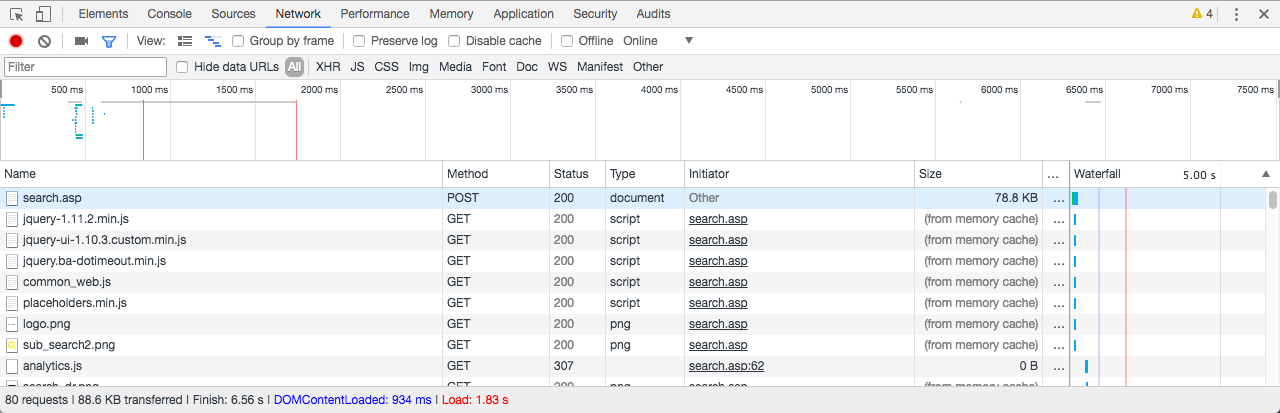
search.asp을 클릭하면 우측에 새로운 화면이 열리는데 요청과 응답에 필요한 정보들을 확인할 수 있습니다.
- Request URL은 POST 함수에 할당할 URL입니다.
- Request Method는
POST로 되어 있으니 POST 방식으로 요청을 해야 합니다. - Status Code는
200으로 정상입니다.
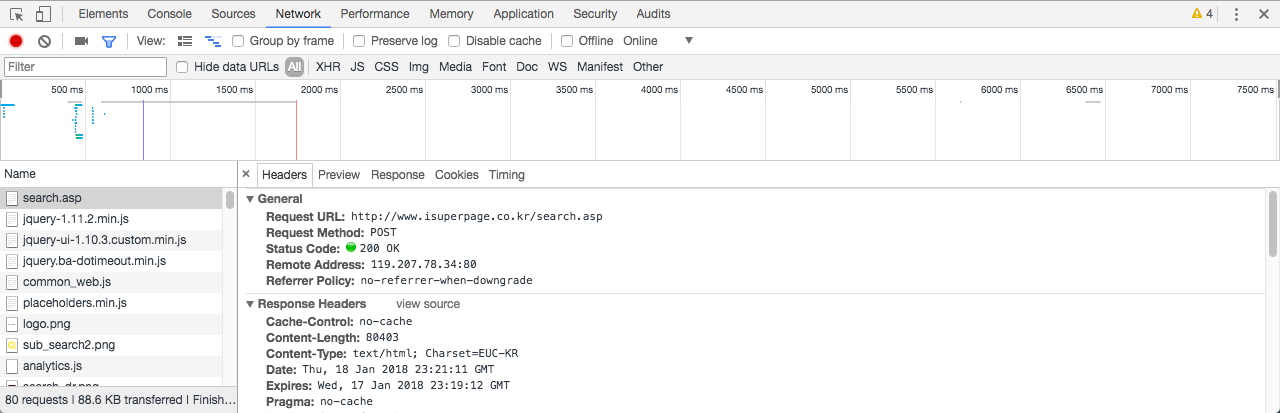
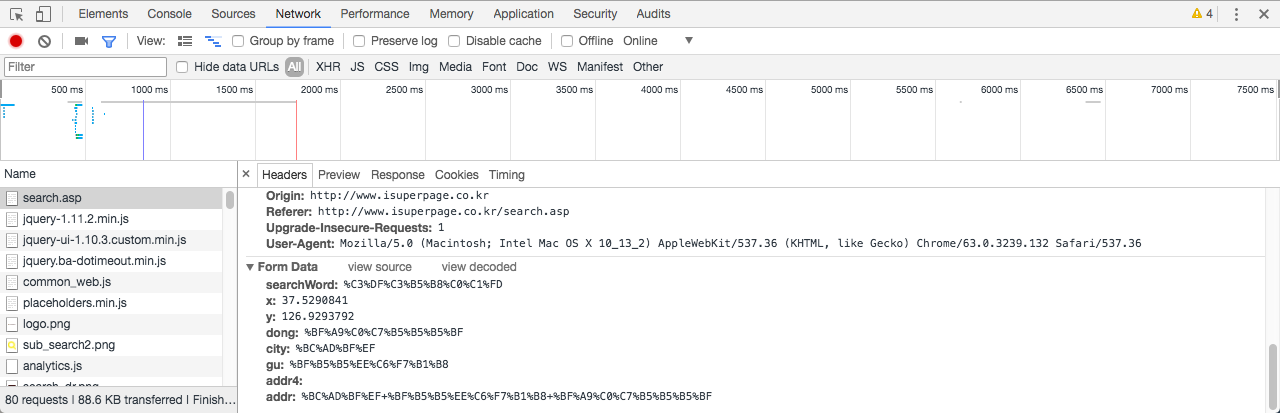
맨 아래로 이동하여 Form Data를 확인합니다. POST() 함수로 웹페이지 정보를 수집할 때 Form Data를 리스트의 인자로 할당하기 때문에 이 정보들이 필요합니다.
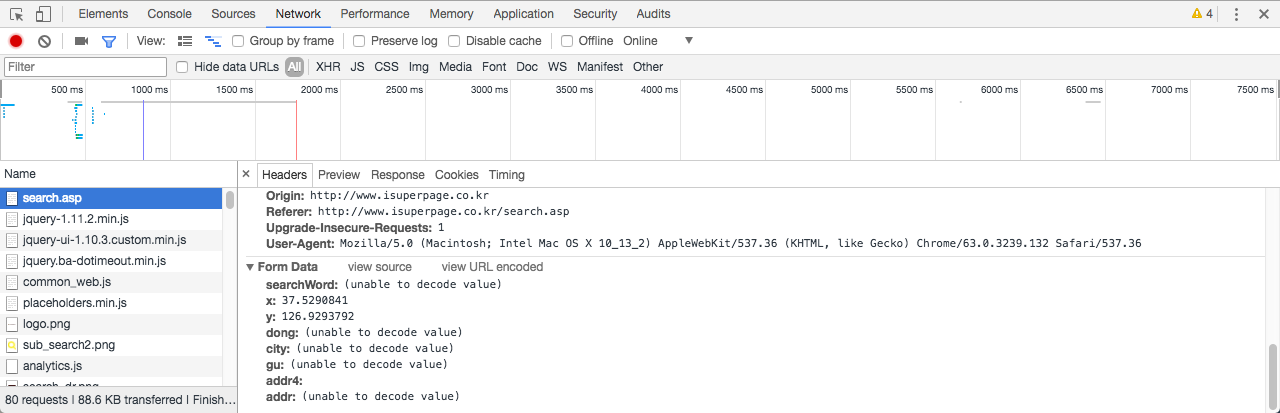
그런데 한 가지 복병이 생겼습니다! Form Data에 일부 항목값이 (unable to decode value)로 되어 있습니다. 기계가 문자를 인식하게 하기 위해 부호화(Percent-Encoding) 해준 것을 사람이 이해할 수 있도록 복호화(Percent-Decoding) 해주어야 하는데, 현재 상태로는 그렇게 되지 않는 것으로 보입니다. Form Data 오른쪽 끝에 view URL encoded를 클릭하면 아래 그림처럼 알기 어려운 문자들이 보입니다. 즉, 기계가 문자를 인식할 수 있는 (%-인코딩 된) 상태인 것입니다.
여기서 한 가지 문제가 더 있는데요. (%-인코딩은 일단 잊어버리고) 각 언어마다 기계가 인식할 수 있도록 인코딩하는 방식이 제각각이었고, 이를 통일하기 위해 국제표준이라 할 수 있는 UTF-8이 개발되었습니다. 웹페이지를 개발할 때 인코딩 방식으로 UTF-8을 쓰면 좋은데, 한국은 윈도우즈가 많이 사용되어서 그런지 윈도우즈에서 개발한 EUC-KR 또는 CP949를 사용하는 경우가 많습니다.
