
R Crawler 6
Open API 데이터 수집하기
Dr.Kevin 2/1/2018
API는 Application Programming Interface의 머릿글자로 응용프로그램 프로그래밍 인터페이스라고 할 수 있는데요. 저도 전문적인 것은 모릅니다. 다만 제가 사용하는 방식으로 설명을 대신하면 다음과 같습니다.
사용자인 제가 API 서비스 제공자인 공공데이터 포털에게 원하는 데이터를 요청(Request)하고 응답(Response)받는 방식으로 해당 데이터를 XML 또는 JSON 형태로 제공받는 것입니다. 그리고 Open API는 서비스를 신청하는 모든 사람에게 열려있다는 의미입니다. 사용자가 어떤 데이터에 대해 활용신청을 하면 API 서비스 제공자는 인증키를 발급해주어야 하고, 나중에 사용자가 해당 서비스를 요청하려면 발급받은 인증키를 요청 URL에 포함시켜야 하는 거죠.
Open API가 무료라고 해도 일별 호출수를 제한하는 경우가 일반적이고, 일별 호출수 한도를 초과하여 사용하려는 사용자에게 과금하는 경우도 있습니다. 우리나라 정부는 공공데이터 포털을 통해 정부기관에서 보유하고 있는 공공데이터를 무료로 공개하고 있습니다. 물론 일별 호출수 한도가 있구요.