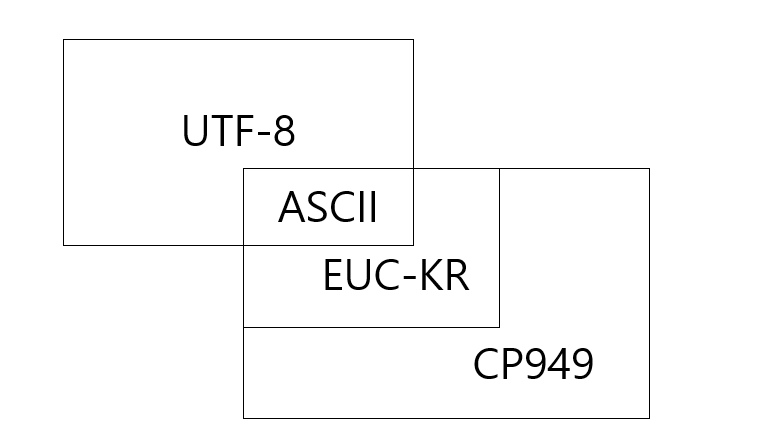
위 그림에서 보면 EUC-KR은 CP949에 포함되는 부분집합임을 알 수 있으며, UTF-8과 교집합으로 ASCII가 있습니다. ASCII는 미국에서 알파벳과 숫자 및 주요 기호들을 1 byte로 표현한 것입니다. 따라서 어떤 인코딩 방식을 사용해도 영문과 숫자, 기호들은 멀쩡하게 보이는 것입니다.
이번 예제에서 우리가 수집하려고 하는 웹페이지도 EUC-KR 방식을 사용하고 있습니다. 우리는 RStudio의 Global Options에서 기본 인코딩을 UTF-8으로 설정한 바 있습니다. 현재 R 환경에서 문자열을 인식하는 인코딩 방식을 확인해보겠습니다.
# 인코딩 방식을 확인합니다.
localeToCharset()
## [1] "UTF-8"
결과가 UTF-8로 나왔습니다.
그럼 특정 문자열의 인코딩 방식을 확인해보겠습니다. Encoding("문자열") 함수를 이용합니다.
# 문자열의 인코딩 방식을 확인합니다.
Encoding("추천맛집")
## [1] "unknown"
다행하게도 unknown으로 확인되었습니다. 하지만 앞에서 localeToCharset 함수로 확인한 값이 “UTF-8”이었으므로 이 문자열의 인코딩도 “UTF-8”으로 인식될 것입니다.
문제는 웹페이지가 EUC-KR 방식을 사용하고 있으므로 POST 함수의 인자로 한글을 입력할 때 EUC-KR 또는 CP949로 되어 있어야 한다는 것입니다. 특정 문자열의 인코딩 변경은 iconv 함수를 사용합니다.
# 문자열의 인코딩 방식을 변환합니다.
iconv(x = "추천맛집", from = "UTF-8", to = "CP949")
## [1] "\xc3\xdfõ\xb8\xc0\xc1\xfd"
인코딩을 변경하니 괴상한 문자들이 출력되었습니다. 아무튼 이 웹페이지에 한글을 인식시키려면 인코딩을 CP949로 바꿔준 다음 POST 함수의 body 인자에 할당해주면 됩니다.
이제 드디어 POST 함수를 등장시켜 보겠습니다. 먼저 URL과 위에서 확인한 Form Data의 값들을 다음과 같이 설정해보겠습니다.
# 웹사이트 url을 지정합니다.
url <- "http://www.isuperpage.co.kr/search.asp"
# POST 인자를 지정합니다.
keyword <- iconv(x = "추천맛집", from = "UTF-8", to = "CP949")
sido <- iconv(x = "서울", from = "UTF-8", to = "CP949")
gugn <- iconv(x = "영등포구", from = "UTF-8", to = "CP949")
dong <- iconv(x = "여의도동", from = "UTF-8", to = "CP949")
위에서 설정한 값들을 이용하여 웹페이지를 가져오겠습니다. POST 함수의 인자 중 body는 리스트 형태를 가져야 하며, 리스트의 인자명은 Form Data에서 사용된 것과 동일하게 설정해주어야 합니다. 이 때, 각각의 인자에 I 함수를 적용해주어야 제대로 작동합니다.