현재 공공데이터 포털에서 데이터를 제공하는 형태는 크게 2가지로, 파일데이터와 Open API가 있습니다. 파일데이터는 우리에게 아주 익숙한 형태(예컨데, xlsx 또는 csv 파일)로 다운로드 받을 수 있게 한 것입니다. 하지만 Open API를 이용하면 한 번에 많은 파일을 다운로드하고 다시 R에서 읽어오는 등의 수작업을 반자동화할 수 있습니다.
이미 언급한 바와 같이 공공데이터 Open API를 사용하려면 미리 활용신청을 해야 합니다. 이번 포스트에서는 조달청 나라장터 낙찰정보에 대한 Open API 인증키를 받고 원하는 데이터를 수집하는 방법에 대해서 소개하겠습니다.
공공데이터 포털 인증키 발급받기
인증키 발급방법을 아래와 같이 몇 장의 화면 캡쳐 이미지로 설명을 하겠습니다. 먼저 공공데이터 포털에 접속하여 회원가입을 하고 로그인까지 합니다.
- 공공데이터 포털 메인화면 상단 검색창에 나라장터를 입력합니다.

- 검색 결과에서 검색창 바로 아래 전체, 파일데이터, 오픈API, 표준데이터 메뉴가 보일 것입니다. 이 중에서 오픈API를 선택하고 아래 목록에서 조달청_낙찰정보를 클릭합니다.

- 조달청_낙찰정보 상세화면이 열리면 아래 그림에서 보이는 것처럼 활용신청을 클릭합니다.
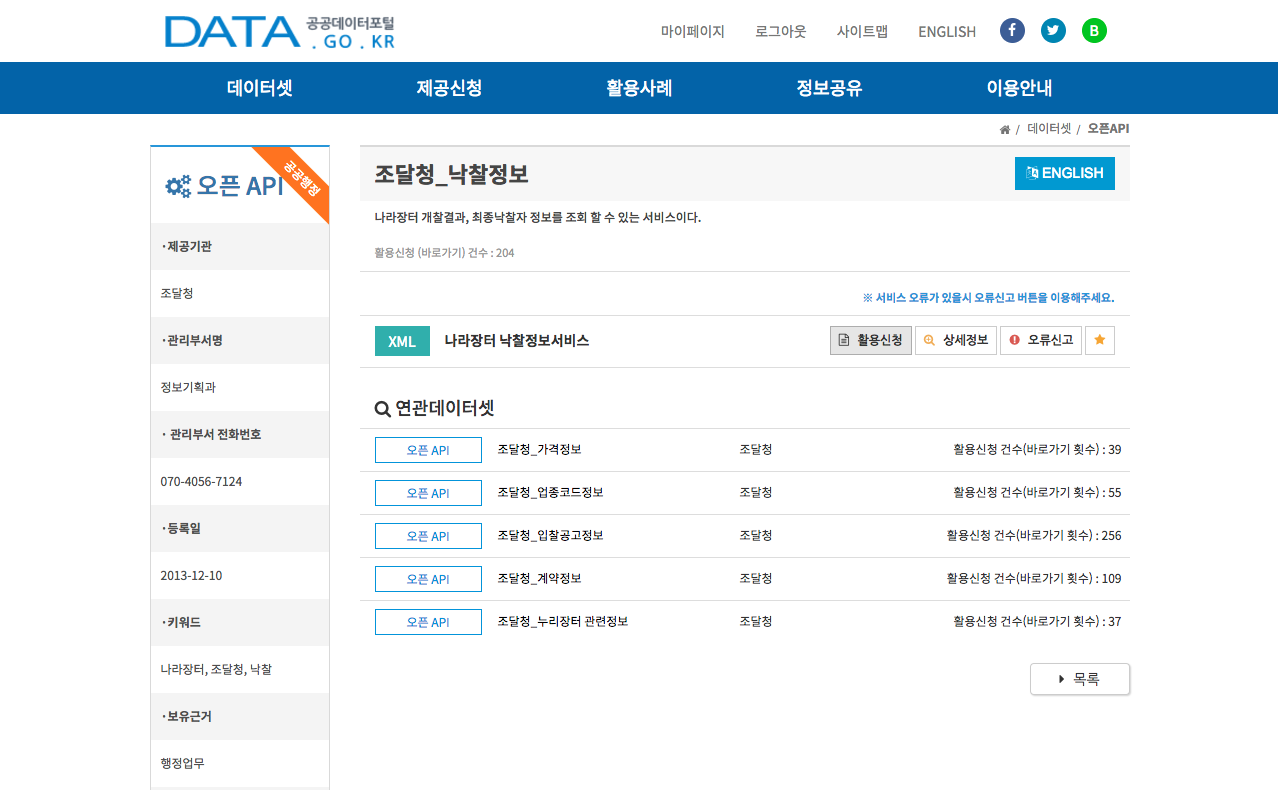
- 개발계정 신청화면으로 이동하면, 나머지 항목은 그대로 둔 채 화면 아래쪽에 있는 상세기능정보로 이동하여 상세기능 중 필요한 항목을 선택합니다. 모두 선택해도 됩니다.
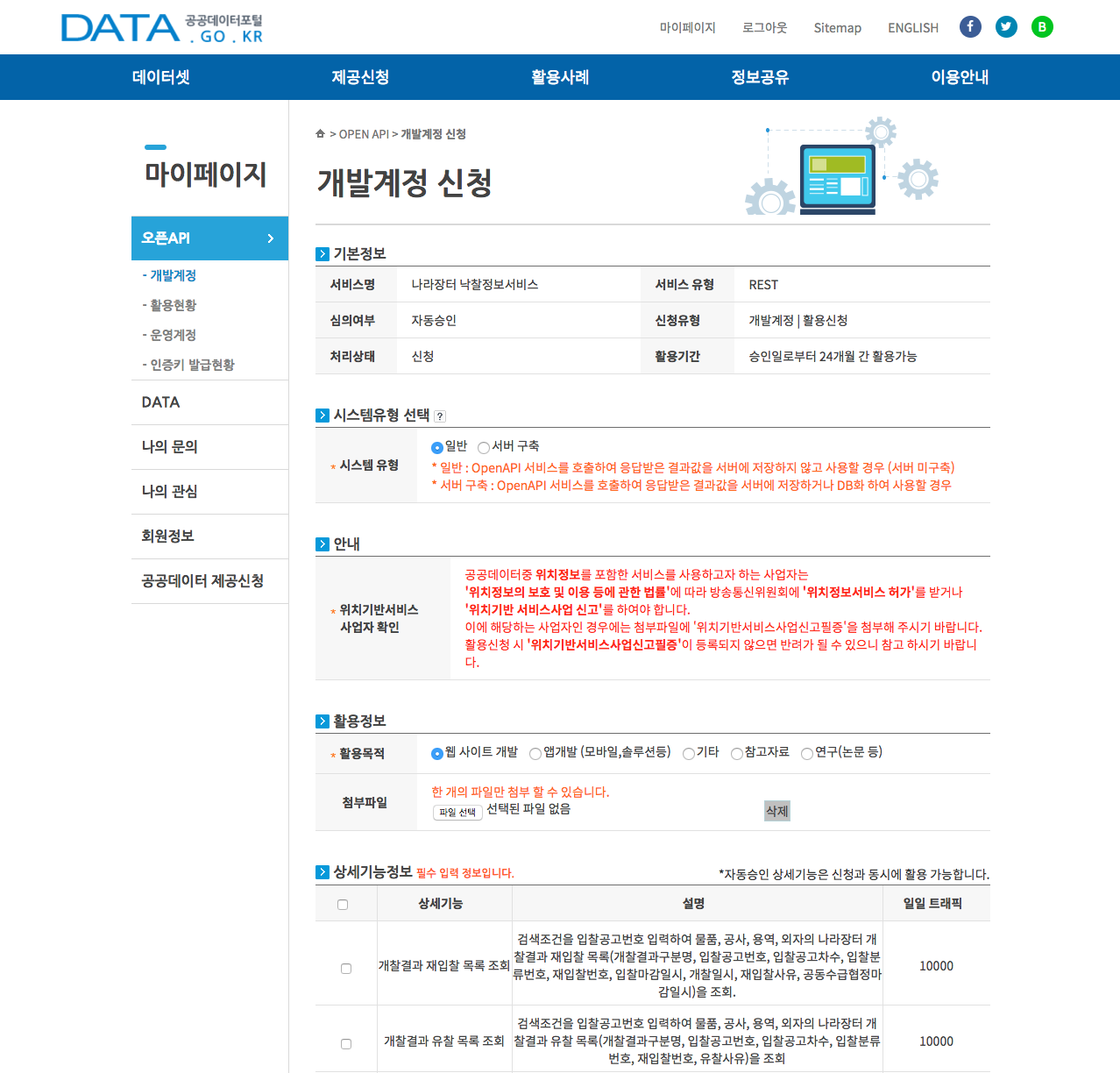
- 상세기능을 다 선택했다면 라이센스표시에서 동의합니다를 선택한 후, 신청버튼을 클릭합니다.
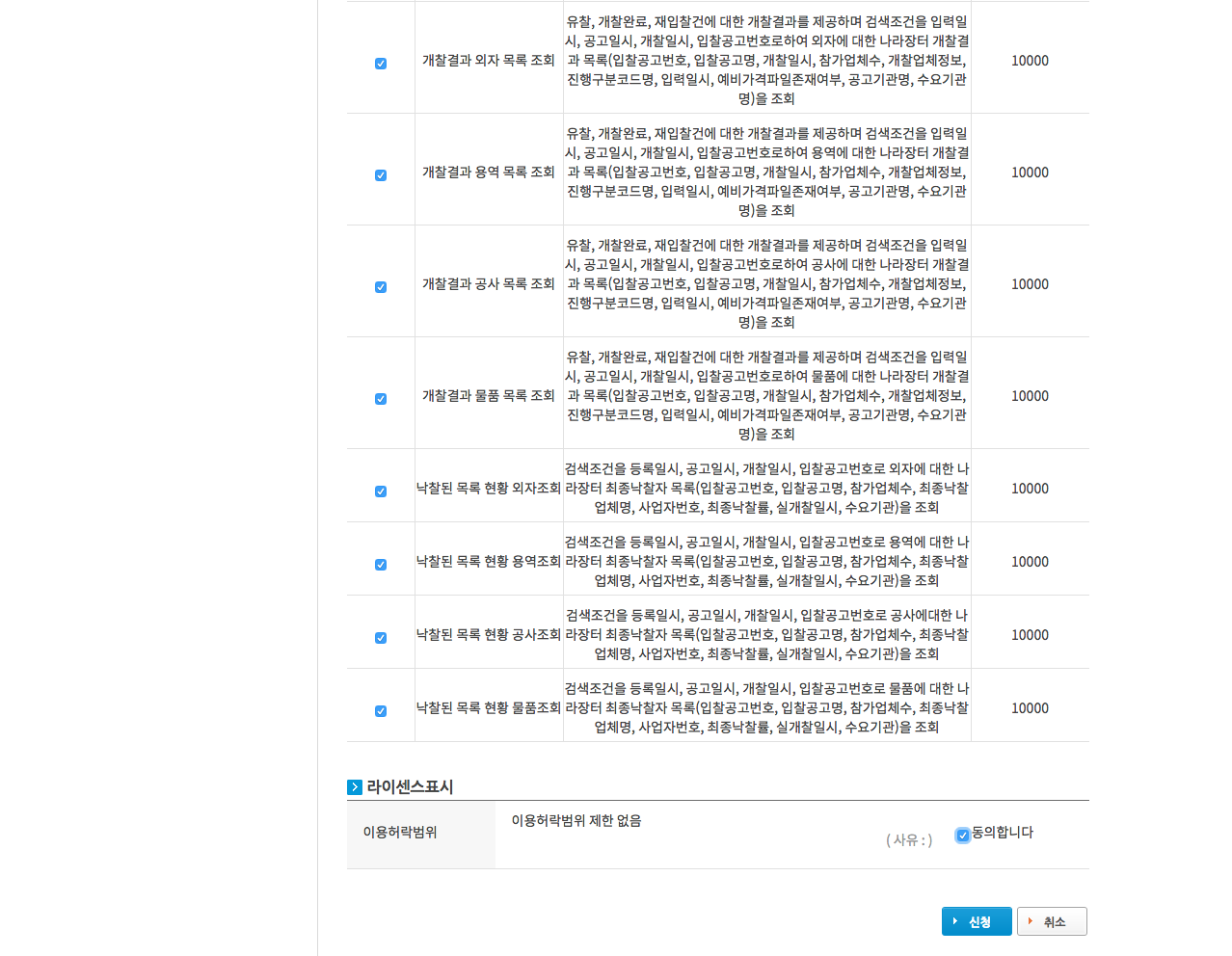
- 위 과정을 모두 거치면 아래 이미지와 같이 개발계정 신청이 완료됩니다. 웹페이지 가운데에 확인창을 클릭하면 마이페이지 > 개발계정 화면으로 이동하여 (이미 승인받은 다른 항목이 있다면) 승인받은 목록을 한 번에 확인할 수 있습니다.
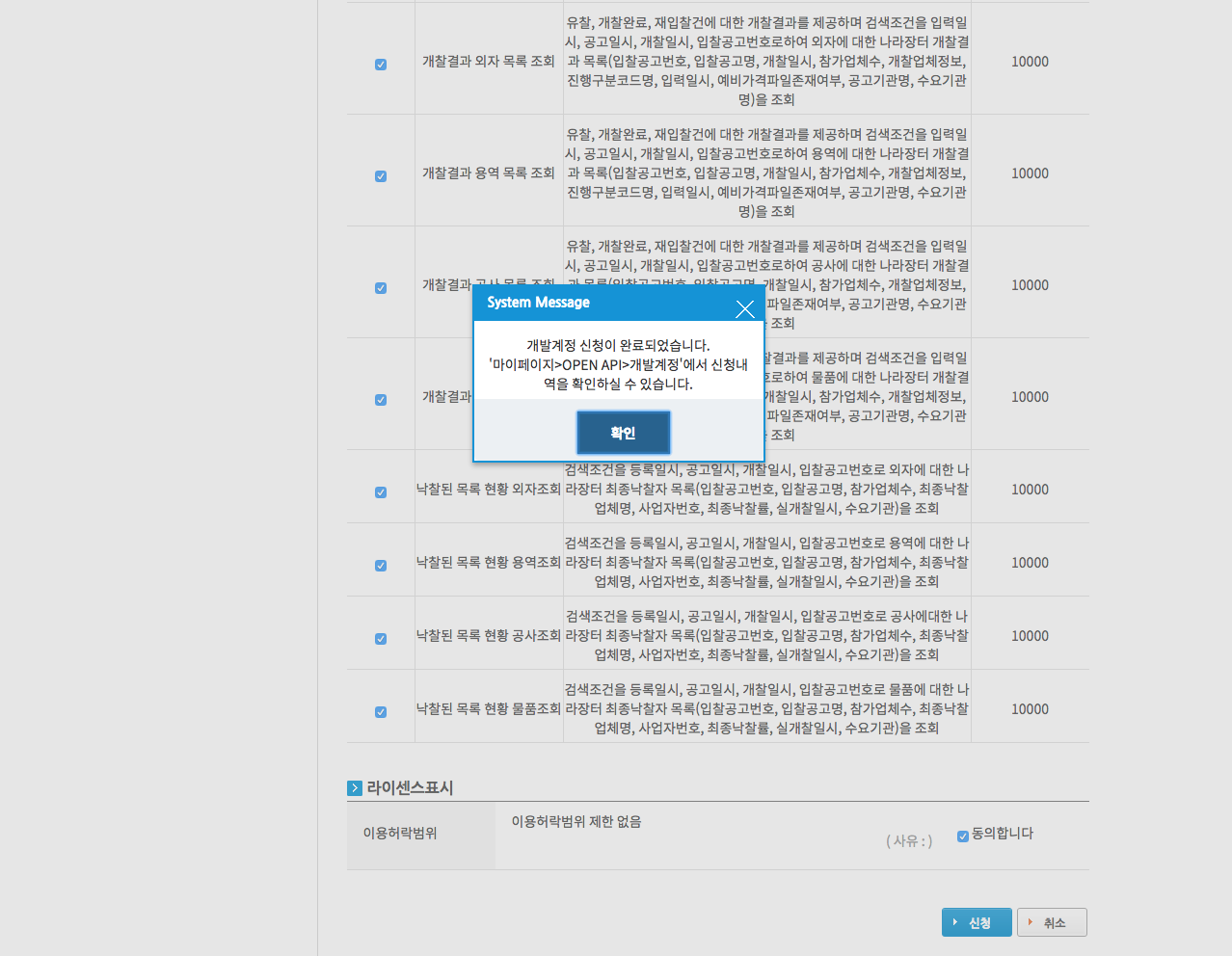
- 마이페이지 > 개발계정에서 방금 신청한 나라장터 낙찰정보서비스를 클릭하면 개발계정 상세보기 화면으로 이동하는데, 여기에서 인증키를 확인할 수 있습니다. 나중에 데이터를 요청할 때 사용해야 하므로 복사한 다음 R에서 적당한 객체명을 붙여 할당해놓습니다.