I 함수는 이중 인코딩(double encoding)을 막기 위해 사용하는 것인데요. httr 패키지는 문자열에 대해 %-인코딩(또는 escape이라고도 함) 처리를 자동으로 해줍니다. 문제는 타겟 웹사이트가 EUC-KR 인코딩 방식을 사용하는 경우, POST()의 인자값으로 문자열을 할당하면 제대로 인식하지 못하고 결국 사용자가 원하는 웹데이터를 응답받지 못합니다. 반면에, 웹페이지가 UTF-8 방식을 사용하고 있으면 I 함수를 사용하지 않아도 된다고 합니다. (도움을 주신 분들께 감사드립니다. ^^)
# html를 요청합니다.
resp <- POST(url = url,
encode = "form",
body = list(searchWord = I(keyword),
city = I(sido),
gu = I(gugn),
dong = I(dong)
)
)
resp의 응답 상태코드를 확인해보겠습니다. 200이면 정상입니다.
# 응답 상태코드를 확인합니다.
status_code(resp)
## [1] 200
이제 html로부터 원하는 데이터를 정리하는 작업이 남았습니다. 웹브라우저에서 상호명에 마우스를 가져다 놓고 오른쪽 클릭 후 검사(Inspect)를 선택하여 식당 정보가 반복되는 구조를 찾습니다.
<dif id="search_resutl>의 하위 element로 <div class="tit_list">와 <div class="l_cont">를 정리하면 원하는 데이터를 얻을 수 있을 것 같습니다. 먼저 상호명만 따로 추출하여 10개의 길이를 가진 문자 벡터로 만들어 보겠습니다.
# 상호명을 추출합니다.
shopn <- resp %>%
read_html(encoding = "EUC-KR") %>%
html_nodes(css = "div#search_result ol li div.tit_list") %>%
html_text()
print(shopn)
## [1] "마실 갈치조림추천맛집"
## [2] "성민촌추천맛집"
## [3] "한양곰치국추천맛집"
## [4] "제주나라추천맛집"
## [5] "다인생굴 모둠꼬치 메로된장구이추천맛집"
## [6] "다인추천맛집"
## [7] "자린고비추천맛집"
## [8] "믹스앤베이크추천맛집"
## [9] "한양생태집추천맛집"
## [10] "백합구이 해물추천맛집"
모든 상호명 뒤에 공통적으로 추천맛집이라는 문자열이 추가되어 있습니다. stringr 패키지의 str_replace() 함수를 사용하여 삭제하도록 하겠습니다.
# 필요 패키지를 불러옵니다.
library(stringr)
# 상호명 추출하고 불필요한 문자열 삭제합니다.
shopn <- resp %>%
read_html(encoding = "EUC-KR") %>%
html_nodes(css = "div#search_result ol li div.tit_list") %>%
html_text() %>%
str_replace(pattern = "추천맛집", replacement = "")
print(shopn)
## [1] "마실 갈치조림" "성민촌"
## [3] "한양곰치국" "제주나라"
## [5] "다인생굴 모둠꼬치 메로된장구이" "다인"
## [7] "자린고비" "믹스앤베이크"
## [9] "한양생태집" "백합구이 해물"
다음으로 전화번호, 지번주소, 도로명주소를 수집해보겠습니다. 최종 텍스트 앞뒤로 공백이 생길 수 있으므로 이번에는 stringr 패키지의 str_trim() 함수를 사용하도록 하겠습니다.