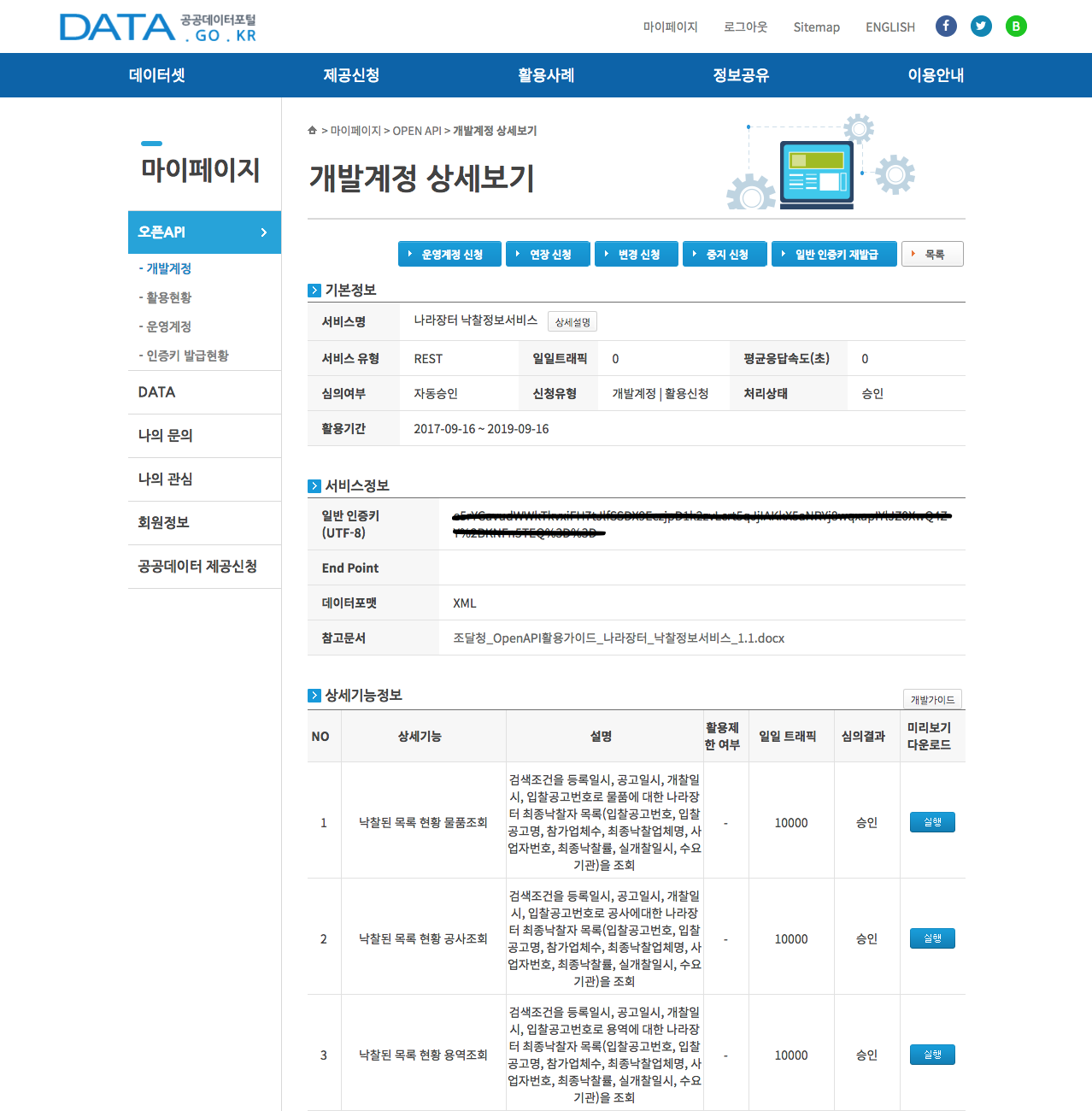
한 가지 중요한 것은, 위 이미지에서 참고문서를 잘 읽어봐야 한다는 것입니다. 일단은 적당한 폴더에 저장합니다. 나중에 따로 설명하도록 하겠습니다.