# 기타 정보를 추출합니다.
sInfo <- resp %>%
read_html(encoding = "EUC-KR") %>%
html_nodes(css = "div#search_result ol li div.l_cont span") %>%
html_text() %>%
str_trim()
print(sInfo)
## [1] "02-783-6210" "서울 영등포구 여의도동 13-25"
## [3] "" "서울 영등포구 은행로 29"
## [5] "02-369-7077" "서울 영등포구 여의도동 13-6"
## [7] "" "서울 영등포구 국회대로76길 22"
## [9] "02-780-7894" "서울 영등포구 여의도동 14-31"
## [11] "" "서울 영등포구 국회대로70길 18"
## [13] "02-780-3210" "서울 영등포구 여의도동 14-32"
## [15] "" "서울 영등포구 국회대로68길 23"
## [17] "02-761-9288" "서울 영등포구 여의도동 21-3"
## [19] "" "서울 영등포구 여의나루로 117"
## [21] "070-761-9288" "서울 영등포구 여의도동 21-3"
## [23] "" "서울 영등포구 여의나루로 117"
## [25] "02-786-8307" "서울 영등포구 여의도동 23-8"
## [27] "" "서울 영등포구 국제금융로2길 32"
## [29] "02-780-1252" "서울 영등포구 여의도동 24"
## [31] "" "서울 영등포구 국제금융로2길 7"
## [33] "02-780-5577" "서울 영등포구 여의도동 35-5"
## [35] "" "서울 영등포구 여의나루로 42"
## [37] "02-782-3550" "서울 영등포구 여의도동 36-2"
## [39] "" "서울 영등포구 국제금융로6길 33"
sInfo는 10개 상호에 해당하는 정보가 반복되고 있음을 알 수 있습니다. 따라서 데이터의 위치에 따라 다음과 같이 추출하도록 합니다.
- 전화번호 : 1, 5, 9와 같이 4로 나누어 나머지가 1인 위치에 있는 데이터
- 지번주소 : 2, 6, 10과 같이 4로 나누어 나머지가 2인 위치에 있는 데이터
- 도로명주소 : 4, 8, 12와 같이 4로 나누어 나머지가 0인 위치에 있는 데이터
# 기타 정보 벡터로 정리합니다.
phone <- sInfo[(0:9) * 4 + 1]
jibun <- sInfo[(0:9) * 4 + 2]
roadn <- sInfo[(0:9) * 4 + 4]
마지막으로 지금까지 수집한 벡터들로 데이터프레임을 만듭니다.
# 최종 데이터프레임을 생성합니다.
result <- data.frame(shopn = shopn,
phone = phone,
jibun = jibun,
roadn = roadn)
print(result)
## shopn phone
## 1 마실 갈치조림 02-783-6210
## 2 성민촌 02-369-7077
## 3 한양곰치국 02-780-7894
## 4 제주나라 02-780-3210
## 5 다인생굴 모둠꼬치 메로된장구이 02-761-9288
## 6 다인 070-761-9288
## 7 자린고비 02-786-8307
## 8 믹스앤베이크 02-780-1252
## 9 한양생태집 02-780-5577
## 10 백합구이 해물 02-782-3550
## jibun roadn
## 1 서울 영등포구 여의도동 13-25 서울 영등포구 은행로 29
## 2 서울 영등포구 여의도동 13-6 서울 영등포구 국회대로76길 22
## 3 서울 영등포구 여의도동 14-31 서울 영등포구 국회대로70길 18
## 4 서울 영등포구 여의도동 14-32 서울 영등포구 국회대로68길 23
## 5 서울 영등포구 여의도동 21-3 서울 영등포구 여의나루로 117
## 6 서울 영등포구 여의도동 21-3 서울 영등포구 여의나루로 117
## 7 서울 영등포구 여의도동 23-8 서울 영등포구 국제금융로2길 32
## 8 서울 영등포구 여의도동 24 서울 영등포구 국제금융로2길 7
## 9 서울 영등포구 여의도동 35-5 서울 영등포구 여의나루로 42
## 10 서울 영등포구 여의도동 36-2 서울 영등포구 국제금융로6길 33
이상으로 POST() 함수를 이용하여 웹데이터를 수집하는 방법을 알아보았습니다. 이번 포스팅에서는 1페이지에 출력된 웹데이터 수집만 소개해드렸는데요. 조회 조건에 맞는 데이터가 많아서 2페이지로 넘어가는 경우, 모든 데이터를 수집하는 방법은 페이지 네비게이션 활용하기 포스팅을 참조하시기 바랍니다.
다음에는 User-agent를 추가하여 웹크롤러가 아닌 사람이 요청(Request)하는 것처럼 보이는 방법에 대해서 간단하게 알아보겠습니다.
[1] 참조 : http://jtoday.tistory.com/88