이상으로 공공데이터 포털 Open API 신청하는 것을 소개했습니다. 다른 데이터 항목들에 대해서는 인증키 신청방법이 같으니 필요한 항목은 미리미리 신청하시기 바랍니다.
조달청 나라장터 낙찰리스트 수집하기
바로 위에서 언급한 참고문서인 조달청_OpenAPI활용가이드_나라장터_낙찰정보서비스_1.1.docx를 엽니다. 4페이지 아래 표를 보면, 나라장터 낙찰 정보서비스에서 물품, 공사, 용역, 외자 등의 항목에 대해 조회할 수 있다는 것을 알 수 있습니다. 이 표에 있는 오퍼레이션은 서비스 요청할 때 사용됩니다.
6~12페이지에 걸쳐 낙찰된 목록 현황 물품조회에 대한 오퍼레이션 명세를 확인할 수 있습니다. 간단하게 설명하자면 요청 메시지 명세 테이블에 있는 항목을 조합하여 서비스 요청을 하면 정상적으로 응답을 받게 될 경우, 응답 메시지 명세 테이블에 있는 항목을 받을 수 있다는 것입니다. 응답 데이터 형태는 XML이며, HTML처럼 처리하면 됩니다. 하지만 rvest 패키지의 read_xml() 함수와 xml_nodes() 함수 등을 이용해서 처리한다는 점에서 기존 방식과 다릅니다. 그리고 tag의 인자명에 대해 대소문자 구분을 합니다. 반면에, read_html() 함수는 tag의 인자명에 대해 대소문자 구분을 하지 않는다는 차이도 있습니다.
예시를 보면 더욱 쉽게 이해할 수 있습니다. 11페이지 요청 / 응답 메시지 예제를 보시기 바랍니다. 웹크롤링을 할 때 GET() 함수의 인자로 url을 넣어서 요청을 하는데, Open API를 이용할 때에도 URL을 조합하여 요청하면 됩니다. URL의 요소로는 앞에서 언급한 요청 메시지 명세를 참고하면 되구요. 요청이 정상적으로 처리되면 응답 메시지 명세에서 보이는 형태의 데이터를 받을 수 있습니다. 이 XML을 우리가 알고 있는 rvest 함수들로 정리해주면 끝입니다.
백문이 불여일견이고, 백견이 불여일각이며, 백각이 불여일행[1]이니, 지금부터 Open API 방식으로 공공데이터를 수집하는 코드를 소개하겠습니다. 먼저 요청 URL의 공동부분(main)과 조회항목(이 예제에서는 ‘물품’)을 설정하고, API 인증키는 key에 할당합니다. 그리고 요청 메시지 명세에 있는 나머지 항목들을 순서대로 정리하여 URL을 조립해보겠습니다.
# URL의 공통부분을 설정합니다.
main <- 'http://apis.data.go.kr/1230000/ScsbidInfoService/'
# 여러 항목 중 '물품'을 지정합니다.
item <- 'getScsbidListSttusThng'
# API 인증키(ServiceKey)를 key에 할당합니다.
key <- '여기에 인증키를 복사해서 붙여넣습니다'
# 한 페이지 당 출력할 건수(numOfRows)를 지정합니다.
rows <- 2
# 페이지 번호(pageNo)를 설정합니다.
page <- 1
# 조회구분(inqryDiv)을 설정합니다.
inqry <- 1
# 조회시작일시(inqryBgnDt)를 설정합니다.
bgnDate <- 20180101
# 조회종료일시(inqryEndDt)를 설정합니다.
endDate <- 20180131
# 이제 url을 조립합니다.
# 이 때 요소를 묶어주는 구분자(?, &)를 주의깊게 확인하기 바랍니다!
url <- str_c(main,
item,
str_c('?ServiceKey=', key),
str_c('&numOfRows=', rows),
str_c('&pageNo=', page),
str_c('&inqryDiv=', inqry),
str_c('&inqryBgnDt=', bgnDate),
str_c('&inqryEndDt=', endDate)
)
# 조립한 url을 출력합니다.
cat(url)
각자의 인증키를 넣은 url을 조립했으면 출력된 결과를 복사해서 웹브라우저 주소창에 붙여넣기 해보겠습니다. 그러면 아래와 같은 이미지가 보일 것입니다. 이 형태가 XML입니다. XML은 HTML과 비슷해보이지만 사용자 입장에서는 필요한 데이터만 군더더기 없이 깔끔하게 제공되기 때문에 HTML보다 다루기 쉽다는 장점이 있습니다.

위 이미지의 맨 아래를 보면 전체 건수가 4,257건(2018년 4월 5일 재실행 기준)임을 알 수 있습니다. 그리고 현재 2건의 데이터가 화면에 보이며, 그 2건은 <item> 태그로 묶여서 각각 18개의 세부 항목이 제공되고 있습니다.
그럼 이 url로 요청하고 응답받은 XML을 정리하는 방법에 대해 알려드리겠습니다. 간단하게 GET() 함수를 이용하여 요청하면 됩니다.
# 필요 패키지를 불러옵니다.
library(httr)
library(rvest)
library(dplyr)
library(stringr)
library(magrittr)
# url로 요청합니다.
resp <- GET(url)
# 응답 상태코드를 확인합니다.
status_code(resp)
## [1] 200
응답 상태코드가 정상(200)입니다. 응답받은 resp 객체에서 관심 있는 element를 확인해보면 낙찰리스트 각 건들이 body > items > item의 하위 element로 제공되고 있습니다. 따라서 <item> 단위로 데이터를 정리하면 됩니다. 에시로 입찰공고번호(bidNtceNo)만 추출해보면 다음과 같습니다.
# 입찰공고번호(bidNtceNo)만 추출합니다.
read_xml(resp) %>%
xml_nodes('item') %>%
xml_node('bidNtceNo') %>%
xml_text()
## [1] "20171233674" "20171232329"
위에서 보면 알 수 있듯이 18개 항목 중 필요한 부분만 수집할 수 있습니다. 이 과정을 좀 더 간단하게 하기 위해 위 코드에서 첫 두 줄을 실행하여 items에 할당하기로 합니다. 그리고 아래 두 줄을 사용자 정의 함수로 만들면 코드를 보다 간결하게 만들 수 있습니다.
# 반복되는 부분을 items 객체에 할당합니다.
items <- resp %>% read_xml() %>% xml_nodes('item')
# 필요 항목만 추출하는 사용자 정의 함수를 생성합니다.
getXmlText <- function(x, var) {
result <- x %>% xml_node(var) %>% xml_text()
return(result)
}
이제 새로 만든 사용자 정의 함수의 x 인자에는 items, var 인자에는 bidNtceNo 같은 태그를 (따옴표로 씌워서) 할당하면 해당 태그에 속한 텍스트를 벡터로 얻을 수 있습니다.
# 사용자 정의 함수로 텍스트 데이터 얻기 예제를 실행합니다.
입찰공고번호 <- getXmlText(items, 'bidNtceNo')
# 결과를 확인합니다.
print(입찰공고번호)
## [1] "20171233674" "20171232329"
이렇게 얻은 각각의 텍스트 벡터들을 묶어 하나의 데이터프레임을 만들어 보겠습니다.
# 데이터프레임으로 정리합니다.
df <- data.frame(
공고번호 = getXmlText(items, 'bidNtceNo'),
입찰공고명 = getXmlText(items, 'bidNtceNm'),
참가업체수 = getXmlText(items, 'prtcptCnum'),
낙찰업체명 = getXmlText(items, 'bidwinnrNm'),
사업자번호 = getXmlText(items, 'bidwinnrBizno'),
대표자명 = getXmlText(items, 'bidwinnrCeoNm'),
업체주소 = getXmlText(items, 'bidwinnrAdrs'),
전화번호 = getXmlText(items, 'bidwinnrTelNo'),
낙찰금액 = getXmlText(items, 'sucsfbidAmt')
)
위와 같이 함으로써 한 페이지에 보이는 XML을 데이터프레임 형태로 저장할 수 있습니다.
만약 전체 건을 모두 수집하려면 어떻게 해야 할까요? url 요소 중 한 페이지 결과 수를 1,000으로 다시 지정하고 페이지 번호를 1~5까지 순환하며 반복실행하면 간단하게 해결될 것입니다.
그런데 기왕이면 가능한 모든 것을 자동화하도록 해보겠습니다. 일단 전체 제공 건수를 모른다고 가정하고 이 숫자를 확인한 후 페이지 수를 계산하는 코드를 만들어 봅시다.
# 전체 건수를 확인합니다.
totalCnt <- resp %>%
read_xml() %>%
xml_node('totalCount') %>%
xml_text() %>%
as.numeric()
# 전체 건수를 출력하여 확인합니다.
print(totalCnt)
## [1] 4257
# 한 페이지당 노출 건수를 재지정합니다.
rows <- 1000
# 한 페이지당 1,000개 노출 시 필요 페이지 수를 계산합니다.
# ceiling()는 올림된 수를 반환하는 함수입니다.
pages <- ceiling(totalCnt / rows)
# 페이지수를 출력하여 확인합니다.
print(pages)
## [1] 5
이제 마지막으로 최종 결과 객체를 빈 데이터 프레임으로 생성한 후, rbind() 함수를 이용하여 행 기준으로 추가해주면 끝입니다.
# 순환 함수 실행에 앞서 최종 결과 객체를 생성합니다.
compList <- data.frame()
# 순환 함수를 실행합니다.
for (i in 1:pages) {
# url 조립. 페이지 부분을 i로 변경해야 합니다!
url <- str_c(
main,
item,
str_c('?ServiceKey=', key),
str_c('&numOfRows=', rows),
str_c('&pageNo=', i),
str_c('&inqryDiv=', inqry),
str_c('&inqryBgnDt=', bgnDate),
str_c('&inqryEndDt=', endDate)
)
# url로 요청합니다.
resp <- GET(url)
# 반복되는 부분을 items 객체에 할당합니다.
items <- resp %>% read_xml() %>% xml_nodes('item')
# 데이터 프레임으로 정리합니다.
df <- data.frame(
공고번호 = getXmlText(items, 'bidNtceNo'),
입찰공고명 = getXmlText(items, 'bidNtceNm'),
참가업체수 = getXmlText(items, 'prtcptCnum'),
낙찰업체명 = getXmlText(items, 'bidwinnrNm'),
사업자번호 = getXmlText(items, 'bidwinnrBizno'),
대표자명 = getXmlText(items, 'bidwinnrCeoNm'),
업체주소 = getXmlText(items, 'bidwinnrAdrs'),
전화번호 = getXmlText(items, 'bidwinnrTelNo'),
낙찰금액 = getXmlText(items, 'sucsfbidAmt')
)
# 행 기준으로 추가합니다.
compList <- rbind(compList, df)
}
생성된 객체의 데이터 구조를 확인하겠습니다.
# 데이터 구조를 확인합니다.
str(object = compList)
## 'data.frame': 4257 obs. of 9 variables:
## $ 공고번호 : chr "20171233674" "20171232329" "20171219328" "20171213601" ...
## $ 입찰공고명: chr "2018년 본청 공용차랑 유류 단가계약" "2018년도 보건환경연구원북부지원 실험분석용 특수가스 단가계약" "2018학년도 국제고등학교 교복(동복,하복)학교주관구매업체 선정입찰(2단계경쟁)공고" "2018학년도 광주제일고등학교 교복(동복, 하복) 학교주관구매 입찰 공고" ...
## $ 참가업체수: chr "2" "7" "2" "2" ...
## $ 낙찰업체명: chr "대창주유소" "동서산업가스" "스마트학생복서방,일곡점" "런던베이직(북구점)" ...
## $ 사업자번호: chr "4331200178" "7280200290" "4090354378" "4091208503" ...
## $ 대표자명 : chr "박병창" "손민호" "이병식" "이천호" ...
## $ 업체주소 : chr "경상북도 예천군 예천읍 충효로 154 대창주유소" "경상북도 영천시 도남공단1길 4-0 (도남동)" "광주광역시 북구 풍향동 496-24" "광주광역시 북구 독립로237번길 22-0 (누문동) 1,2층" ...
## $ 전화번호 : chr "054-654-2085" "054-334-2600" "062-511-1104" "062-526-5657" ...
## $ 낙찰금액 : chr "2849" "1000500" "285500" "280000" ...
이번에 생성한 데이터 프레임이 모두 4,257건과 9개 컬럼을 갖는 것으로 확인되었습니다.
이상으로 Open API를 활용하여 공공데이터를 수집하는 방법에 대해 소개해드렸습니다. 공공데이터 포털 뿐만 아니라 서울데이터광장, 금융감독원 및 한국은행 등 국가기관에서 다양한 데이터를 Open API로 공개하고 있으니 원하는 데이터가 있으면 손쉽게 수집하여 데이터 분석에 활용하시기 바랍니다!
[1] 궁금하신 분은 여기를 방문해 보세요